分布式服务追踪与调用链 Zikpin
分布式服务追踪与调用链系统产生的背景
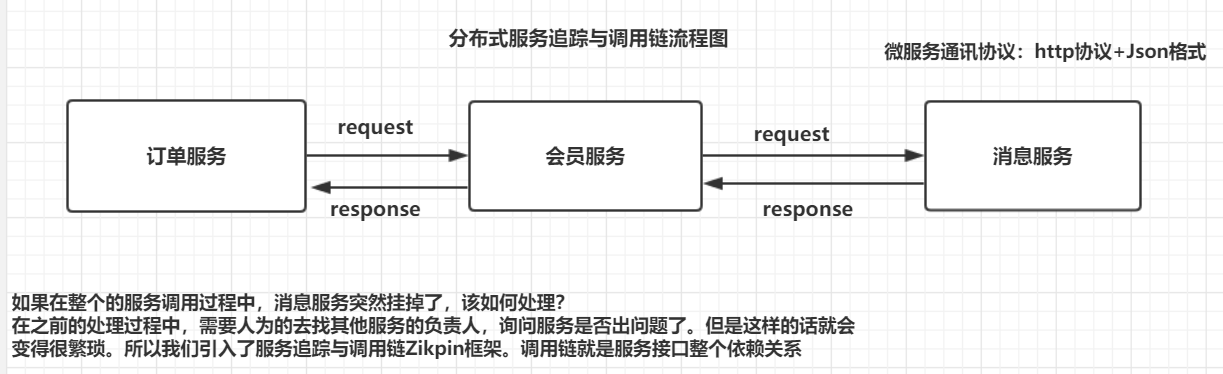
在为服务中,如果服务与服务之间的依赖关系非常复杂,如果某个服务出现了一些问题,很难追查到原因,特别是服务与服务之间调用的时候。
在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变得越来越复杂。一个 HTTP 请求会调用多个不同的微服务来处理返回最后的结果,在这个调用过程中,可能会因为某个服务出现网络延迟过高或发送错误导致请求失败,这个时候,对请求调用的监控就显得尤为重要了。Spring Cloud Sleuth 提供了分布式服务链路监控的解决方案
服务与服务之间调用关系 链路指的:一串联多个服务组成一个流程 调用链关系
SpringCloud Zipkin 与Sleuth
Zipkin 是一个开放源代码分布式的跟踪系统,由Twitter公司开源,它致力于收集服务的定时数据,以解决微服务架构中的延迟问题,包括数据的收集、存储、查找和展现。 每个服务向zipkin报告计时数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。 zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到; 链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
Spring Cloud Sleuth可以结合Zipkin,将信息发送到Zipkin,利用Zipkin的存储来存储信息,利用Zipkin Ui来展示数据。
搭建Zipkin服务追踪系统
在 Spring Boot 2.0 版本之后,官方已不推荐自己搭建定制了,而是直接提供了编译好的 jar 包。
注意:zipkin官网已经提供定制了,使用官方jar运行即可。
启动方式:
默认端口号启动zipkin服务
java –jar zipkin.jar 默认端口号; 9411
访问地址:http://127.0.0.1:9411/zipkin/
指定端口号启动8080启动zipkin服务
java -jar zipkin.jar --server.port=8080
访问地址:http://192.168.18.220:8080
指定访问rabbitmq 启动
java -jar zipkin.jar --zipkin.collector.rabbitmq.addresses=127.0.0.1
搭建Zipkin集成RabbitMQ异步传输
1、启动RabbitMQ
2、启动Zipkin(自动会创建一个Zipkin 队列)
3、启动ZipkinClient以队列形式异步传输
服务跟踪原理
为了实现请求跟踪,当请求发送到分布式系统的入口端点时, 只需要服务跟踪框架为该请求创建一个唯的跟踪标识, 同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识, 直到返回给请求方为止,这个唯一标识就是前 文中提到的Trace ID。通过Trace ID的记录,我们就能将所有请求过程的日志关联起来。 为了统计各处理单元的时间延迟,当请求到达各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一 标识来标记它的开始、 具体过程以及结束,该标识就是前文中提到的Span ID。对于每个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含一些其他元数据, 比如事件名称、请求信息等
TranceId作用是整个微服务调用链过程中保证唯一。
Spanid记录每次一请求。
在微服务中,TranceId与Spanid会放在请求头中进行传递。Trancdid 每次请求都是一样的,而Spanid 每请求一次就会重新生成一个。一个TranceId由多个Spanid组合起来,获取到整个微服务调用依赖关系。
SpringCloud2.x新知识介绍

官网:https://zipkin.io/pages/quickstart.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号