揭秘 水平拆分 和 垂直拆分 的区别
41.数据库id自增解决方案
数据库集群的情况下,如果自动增长id产生重复的话,如何解决?
1.采用UUID形式设置为id。
缺点:无规则,没有顺序。如果是Oracle数据库,推荐使用。
2.设置步长。缺点:不利于后期服务器的扩容。
在数据库集群环境下,默认自增方式存在问题,因为都是从1开始自增,可能会存在重复,应该设置每台节点自增步长不同。
查询自增的步长
SHOW VARIABLES LIKE 'auto_increment%'
修改自增的步长
SET @@auto_increment_increment=10;
修改起始值
SET @@auto_increment_offset=5;
假设有两台mysql数据库服务器
节点①自增 1 3 5 7 9 11 ….
节点②自增 2 4 6 8 10 12 ….
缺点:在最开始设置好了每台节点自增方式步长后,确定好了mysql集群数量后,无法扩展新的mysql,不然生成步长的规则可能会发生变化。
假设有三台MySql服务器集群,三台服务器分别的起始值和步长为多少?
起始值为 1 2 3.,步长为3.
其它方案:使用Redis、雪花算法。
使用Redis:是单线程,如果是多线程的情况下,会产生线程阻塞,不推荐。如果是量小,不是特别多的情况下,可以使用redis和雪花算法。
2. 数据库分表分库策略
1. 在数据库分表分库原则中,遵循二个设计理论 垂直拆分、水平拆分。垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。
垂直拆分:就是根据不同的业务进行拆分的,拆分成不同的数据库,比如会员数据库、订单数据库、支付数据库、消息数据库等,垂直拆分在大型电商项目中使用比较常见。
优点:拆分后业务清晰,拆分规则明确,系统之间整合或扩展更加容易。
缺点:部分业务表无法join,跨数据库查询比较繁琐(必须通过接口形式通讯(http+json))、会产生分布式事务的问题,提高了系统的复杂度。举栗子:不可能出现,在订单服务中,订单服务直接连接会员服务的数据库这种情况。
水平拆分:把同一张表中的数据拆分到不同的数据库中进行存储、或者把一张表拆分成 n 多张小表。
相对于垂直拆分,水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中 的某些行切分到一个数据库,而另外的某些行又切分到其他的数据库中,主要有分表,分库两种模式 该方式提高了系统的稳定性跟负载能力,但是跨库join性能较差。
使用MyCat实现水平分片策略
MyCat支持10种分片策略
1、求模算法
2、分片枚举
3、范围约定
4、日期指定
5、固定分片hash算法
6、通配取模
7、ASCII码求模通配
8、编程指定
9、字符串拆分hash解析
详细:http://www.mycat.io/document/mycat-definitive-guide.pdf
使用MyCat实现水平分片策略
分片枚举
分片枚举算法:就是根据不同的枚举(常量),进行分类存储的。举栗子:有些业务需要按照省份或区县来做保存,而全国的省份区县固定的,这类业务使用这一规则。
环境搭建:
1.案例步骤: 创建数据库userdb_1 、 userdb_2、userdb_3
2.修改partition-hash-int.txt 规则 sahgnhai=0、beijing=1、shenzhen=2,定义枚举(地区) 每个地区指定的数据库存放位置。
根据地区进行分库 上海数据库、北京数据库 、深圳数据库。

求模算法
求摸法分片,根据id进行十进制求摸运算,运算结果为分区索引
注意:数据库节点分片数量无法更改。 和ES集群非常相似的。
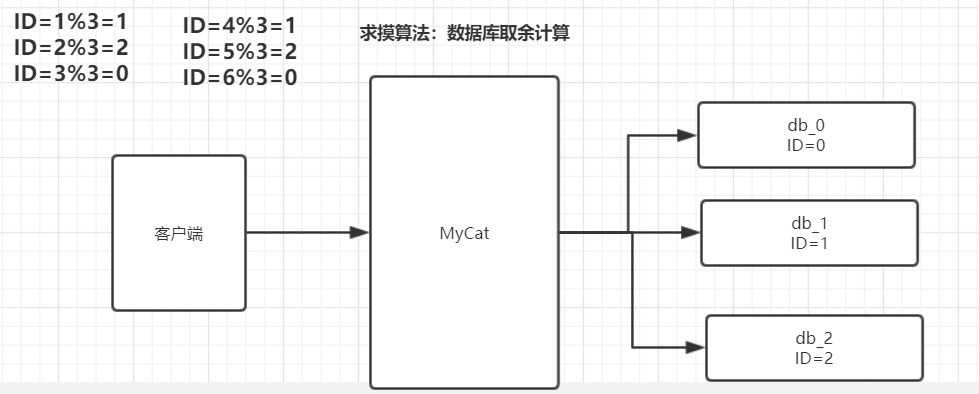
MyCat如何实现通过一个sql 就可以查询出来所有的表的数据
举栗子:在mycat中执行 select * from user_info; 这个简单的sql查询可以查询出来对应所有分表的数据。
原因:mycat中的 一个 sql 语句,相当于三个sql 语句在不同的数据表都进行查询。
select * from db1_user_info;
select * from db2_user_info;
select * from db3_user_info;
然后三条语句查询出来的结果进行组装在返回给mycat。
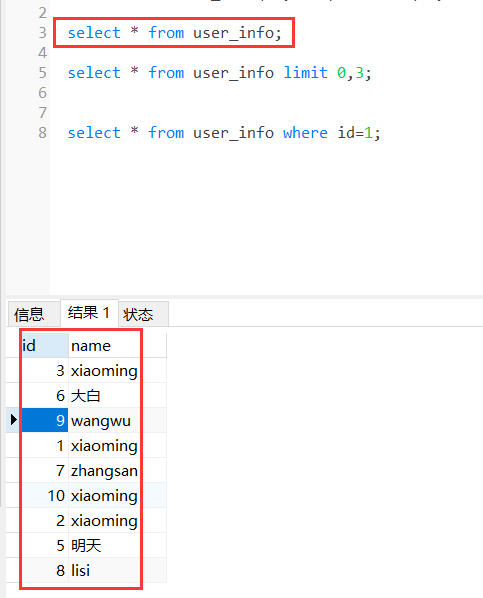
MyCat分片字段的查询
select * from user_info where id=1;
1.如果是根据MyCat的分片字段作为条件进行查询,则只会有一条匹配到对应分片字段的数据表中执行sql语句查询。
2.如果查询的条件是非分片字段,则会在每个分表中都会执行sql语句。如果查询条件不是根据分片字段作为条件去查询,不建议使用mycat。
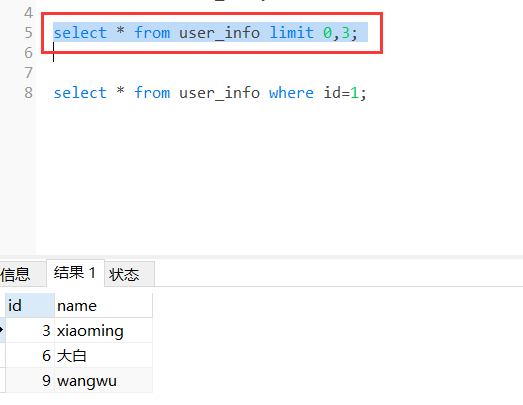
MyCat分页查询的原理
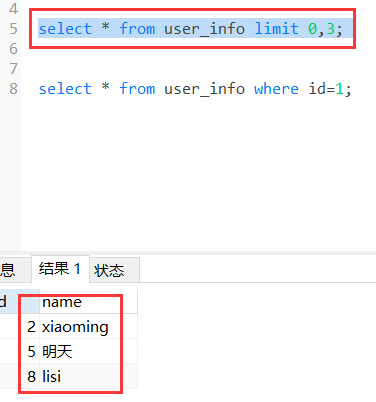
select * from user_info limit 0,3;
执行分页查询语句,会在每一个分表中都执行该sql语句,但是mycat 返回的结果就是从这三个返回的结果集中随机的抽取一对进行数据显示。
效果图如下,查询所有的数据如下:
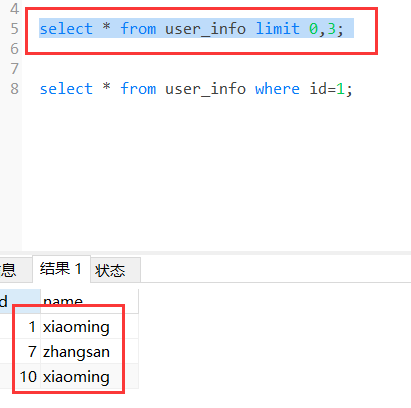
分页查询sql语句,下面是同一条sql 执行三次 查询出来的结果,查询出来的结果是随机的,可能执行三次查询出来的结果都一样的。
数据库集群产生的问题
1.数据库关联查询的问题(水平拆分导致的)
2.数据同步的问题
3.id自增的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号