
搭建一个简单的三层神经网络
1. 背景
- 使用numpy库手动实现一个前向传播过程
- 使用pytorch搭建一个简单的分类网络,搭配cifar-10数据集,完成的一个简单物体分类模型的搭建、训练、预测和评估。
2. 数据集介绍
cifar-10数据集是图像分类任务中最为基础的数据集之一,它由60000张32像素* 32像素的图片构成,包含10个类别,每个类别有6000张图片。其中50000张图片被划分为训练集,10000张为测试集。

3. 相关知识点
- 前向传播原理
- 基础分类模型搭建、训练及评估
4. 案例
task1:简单神经网络的前向传播
任务分析
问题1:定义初始参数及激活函数
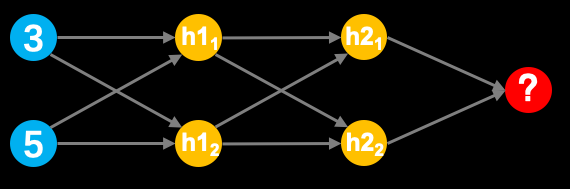
上图展示的是一个简单的神经网结构,它由一个输入层(蓝色)、两个隐藏层(黄色)和一个输出层(红色)组成。
- numpy数组定义
样例代码
import numpy as np
a = np.array([1, 3, 5])
- tanh激活函数
tanh激活函数数学计算公式如下:
\[tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
\]
问题2:逐层计算神经网络输出
- numpy的点成与矩阵相乘
- 点乘: numpy.dot()
一维矩阵:计算内积,即:dot( 1 x n , 1 x n ) = 一个数二维矩阵:线性代数矩阵相乘(n x m)·(m x s),即dot( n x m , m x s ) = n x s - 对应元素相乘:Numpy.multiply()和“*”
multiply( n x m , n x m ) = n x m( n x m ) * ( n x m ) = n x m注:两个矩阵必须行列相同
- 神经网络的乘法计算
完整步骤
使用numpy实现神经网络的前向传播过程,并算出输出层的最终输出结果。为了完成上述任务我们需要进行如下假设:
- 输入的值为[3,5]
- 隐藏层h1的两个权重为[2,4]、[4,-5]
- 隐藏层h2的两个权重为[-1,1]、[2,2]
- 输出层的权重为[-3,7]
- 所有层不使用偏置
- 所有隐藏层需添加tanh激活函数
定义一个numpy数组,内容为神经网络的输入数据
input_data = np.array([3, 5])
# 定义数据,作为输入数据
input_data = np.array([3, 5])
# 定义各个节点权重
weights = {
'h11': np.array([2, 4]),
'h12': np.array([4, -5]),
'h21': np.array([-1, 1]),
'h22': np.array([2, 2]),
'out': np.array([-3, 7])
}
# 定义tanh激活函数
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
# 输入层数据与第一隐层权重相乘、求和,并输入激活函数中
hidden_11_value = tanh( (input_data * weights['h11']).sum() )
hidden_12_value = tanh( (input_data * weights['h12']).sum() )
hidden_1_output = np.array([hidden_11_value, hidden_12_value])
# 第一层输出数据与第二层隐层权重相乘、求和,并输入到激活函数
hidden_21_value = tanh( (hidden_1_output * weights['h21']).sum() )
hidden_22_value = tanh( (hidden_1_output * weights['h22']).sum() )
hidden_2_output = np.array([hidden_21_value, hidden_22_value])
# 输出层,无激活函数
output = (hidden_2_output * weights['out']).sum()print(output)
至此,已完成全部计算。
task2 cifar-10图像分类
问题1:搭建简单的神经网络
在本问题中,nn.Linear的主要参数有in_features和out_features,只需要填入对应的形状即可,样例如下:
input_ = torch.randn(128, 20)
layer = nn.Linear(20, 30)
out = layer(input)
问题2:神经网络的训练
本问题中,课根据训练步骤完成代码,神经网络训练步骤如下:
- 清空优化器梯度
- 读入data和label
- 运行模型前向传播过程
- 基于模型输出生成最终结果
- 计算损失
- 基于损失计算梯度
- 基于梯度更新参数
样例代码如下
outputs = net(inputs) # 模型前向传播
loss.backwards() # 用于计算梯度
optimizer.step() # 用于参数更新
optimizer.zero_grad() # 用于清空优化器梯度
inputs,label = data # 用于读取data和label
inputs = inputs.view(-1, 32*32*3) # 用于对输入形状进行变化
preds
问题3:模型测评
模型测评过程中的数据导入、前向传播过程与训练过程基本相同。
完整步骤
- 大for循环-epochs,用于管理一套数据循环训练几遍
- 小for循环-step,用于以batchsize为单位,从dataloader中调取数据
- 清空优化器的梯度
- 读入data和label,并进行形状变换(可做可不做)
- 运行模型前向传播过程
- 基于模型输出生成最终结果
- 计算损失
- 基于损失计算梯度
- 基于梯度更新参数
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(
(0.49140, 0.48216, 0.44653),
(0.24703, 0.24349, 0.26159) )
])
trainset = torchvision.datasets.CIFAR10(root=r'.', train=True, download=True, transform=transforms)
testset = torchvision.datasets.CIFAR10(root='.', train=False, download=True, transform=transforms)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=16)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=16)
print(trainset.classes) # 查看类别
# 搭建简单神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(32*32*3, 1000)
self.fc2 = nn.Linear(1000, 500)
self.fc3 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
net = Net()
# 定义损失函数
criteria = nn.CrossEntropyLoss()
# 定义优化器,将神经网络参数传入,并定义学习率
optimizer = optim.Adam(net.parameters(), lr=1e-4)
# 神经网络训练
num_epochs = 10
since = time.time()
net.train()
for epoch in range(num_epochs):
print(f"Epoch {epoch + 1}/{num_epochs}")
running_loss = 0.0
running_correct = 0
for data in tqdm(trainloader):
# 清空梯度
optimizer.zero_grad()
inputs, labels = data
outputs = net(inputs.view(-1, 32*32*3))
loss = criteria(outputs, labels)
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_correct += torch.sum(preds == labels)
epoch_loss = running_loss / trainloader.dataset.data.shape[0]
epoch_acc = running_correct.double() / trainloader.dataset.data.shape[0]
print("train loss: {:.4f} Acc: {:.4f}".format(epoch_loss, epoch_acc))
print('+++'*10)
time_elapsed = time.time() - since
print('Training complete in "{:0f}m{:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
# 模型评估
correct, total = 0, 0
net.eval()
for data in tqdm(testloader):
inputs, labels = data
inputs = inputs.view(-1, 32*32*3)
outputs = net(inputs)
_, predict = torch.max(outputs, 1)
total += labels.size(0)
correct += (predict == labels).sum().item()
print("The test set accuracy of network is: %d %%" % (100 * correct / total))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号