Kafka 消息中间件
kafka简介与应用场景
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
注意:Kafka并没有遵循JMS规范,它只提供了发布和订阅通讯方式。
kafka优点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对 partition 进行consume操作;
- 可扩展性:kafka集群支持热扩展 ;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
- 高并发:支持数千个客户端同时读写;
Kafka的使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm - 事件源
kafka的相关名称
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群;
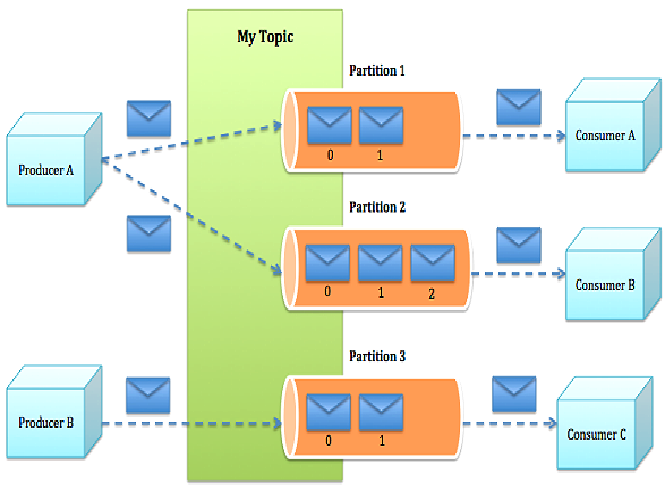
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发;
massage: Kafka中最基本的传递对象;
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列;
Segment:partition物理上由多个segment组成,每个Segment存着message信息;
Producer : 生产者,生产message发送到topic;
Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费;
Consumer Group:消费者组,一个Consumer Group包含多个consumer;
Offset:偏移量,理解为消息partition中的索引即可;
Kafka存储策略
1)kafka以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,有多个segment组成。
2)每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3)每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4)发布者发到某个topic的消息会被均匀的分布到多个partition上(或根据用户指定的路由规则进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
kafka架构原理
kafka高可用集群环境搭建
1.每台服务器上安装jdk1.8环境
2.安装Zookeeper集群环境
3.安装kafka集群环境
4.运行测试
kafka中文官网: http://kafka.apachecn.org/quickstart.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号