
【NLP之文本摘要】5_transformer模型初级探索
背景
Transformer模型是NLP领域一个比较里程碑式的模型。在Transformer之前,从RNN系列到Seq2Seq结构再到PGN模型算是nlp领域的一个阶段;从Transformer之后,nlp模型开启了预训练+微调的新范式;因此,Transformer可以算的上是一个承前启后的模型,对于nlp领域研究具有重要意义。本文主要记录学习transformer模型过程种的一些总体感受、学习思路和笔记等,仅做一个学习记录。
Transformer细节简要
Transformer模型主要由两部分Encoder和Decoder构成;其中Encoder/Decoder可以分为由若干个Block堆叠而成;而每个Block可以分为Attention层、残差网络层、标准化层、线性变换层构成。将在后文做详细说明。
Attention与self-Attention
Attention
Attention机制在前面关于seq2seq系列的文章种已经做了具体说明,此处不做详细的说明,总体思路如下:
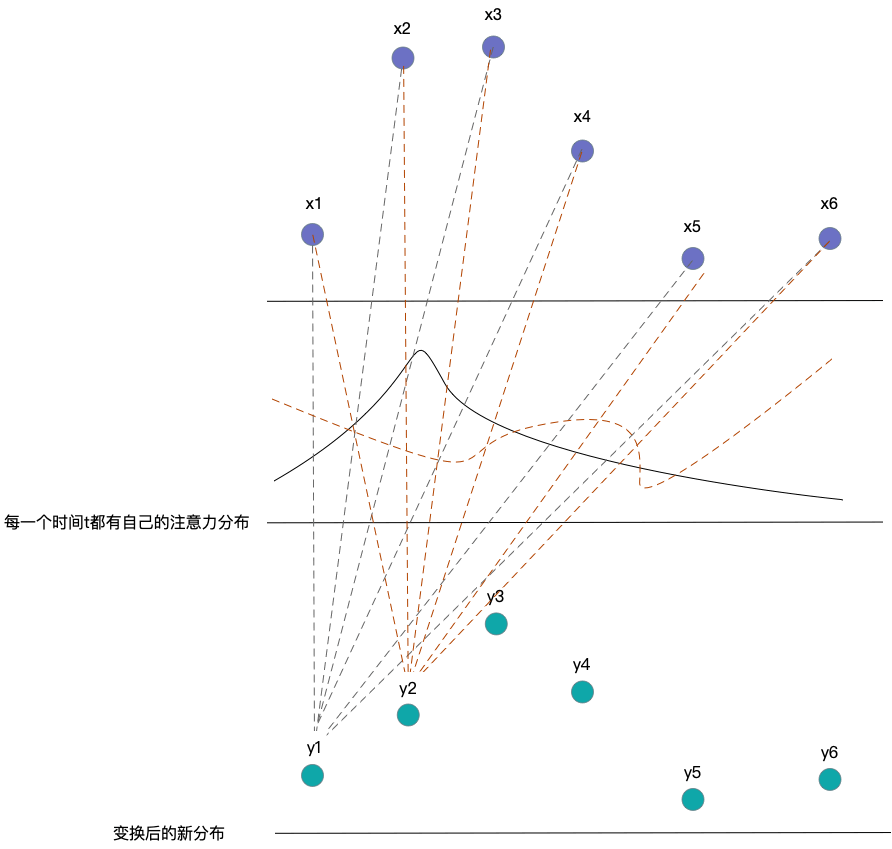
attention的目的在于将原本数据\(x_i\)转化为具备注意力的数据表示\(y_i\),其中\(y_i\)是通过对不同\(x_i\)加权得到,而加权的权重大小就是注意力的分数。数学表示如下:
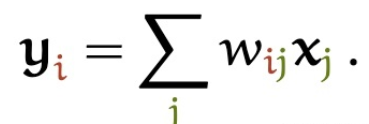
self-Attention
Transformer模型种的注意力机制是一种区别与上述注意力的方法,采用的一种自注意力方式。总体表示还是和上文中的表述一样,不同的是注意力权重的计算方式不同。self-Attention中的\(x_i\)的注意力得分来自每一个\(x_j\)其中{i 可以等于 j}。权重计算如下:
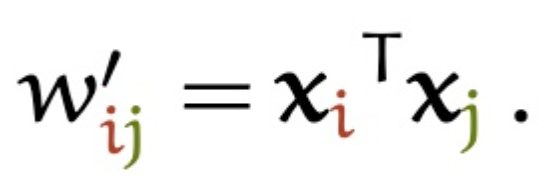
而其他部分的计算基本和Attention相同。
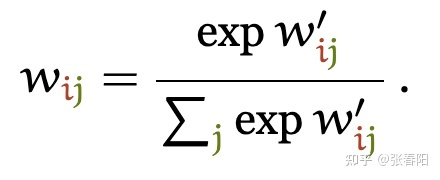
具体计算过程如下:
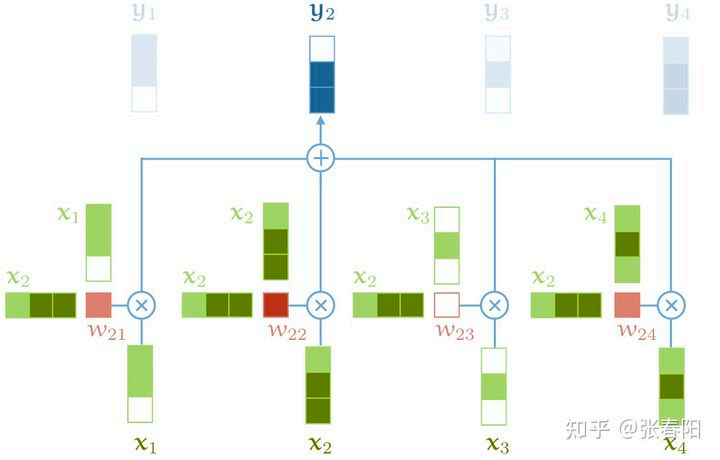
attention和self-attention的差异
简单总结几个重要的区别,以便区分Attention与self-attention在不同任务中的使用方法。在神经网络中,通常来说你会有输入层(input),应用激活函数后的输出层(output),在RNN当中你会有状态(state)。
- attention (AT) 被应用在某一层的时,它更多是被应用在输出或者是状态层上,而当self-attention(SA)更多的实在关注input上。
- Attention (AT) 经常被应用在从编码器(encoder)转换到解码器(decoder)。例如,解码器的神经元会接受一些AT从编码层生成的输入信息。在这种情况下,AT连接的是两个不同的组件(component)--编码器和解码器。但是如果用SA,它就不是关注的两个组件,而是只关注在你应用的那一个组件。那这里他就不会去关注解码器了,比如说在Bert中的使用,就没有解码器。
- SA可以在一个模型当中被多次的、独立的使用(比如说在Transformer中,使用了18次;在Bert当中使用12次)。但是,AT在一个模型当中经常只是被使用一次,并且起到连接两个组件的作用。
- SA比较擅长在一个序列当中,寻找不同部分之间的关系。比如说,在词法分析的过程中,能够帮助去理解不同词之间的关系。AT却更擅长寻找两个序列之间的关系,比如说在翻译任务当中,原始的文本和翻译后的文本。这里也要注意,在翻译任务重,SA也很擅长,比如说Transformer。
- AT可以连接两种不同的模态,比如说图片和文字。SA更多的是被应用在同一种模态上,但是如果一定要使用SA来做的话,也可以将不同的模态组合成一个序列,再使用SA。
- 大部分情况,SA这种结构更加的general,在很多任务作为降维、特征表示、特征交叉等功能尝试着应用,很多时候效果都不错。
为何self-attention能够 work ?
具体参考如下链接:https://zhuanlan.zhihu.com/p/345680792
- 通过词向量与参数矩阵的点乘计算,来模拟得到每个词的词向量与其他词向量的协同信息稀疏矩阵,本质上是对不同词向量的协同信息进行降维建模。
- 通过对参数矩阵的不断训练更新,不断得到更加接近真实协同信息矩阵的参数表示
- 矩阵里面的每个维度的参数的含义是什么,并不能直接得到;但是当按照这种方法求解到的最后的参数时,这些参数都能够描述某种有实际含义的特征。
Transformer中的self-attention
Transformer中self-attention中采用key, query, value模式来进行注意力表示,其计算流程如下。
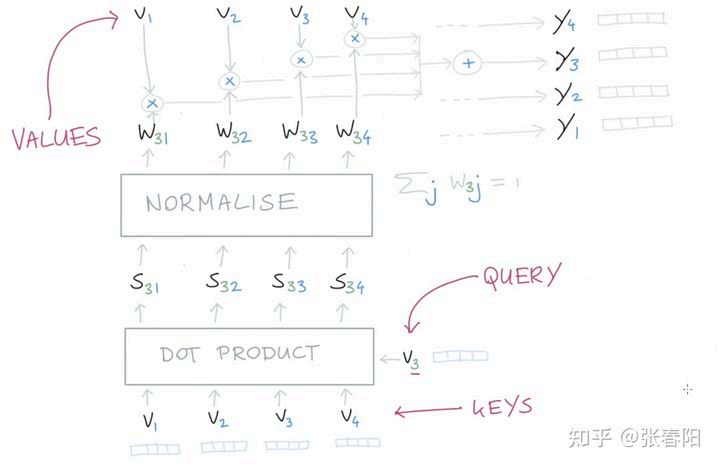
矩阵计算如下:
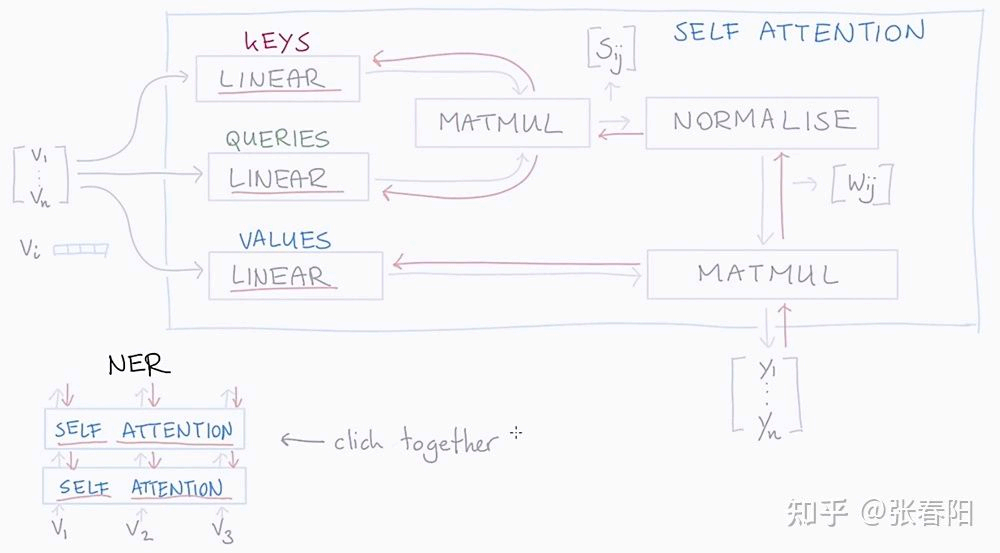
多头注意力Multi-head Attention计算形式如下:
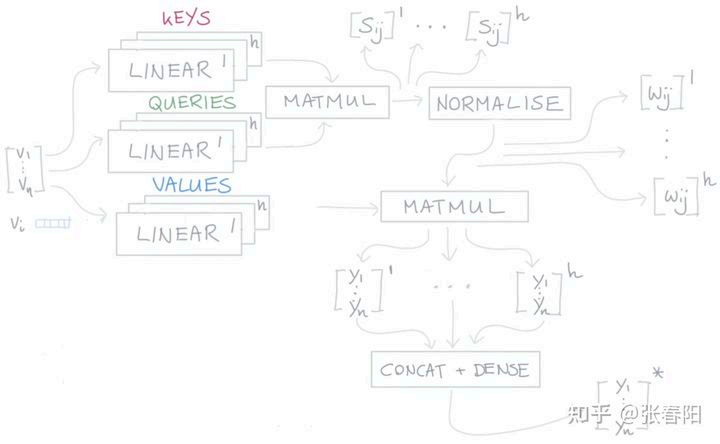
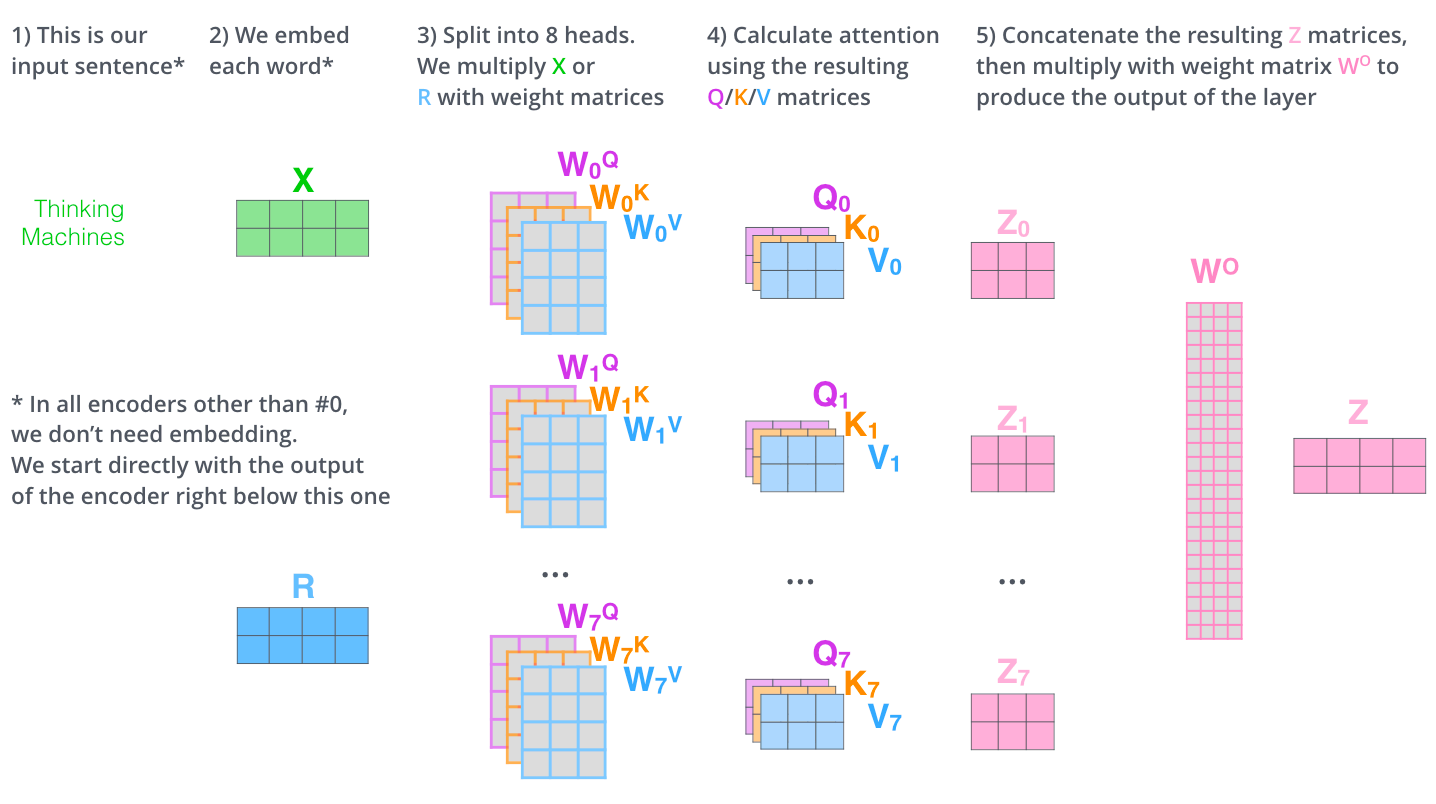
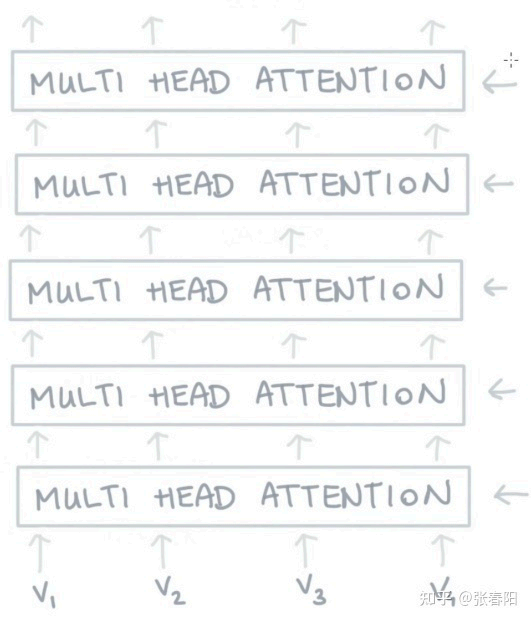
Transformer中多次使用Multi-head Attention,每一层的注意力输出,作为下一层注意力使用的输入。
Transformer中在使用注意力时进行了一定的缩放。原因在于:将每个计算注意力后得到的数值缩放到非饱和区,在防止梯度消失的同时,能够提高学习的效率。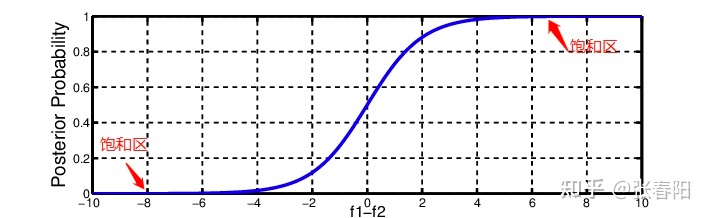
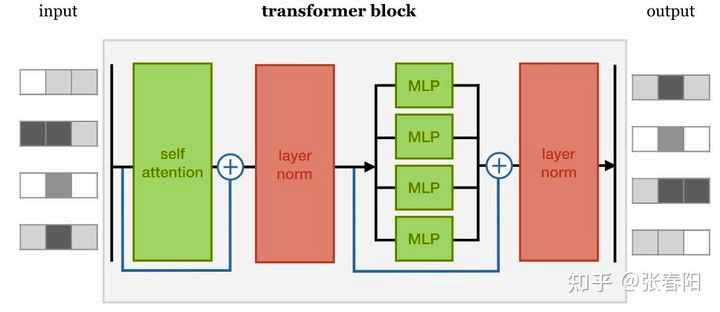
Transformer的Block
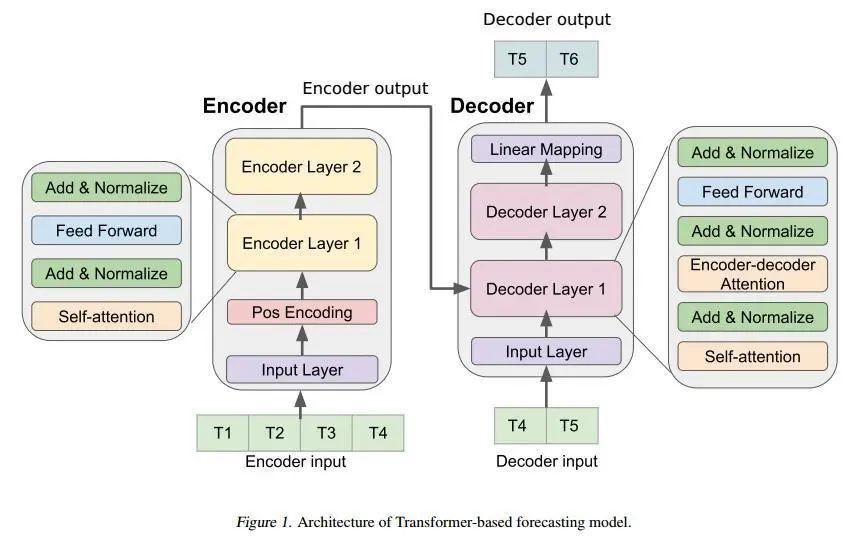
Encoder部分
encoder部分包括几个模块:Pos-Encoding、Attention, Redusal Network、FFN、Layer Norm等几个部分
Position Encoding
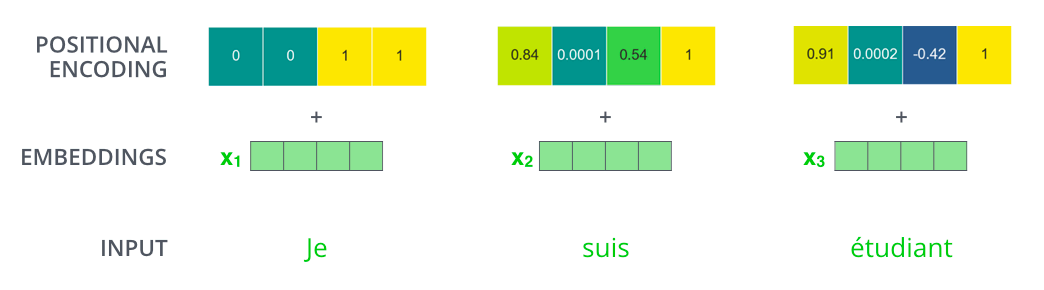
输入部分的Embedding表示由两部分组成:词向量和位置编码向量,两部分向量进行相加。其中位置向量的表示,如下:
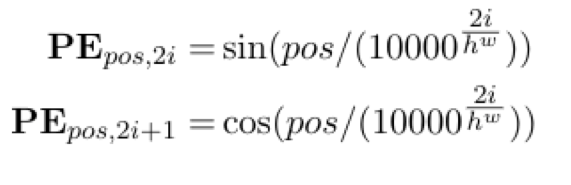
其中,各个参数含义如下:

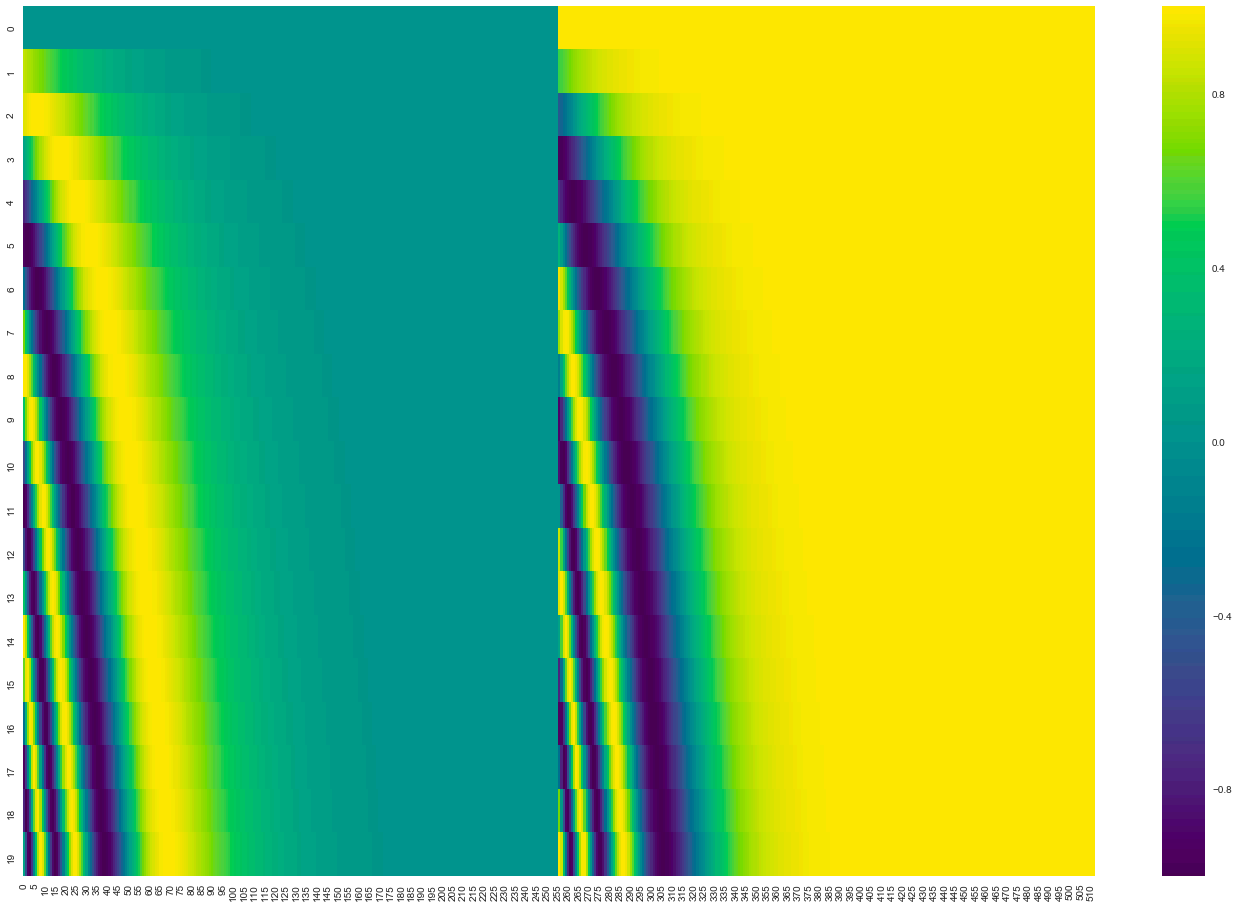
在上述公式的计算下,整体位置向量编码如下:
Residual Network
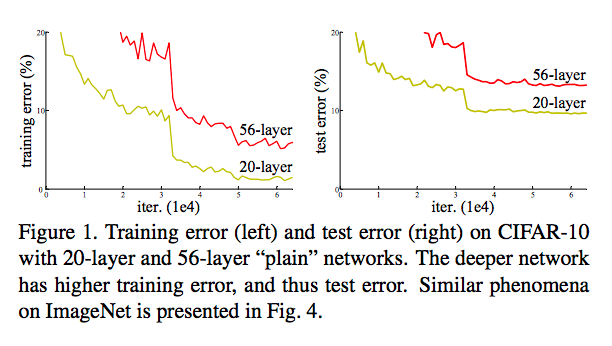
在部分场景中,实验发现网络深度越深,并不一定能带来效果的提升,反而会略有下降;产生这种现象的原始是梯度爆炸/消失之外,还因为每个数据在进行多层次网络表示之后,本身值就很小,导致网络退化。因此,引入了残差网络。残差网络的原理是,在下一层的输入时,输入数据为上一层的输出数据,加上上一层的输入。整体表示如下
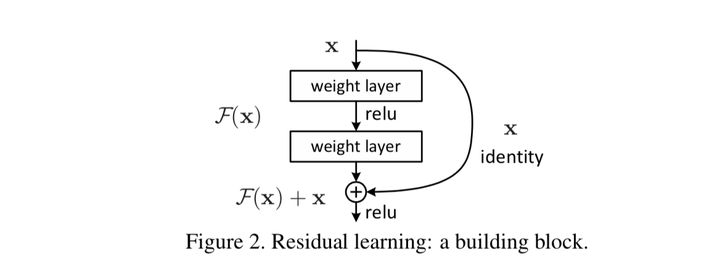
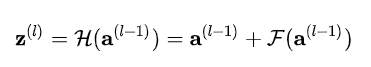
残差⽹络就可以被看作是⼀系列路径集合组装⽽成的⼀个集成模型,这独⽴性和冗余性,使得残差⽹络表现得像⼀个集成模型(ensemble)
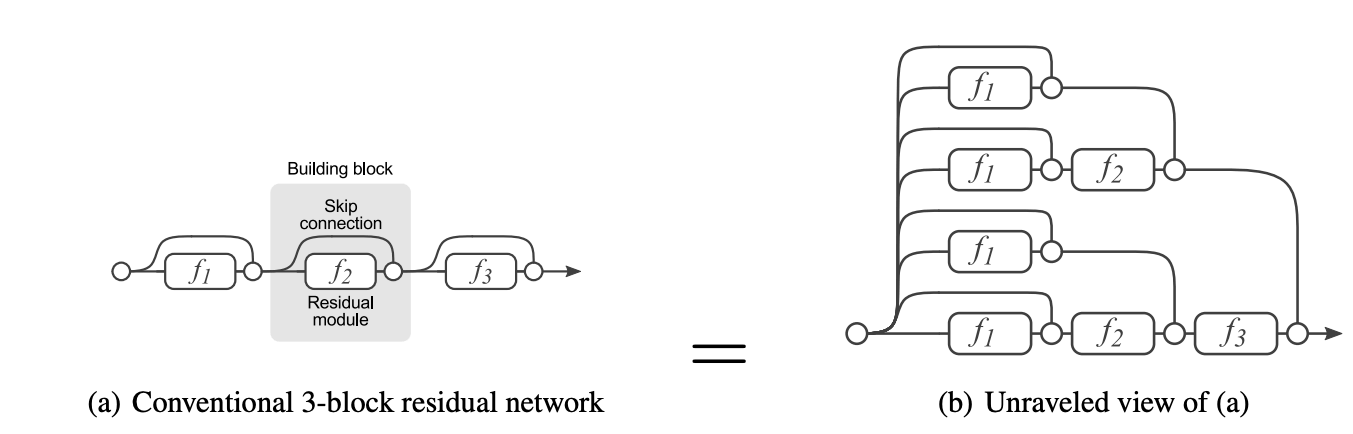
残差网络在transformer结构中的表示如下:
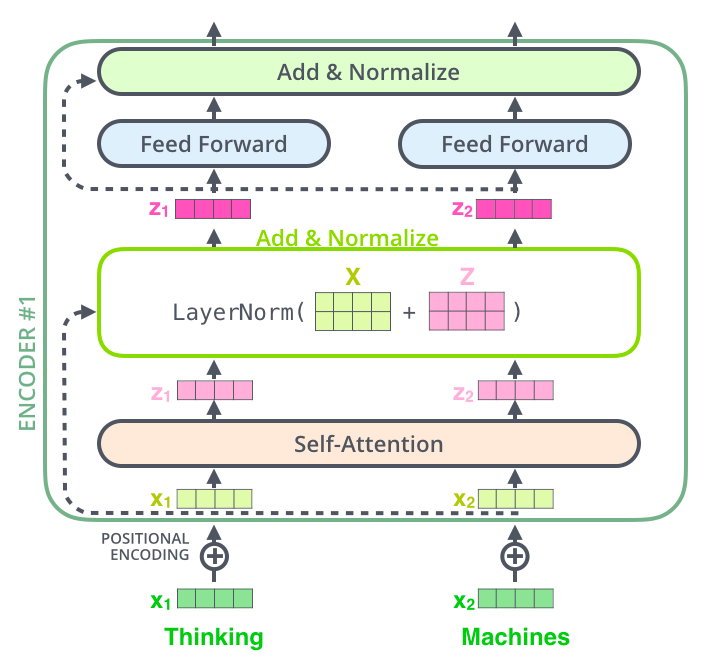
Layer Norm
深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
Google 将这一现象总结为 Internal Covariate Shift,简称 ICS.
所以ICS是什么呢?将每一层的输入作为一个分布看待,由于底层的参数随着训练更新,导致相同的输入分布得到的输出分布改变了。
而在机器学习过程中,要求数据满足独⽴同分布(independent and identically distributed,简称为i.i.d)要求。即数据预处理阶段的"⽩化(whitening)"过程。⽩化⼀般包含两个⽬的:
(1) 去除特征之间的相关性 —> 独⽴;
(2) 使得所有特征具有相同的均值和⽅差 —> 同分布。
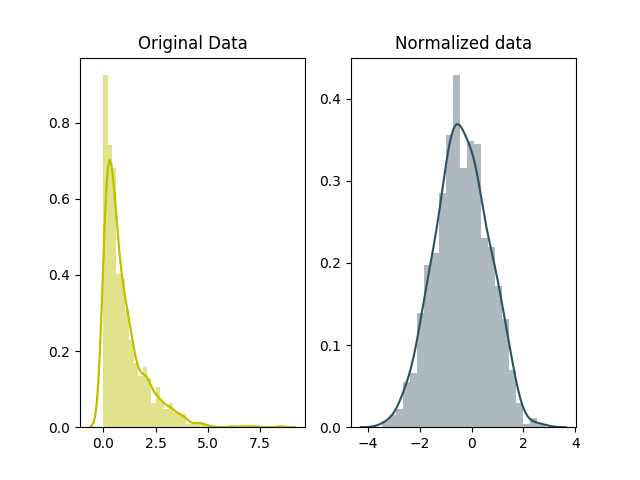
那么,细化到神经网络的每一层间,每轮训练时分布都是不一致,那么相对的训练效果就得不到保障,所以称为层间的covariate shift。
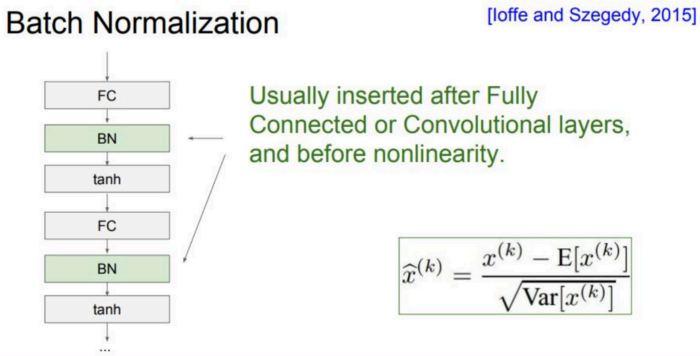
应用BN(Batch Normalization)
BN是指对Batch Size的数据进行一个标准化。
使用BN,在对数据进行标准化后,使其符合固定的数据分布。
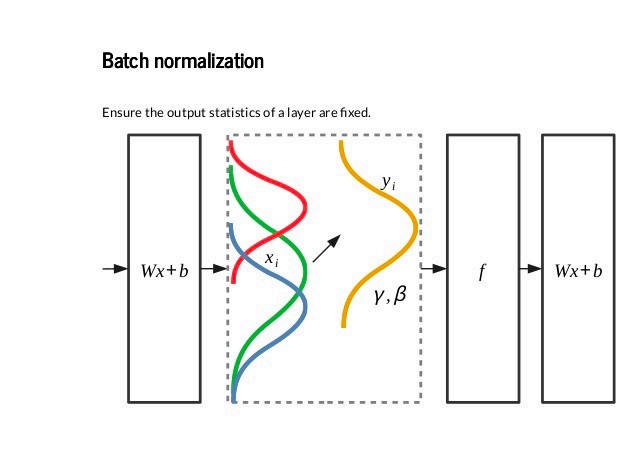
BN ⽐较适⽤的场景是:每个mini-batch ⽐较⼤,数据分布⽐较接近。在进⾏训练之前,要做好充分的 shuffle. 否则效果会差很多。
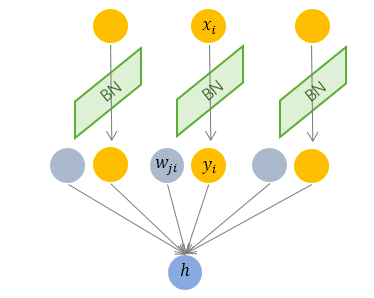
BN标准化操作参数计算如下:
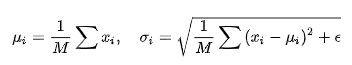
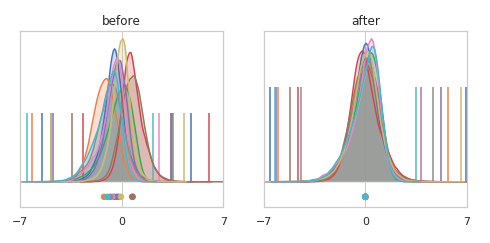
使用BN后,效果大致如下:
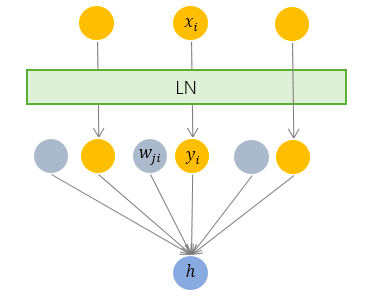
LN(Layer Normalization)
LN 针对单个训练样本进⾏,不依赖于其他数据,因此可以避免 BN 中受 mini-batch数据分布影响的问题,可以⽤于⼩mini-batch场景、动态⽹络场景和 RNN,特别是⾃然语⾔处理领域。此外,LN不需要保存 mini-batch 的均值和⽅差,节省了额外的存储空间。
FFN
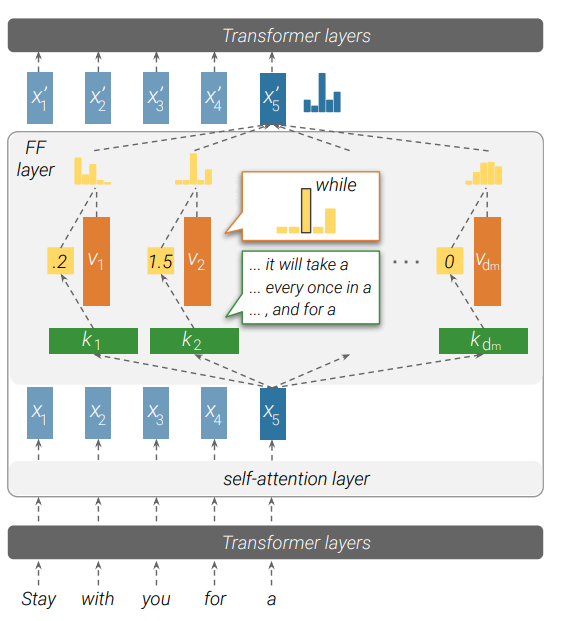
FFN层的作用时进行复杂的非线性变换。到此为止,Transformer中几个核心组件,基本介绍完毕。Transformer中的两个大的部分Encoder/Decoder基本是由这些组件进行堆叠完成。
Decoder
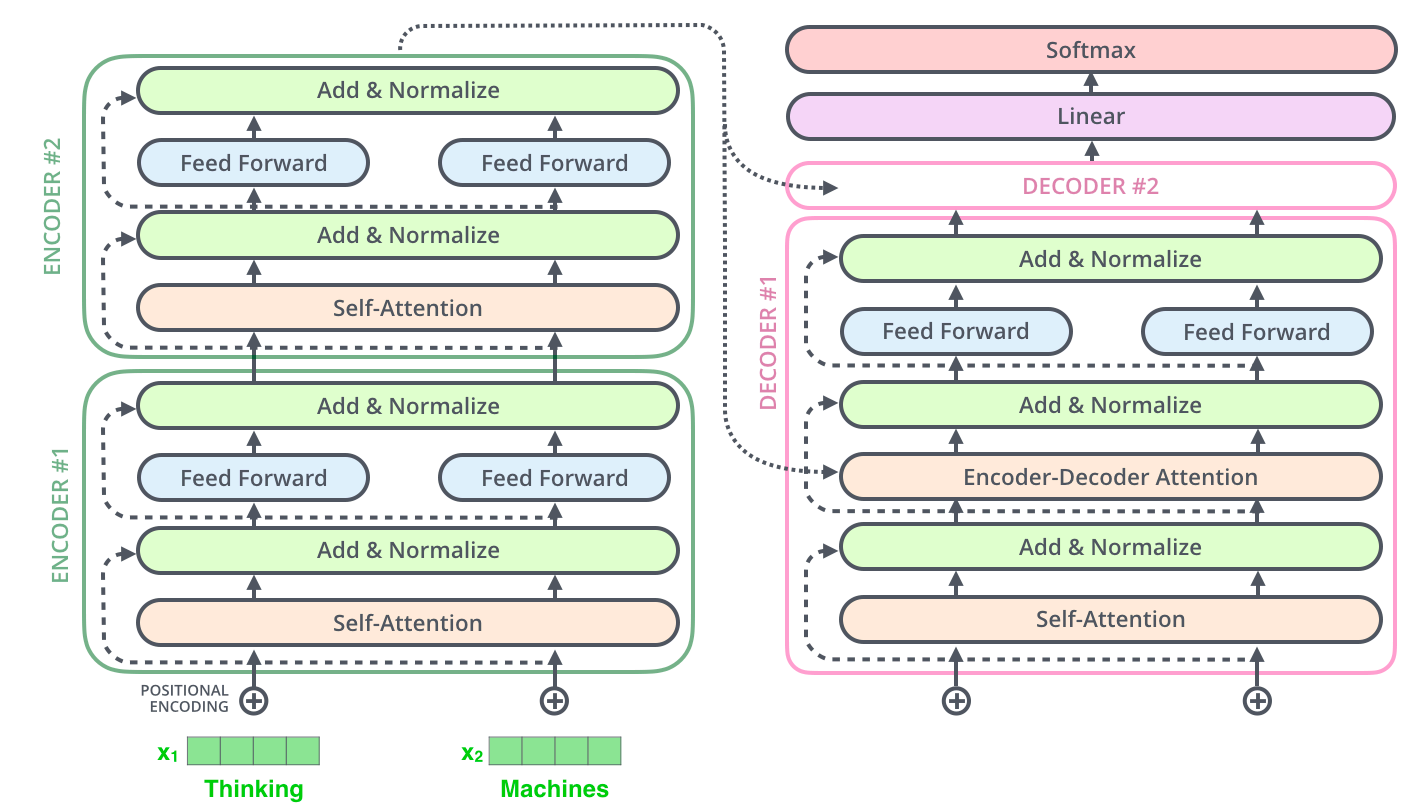
Decoder部分的输入包括Encoder部分的输出,以及部分组件进行堆叠而成。解码过程和Seq2Seq基本相同。
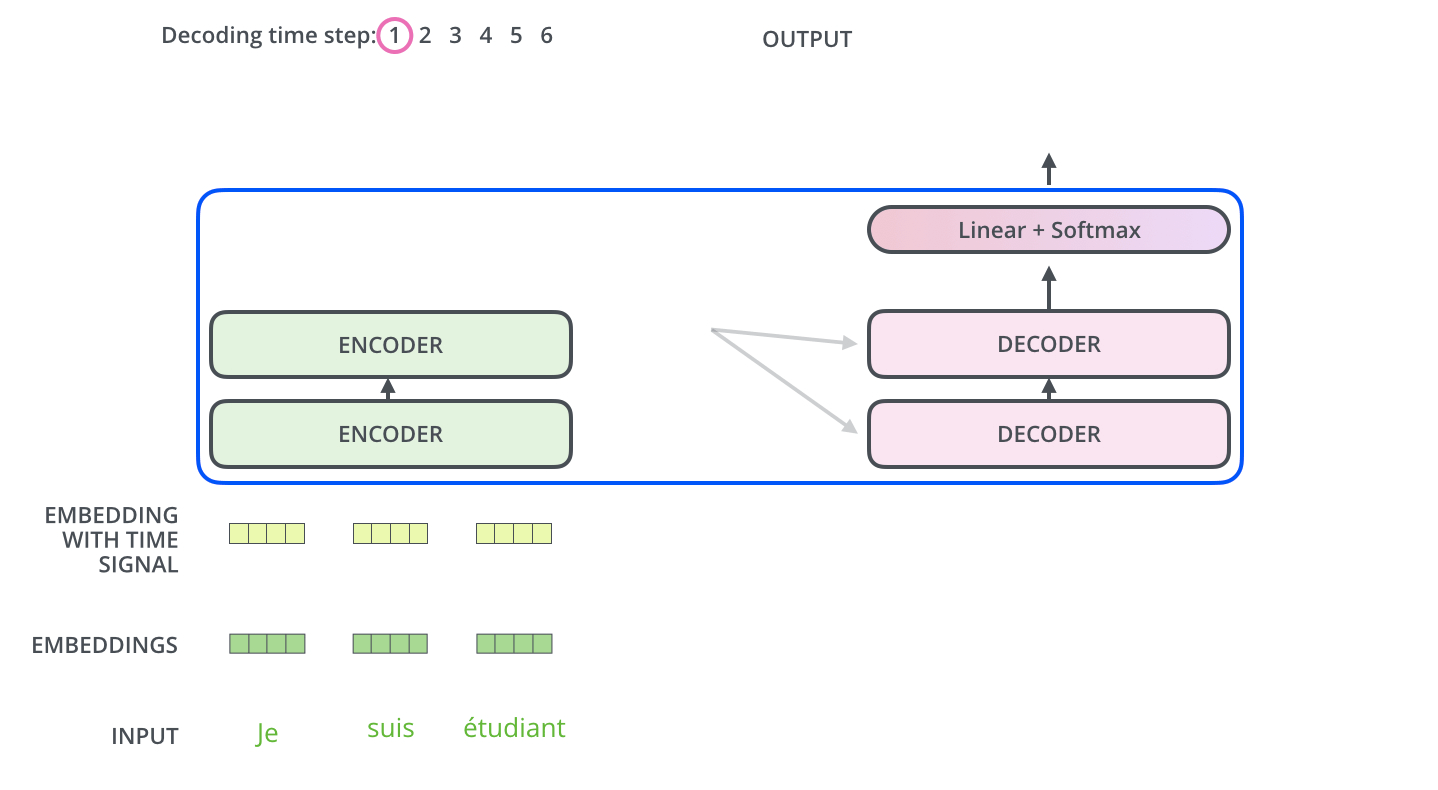
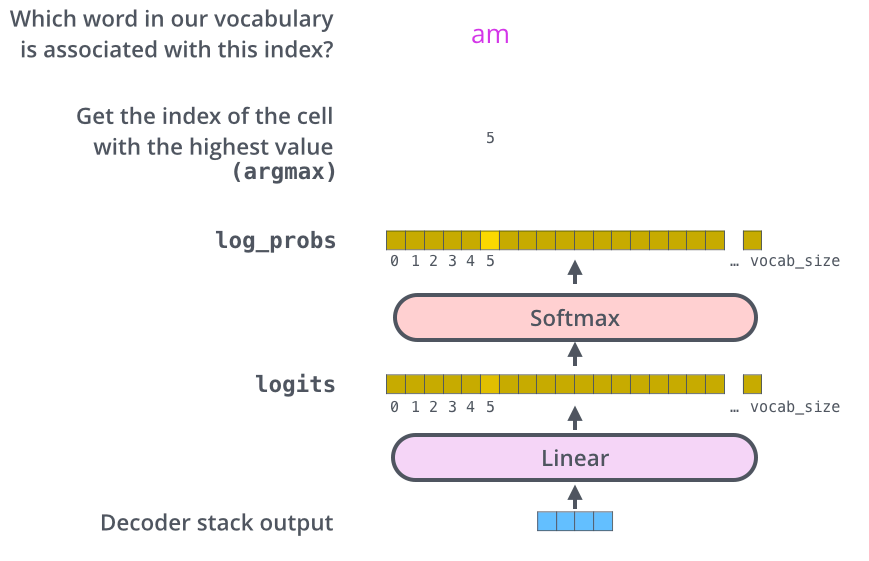
Encoder输出,作为Decoder每一层的输入。
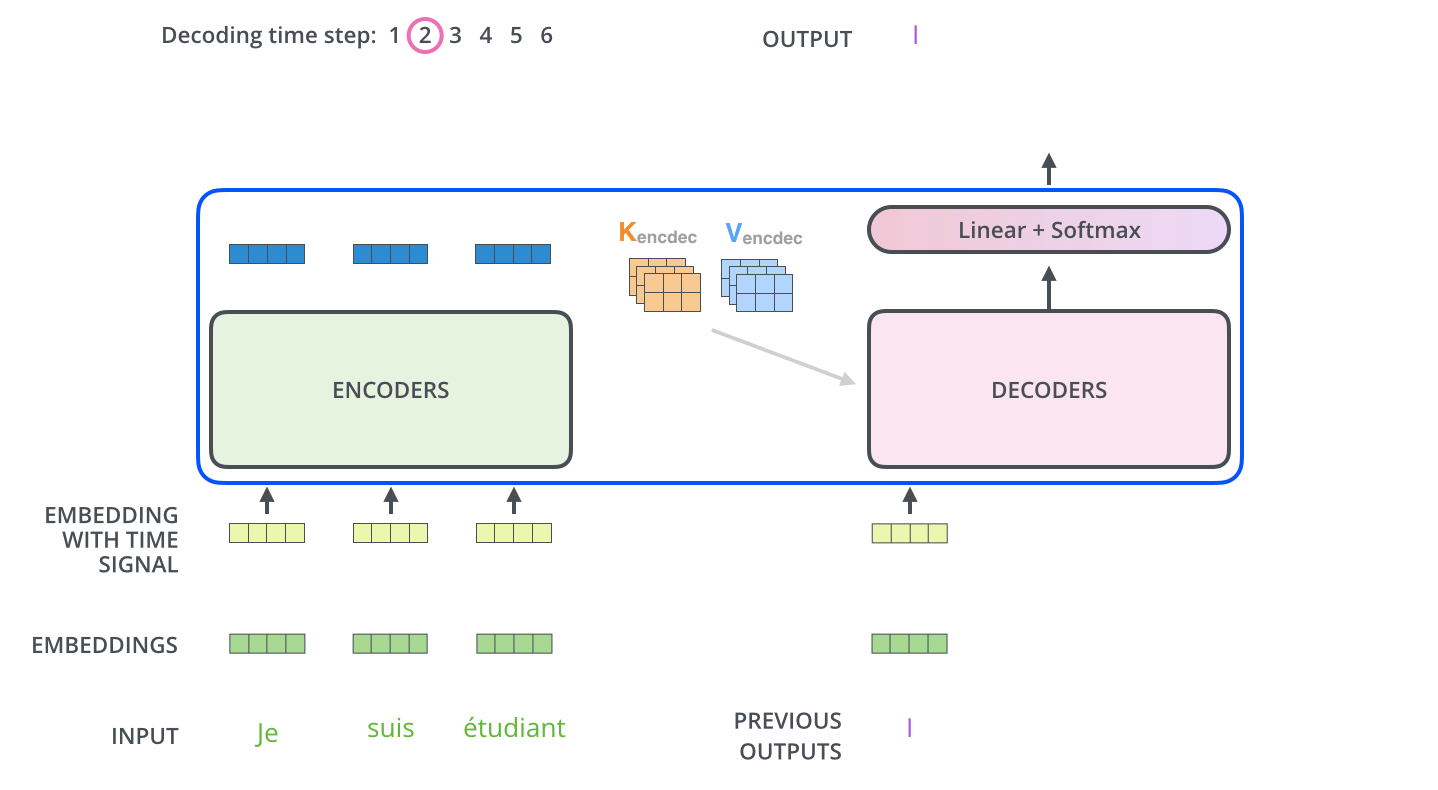
Decoder最后一层接着一个softmax层,词汇表长度的进行概率分布预测。
Transformer存在的问题
Transformer在NLP领域显示出巨大潜力,但是依旧存在很多问题,主要可归纳为以下两点:
• Transformer⽆法建模超过固定⻓度的依赖关系,对⻓⽂本编码效果差。
• Transformer把要处理的⽂本分割成等⻓的⽚段,通常不考虑句⼦(语义)边界,导致上下⽂碎⽚化(context fragmentation)。通俗来讲,⼀个完整的句⼦在分割后,⼀半在前⾯的⽚段,⼀半在后⾯的⽚段。
Transformer与RNN/CNN简单比较
特征提取(Feature Extraction)能力对比
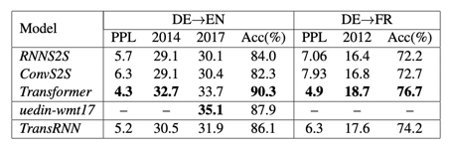
在长依赖( Long Dependency)文本上的对比
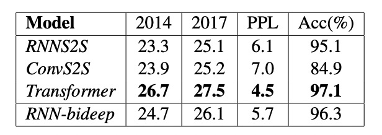
在复杂理解( Complexity comparison)问题上的对比


Transformer在文本摘要种的应用
PGN-Transformer模型
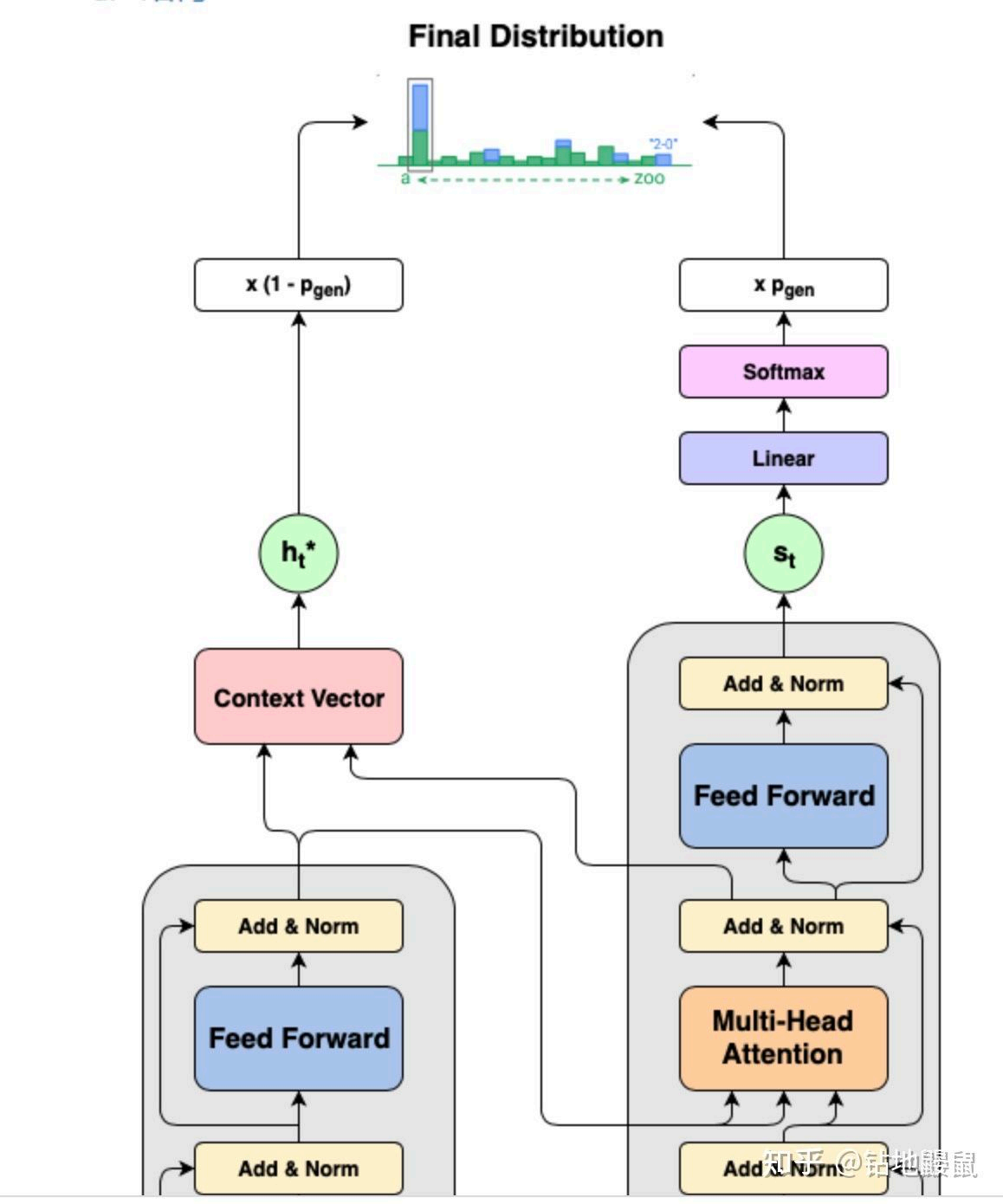
原文链接:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/custom/15784595.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号