
scrapy的CrawlSpider类
了解CrawlSpider
踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的。因此,可以以此为七点,根据需求修改部分方法,当然也可以实现自己的spider。
官方文档:http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/spiders.html#crawlspider
CrawlSpider的使用
简单使用
创建爬虫文件:scrapy genspider -t crawl "spider_name" "url"
得到如下目录:
其中spider文件夹中的爬虫文件下的内容如下所示:
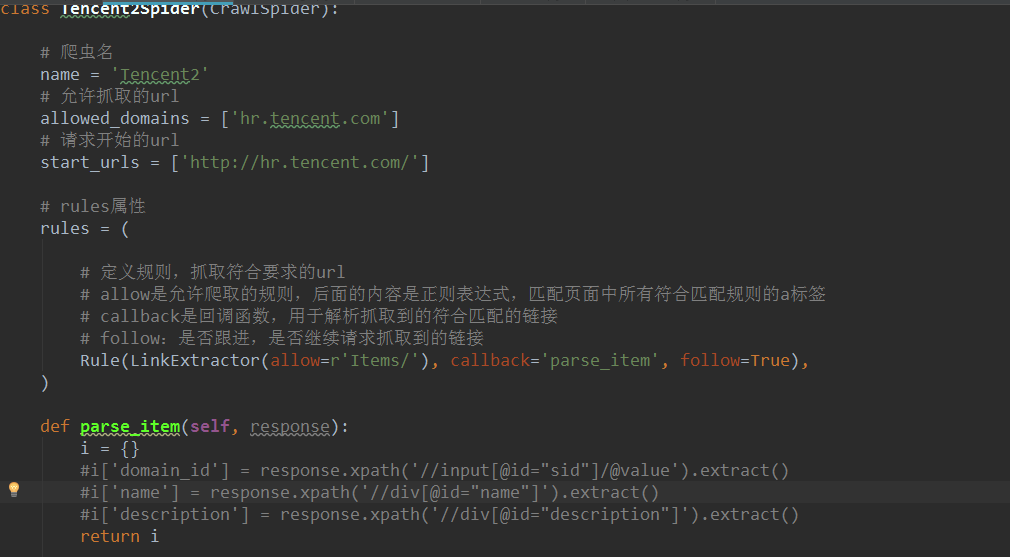
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类中定义了一些规则(rule)来提取跟进link的方便机制,从而爬取的网页中获取link并继续爬取。
方法属性
Name:定义spider的名字
allow_domains:包含了spider允许抓起去的域名列表。
start_url:初始化url列表,当没有指定的url时,spider将从该列表中开始进行爬取。
start_requests(self):该方法返回一个可迭代对象,该对象包含了spider用于抓取的第一个request。
parse(self, resposne):默认的Request对象回调函数,用来处理返回的response,以及生成Items或者Request对象。
使用CralwSpider抓取数据
编写CrawlSpider,抓取腾讯招聘的信息,具体网页分析,见:
http://www.cnblogs.com/pythoner6833/p/9018782.html
具体代码如下:
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from tencent2.items import Tencent2Item, DetailsItem class Tencent2Spider(CrawlSpider): # 爬虫名 name = 'Tencent2' # 允许抓取的url allowed_domains = ['hr.tencent.com'] # 请求开始的url start_urls = ['https://hr.tencent.com/position.php?'] # rules属性 rules = ( # 定义规则,抓取符合要求的url # allow是允许爬取的规则,后面的内容是正则表达式,匹配页面中所有符合匹配规则的a标签 # callback是回调函数,用于解析抓取到的符合匹配的链接 # follow:是否跟进,是否继续请求抓取到的链接 Rule(LinkExtractor(allow=r'start=\d+'), callback='parse_tencent', follow=True), #编写匹配详情页的规则,抓取到详情页的链接后不用跟进 Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+'), callback='parse_detail', follow=False), ) def parse_tencent(self, response): # 获取页面中招聘信息在网页中位置节点 node_list = response.xpath('//tr[@class="even"] | //tr[@class="odd"]') # 遍历节点,进入详情页,获取其他信息 for node in node_list: # 实例化,填写数据 item = Tencent2Item() item['position_name'] = node.xpath('./td[1]/a/text()').extract_first() item['position_link'] = node.xpath('./td[1]/a/@href').extract_first() item['position_type'] = node.xpath('./td[2]/text()').extract_first() item['wanted_number'] = node.xpath('./td[3]/text()').extract_first() item['work_location'] = node.xpath('./td[4]/text()').extract_first() item['publish_time'] = node.xpath('./td[5]/text()').extract_first() yield item def parse_detail(self, response): """ 解析详情页数据 :param response: :return: """ item = DetailsItem() # 从详情页获取工作责任和工作技能两个字段名 item['work_duties'] = ''.join(response.xpath('//ul[@class="squareli"]')[0].xpath('./li/text()').extract()) item['work_skills'] = ''.join(response.xpath('//ul[@class="squareli"]')[1].xpath('./li/text()').extract()) yield item
其他部分,包括items.py和数据保存的pipelines.py里的代码编写和上文中链接里的已解释。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号