
“达观杯”文本分类--baseline
结合tfidf权重,对“达观杯”提供的文本,进行文本分类,作为baseline,后续改进均基于此。
1.比赛地址及数据来源
2.代码及解析
# -*- coding: utf-8 -*- """ @简介:tfidf特征/ SVM模型 @成绩: 0.77 """ #导入所需要的软件包 import pandas as pd from sklearn.svm import LinearSVC from sklearn.feature_extraction.text import TfidfVectorizer print("开始...............") #==================================================================================================================== # @代码功能简介:从硬盘上读取已下载好的数据,并进行简单处理 # @知识点定位:数据预处理 #==================================================================================================================== df_train = pd.read_csv('./data/train_set.csv') # 数据读取 df_test = pd.read_csv('./data/test_set.csv') # 观察数据,原始数据包含id、article(原文)列、word_seg(分词列)、class(类别标签) df_train.drop(columns=['article', 'id'], inplace=True) # drop删除列 df_test.drop(columns=['article'], inplace=True) #========================================================== # @代码功能简介:将数据集中的字符文本转换成数字向量,以便计算机能够进行处理(一段文字 ---> 一个向量) # @知识点定位:特征工程 #========================================================== vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9) ''' ngram_range=(1, 2) : 词组长度为1和2 min_df : 忽略出现频率小于3的词 max_df : 忽略在百分之九十以上的文本中出现过的词 ''' vectorizer.fit(df_train['word_seg']) # 构造tfidf矩阵 x_train = vectorizer.transform(df_train['word_seg']) # 构造训练集的tfidf矩阵 x_test = vectorizer.transform(df_test['word_seg']) # 构造测试的tfidf矩阵 y_train = df_train['class']-1 #训练集的类别标签(减1方便计算) #========================================================== # @代码功能简介:训练一个分类器 # @知识点定位:传统监督学习算法之线性逻辑回归模型 #========================================================== classifier = LinearSVC() # 实例化逻辑回归模型 classifier.fit(x_train, y_train) # 模型训练,传入训练集及其标签 #根据上面训练好的分类器对测试集的每个样本进行预测 y_test = classifier.predict(x_test) #将测试集的预测结果保存至本地 df_test['class'] = y_test.tolist() df_test['class'] = df_test['class'] + 1 df_result = df_test.loc[:, ['id', 'class']] df_result.to_csv('./results/beginner.csv', index=False) print("完成...............")
3.问题修复
由于提供的数据集较大,一般运行时间再10到15分钟之间,基础电脑配置在4核8G的样子(越消耗内存在6.2G),因此,一般可能会遇到内存溢出的错误。

可限制每次读取的数据量,具体解决办法如下:
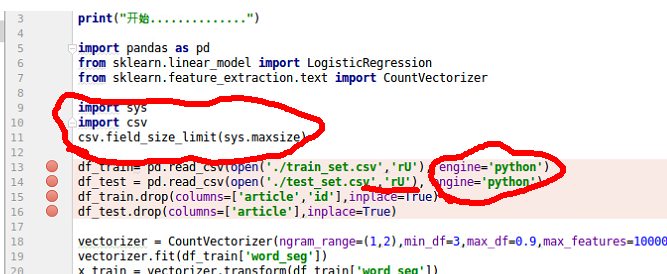
当然,你也可以换一个配置更高的电脑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号