
【NLP之文本摘要】2-文本摘要与Seq2seq结构
1. 背景
学习某培训平台文本摘要项目第二节课seq2seq的内容,结合课件和自己的理解做一下笔记。本节内容主要讲了两个点:1. text summarization的实现方法,以text rank为例;2. seq2seq模型,包括RNN,LSTM,GRU等内容。特此记录,供自己学习。
2. 案例
2.1 文本摘要概述
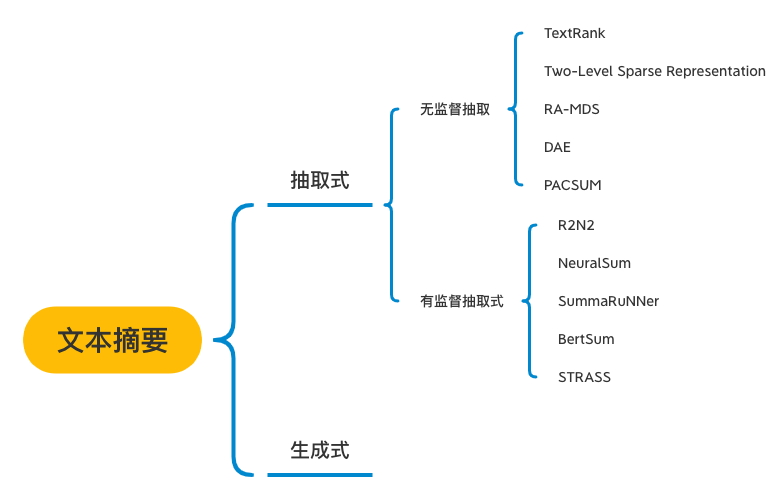
文本摘要(text summarization)主要分为两种方法:生成和抽取。本节内容主要以抽取式方法为主,以text rank为例,讲了下整个过程。
2.1.1 page rank
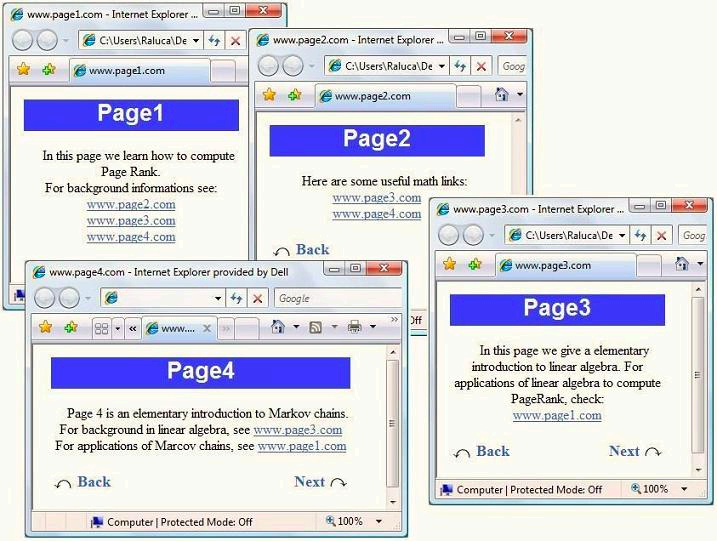
text rank方法源于page rank算法,因此首先从page rank方法说起。page rank方法源于网页搜索,例如某一个网页Page1中,链接了其他若干个网页,如下图。那么如何衡量每个网页的重要性呢?
page rank的做法是讲不同网页间的连接关系,表示成图。如下: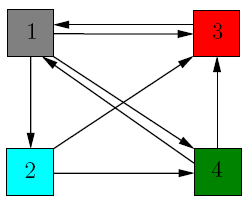 -->
--> 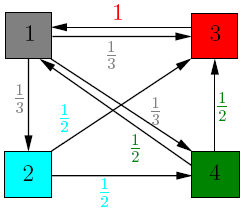
最终,得到各个网页的权重矩阵:
    其中,图1中各个节点表示不同的网页;某个节点的出度即为边的权重,例如节点3的出度为1,因此其边的权重为1;节点4的出度为2,因此每条出度相关的边的权重为\(\frac{1}{2}\),最后将该权重矩阵,做若干次乘法,得到一组稳定的权重,即为各个网页的权重。
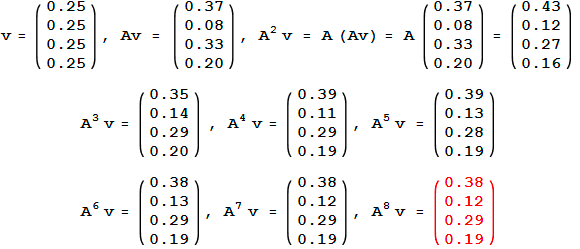
2.1.2 text rank
text rank的做法,是仿照page rank的做法,将文档与句子的关系,映射为网页与连接的关系。主要流程如下:
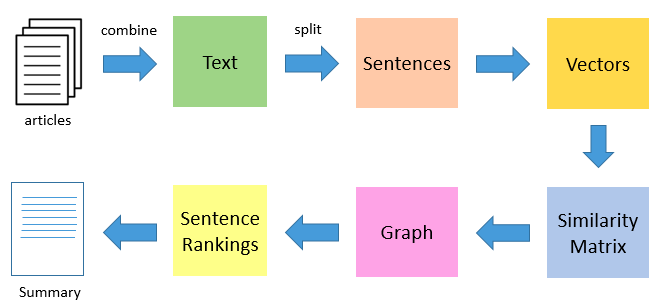
将每个文档拆分成若干个句子,每个句子用向量表示(中间设计到如何用词向量,表示句子向量的问题);然后任意两个句子间的相似度,即为类比网页最终得到的权重矩阵。最终得到的权重矩阵,经过若干次迭代后,得到的稳定的矩阵,即为文本摘要抽取的内容(大体思路是这样,具体代码暂时无法同步)。
2.2 seq2seq 架构
2.2.1 sequence components-RNN(Recurrent Neural Network)
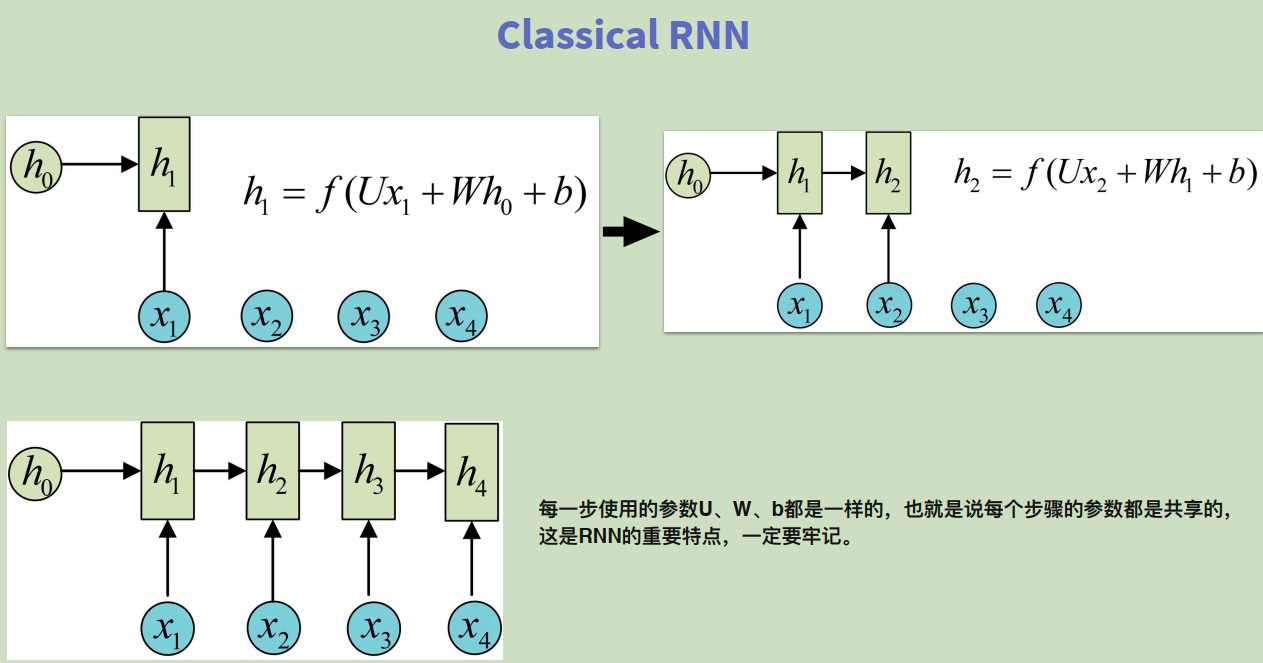
rnn具体理论不做具体展开,中间有一个点是之前没有明白的是:权重共享。RNN中权重共享体现在,在\(h_1, h_2, ...\)中,使用的是同一组\(W, U, b\),这是之前没有梳理清楚的内容。RNN的输出形式如下:
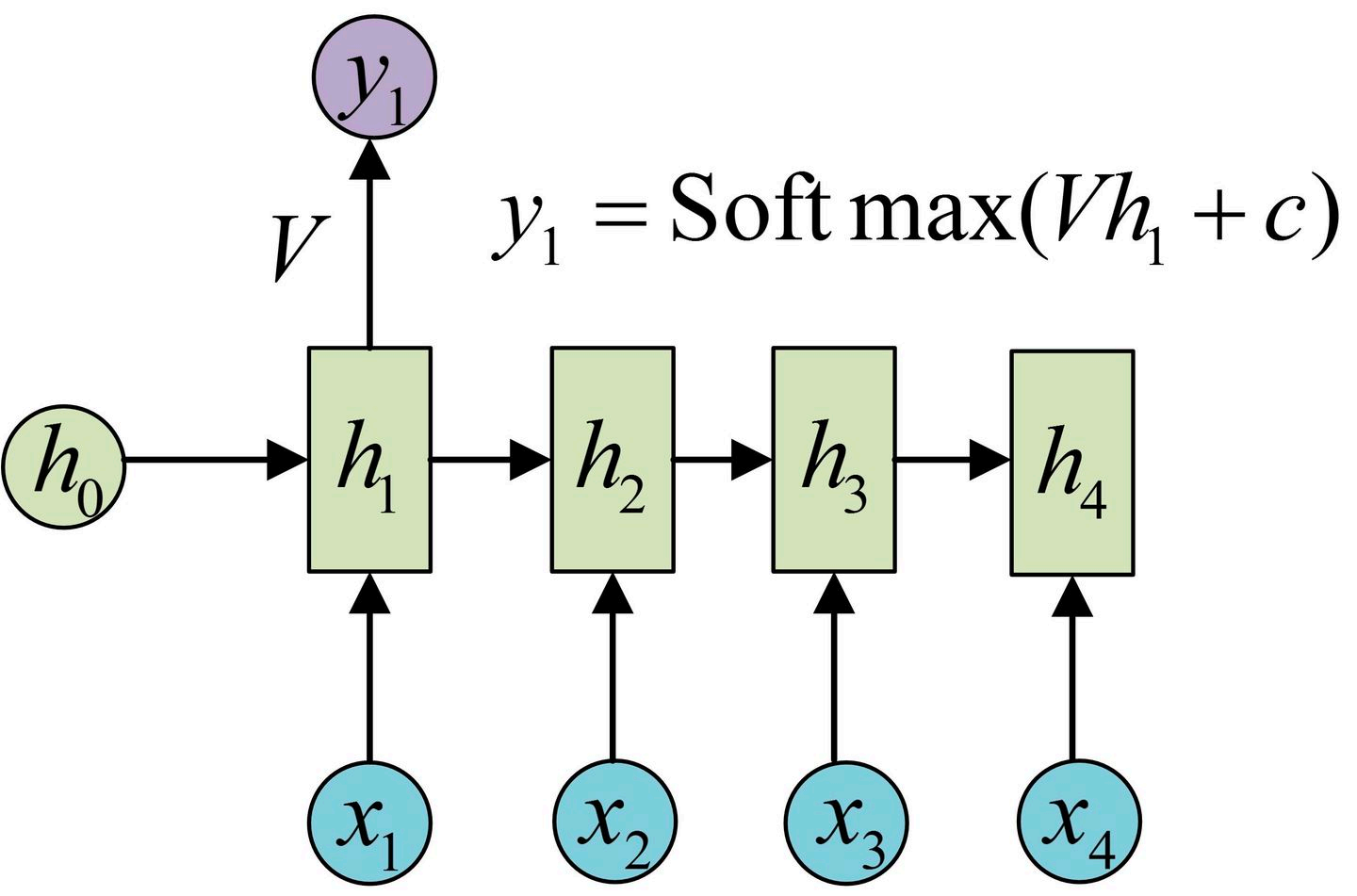
模型的输出,可以在每一个节点(N vs N),或者最后一个节点(N vs 1),或者某几个节点(N vs M),分别对应不同的RNN变形形式。和其他神经网络结构类似,最后的输出接一个softmax即可。
- N vs N
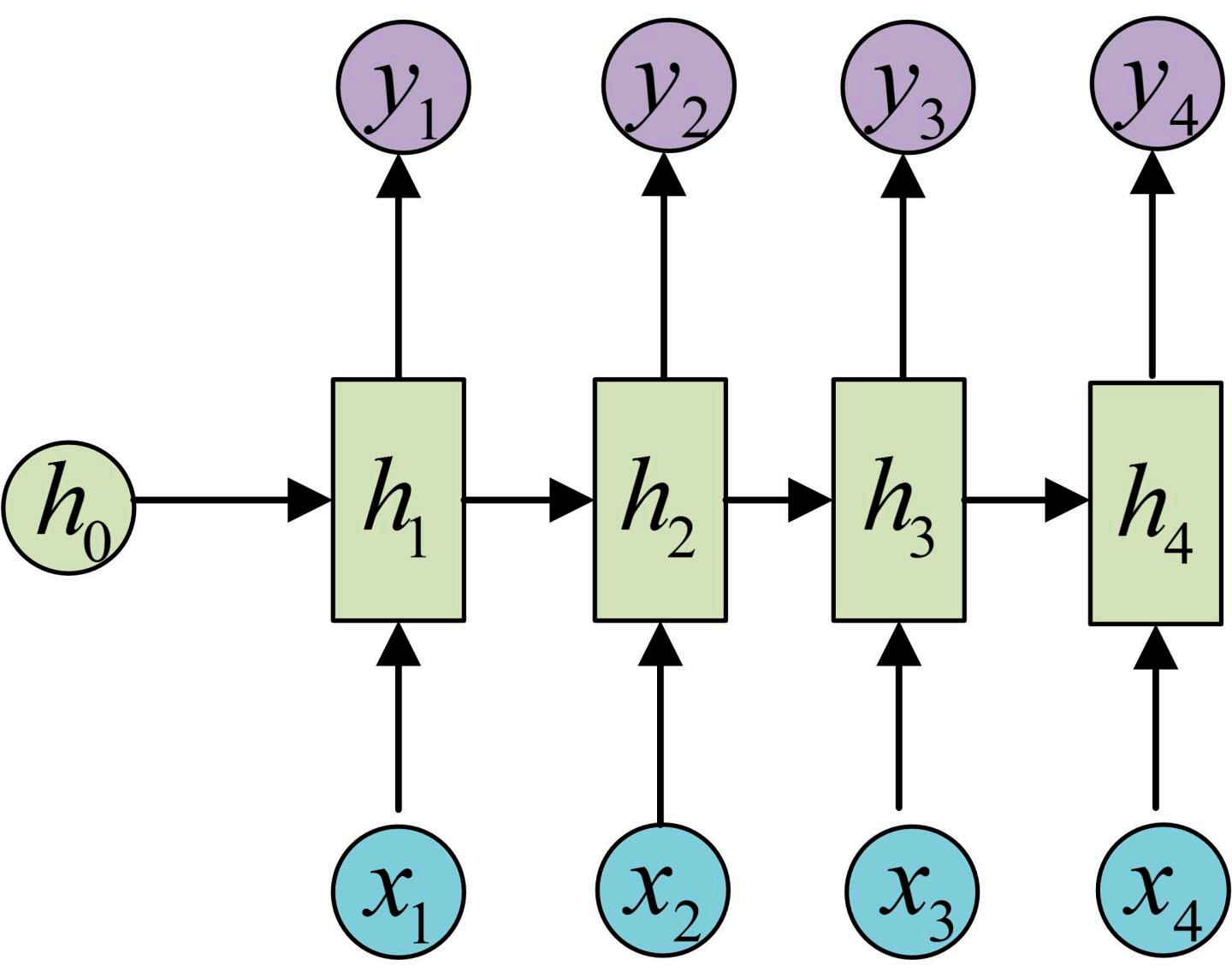
一般应用场景有:命名实体识别、视频中每一帧的分类标签等。其反向传播过程如下:
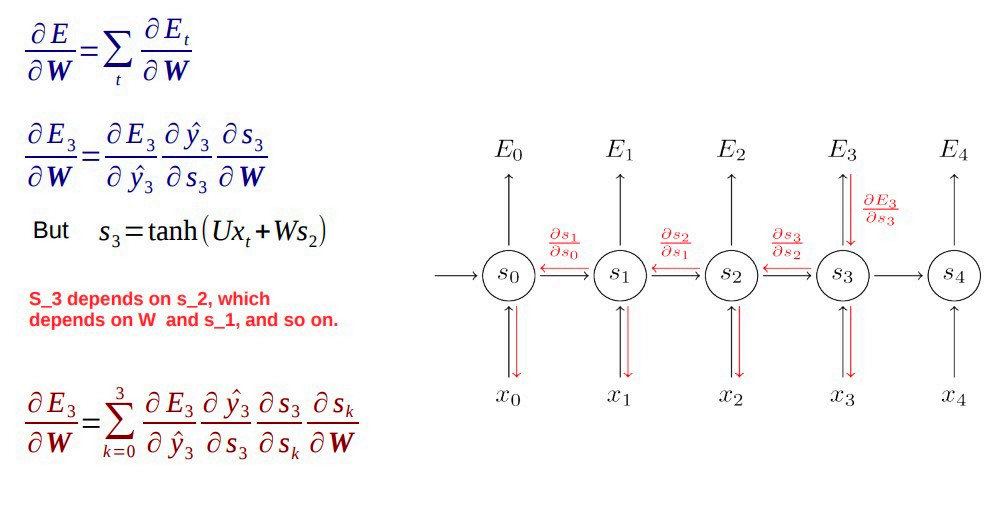
反向传播过程中不可避免的两个问题:梯度消失和梯度爆炸。
梯度消失的解决方案有:
- 更换激活函数为ReLU、GELU等,
- 更换网络结构为LSTM等;
- Batch Normalization
梯度爆炸的解决方案有:
- 梯度裁剪;
- Truncated BTT.意思是,不用等整个序列传播完,再计算梯度,而是传播了一段(N的子集,假设为M)就开始计算;因此,该方法中,若M过大,则和等待传播完成计算类似,可能梯度爆炸或消失;若M过小,则可能起不到反向传播的作用;
- 3.使用自适应的学习率,如Adam等。
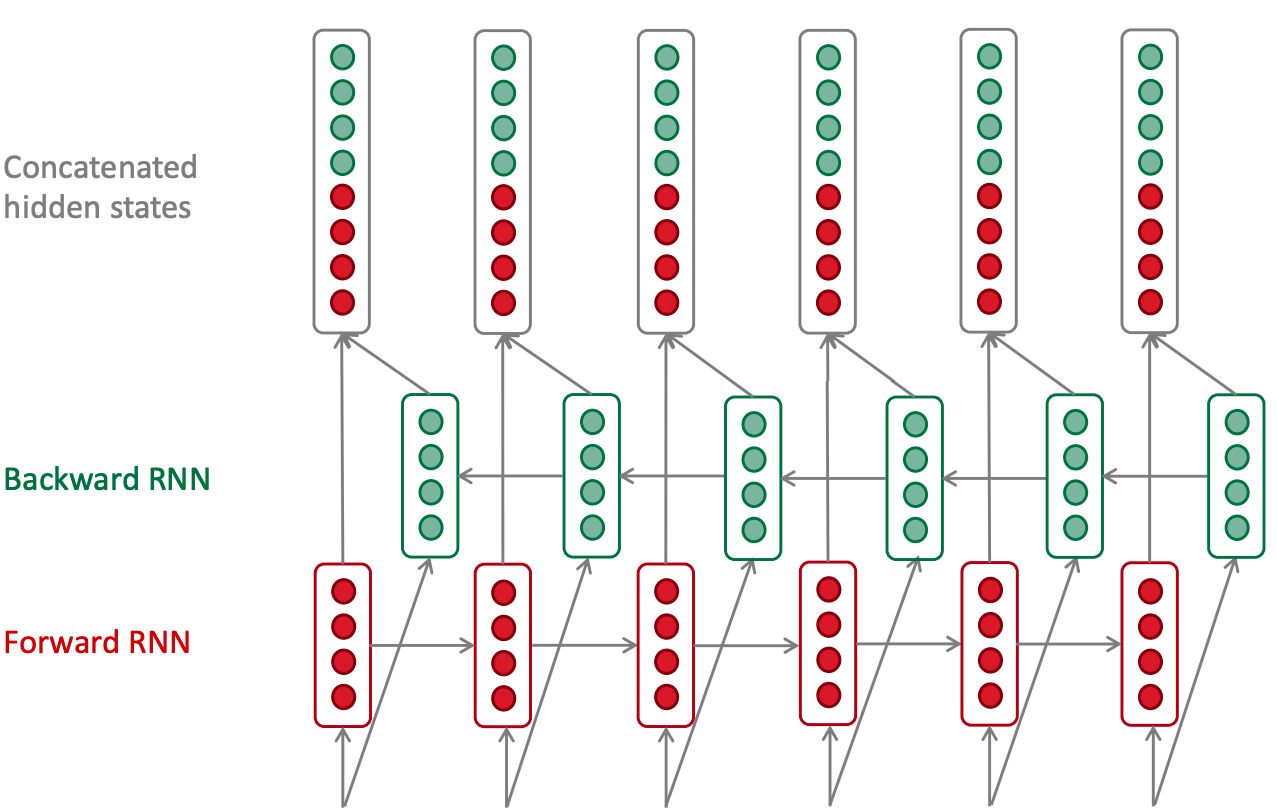
在双向RNN中,基本和单向RNN相同;最后是将两个方向得到的特征,进行拼接,作为最后的输入。
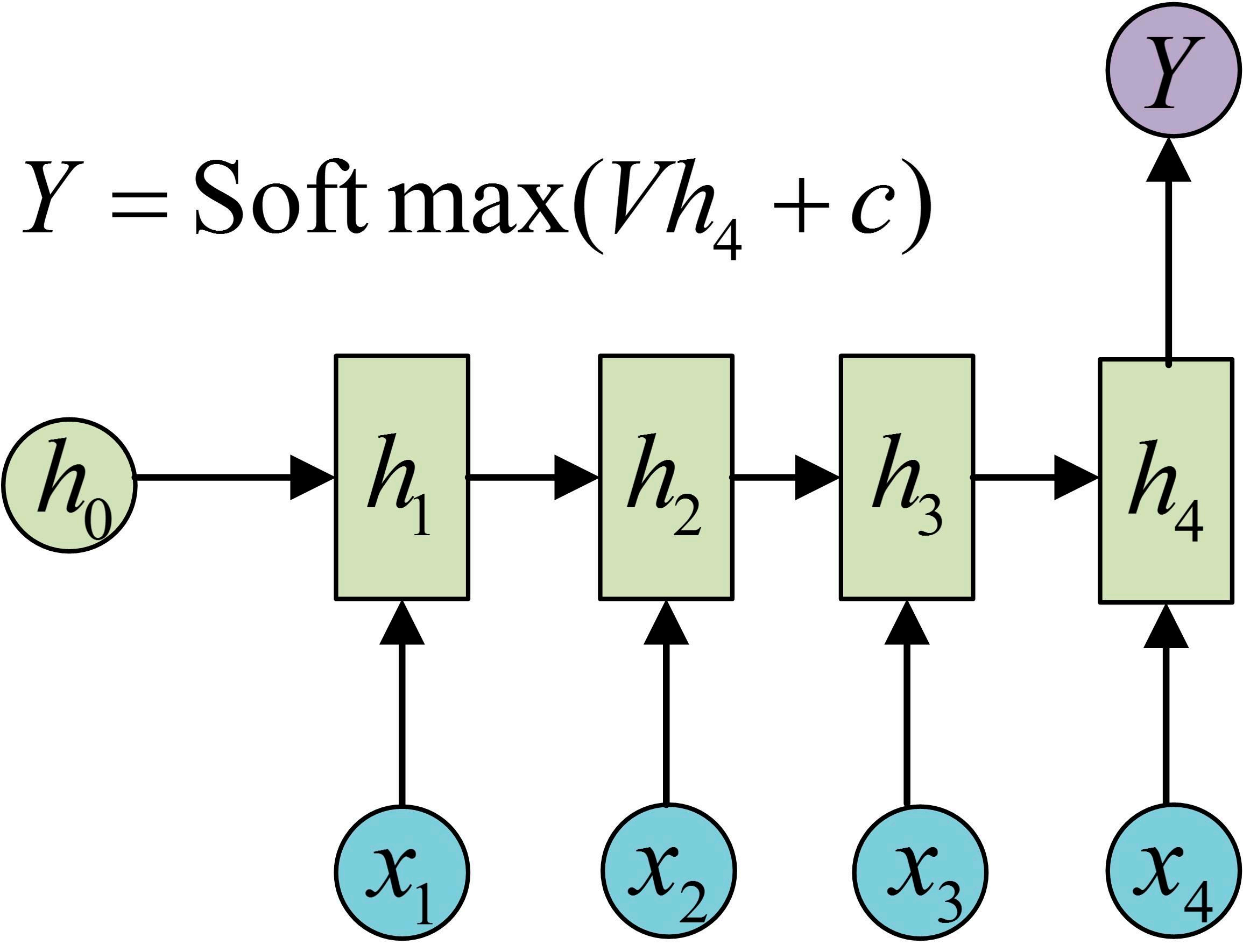
- N vs 1
N vs 1的结构如下。一般可用于文本分类、情感分析等场景。
- 1 vs N
1 vs N有两种不同的形式,一般可用于图像文字生成、类别生成语音和音乐等场景。
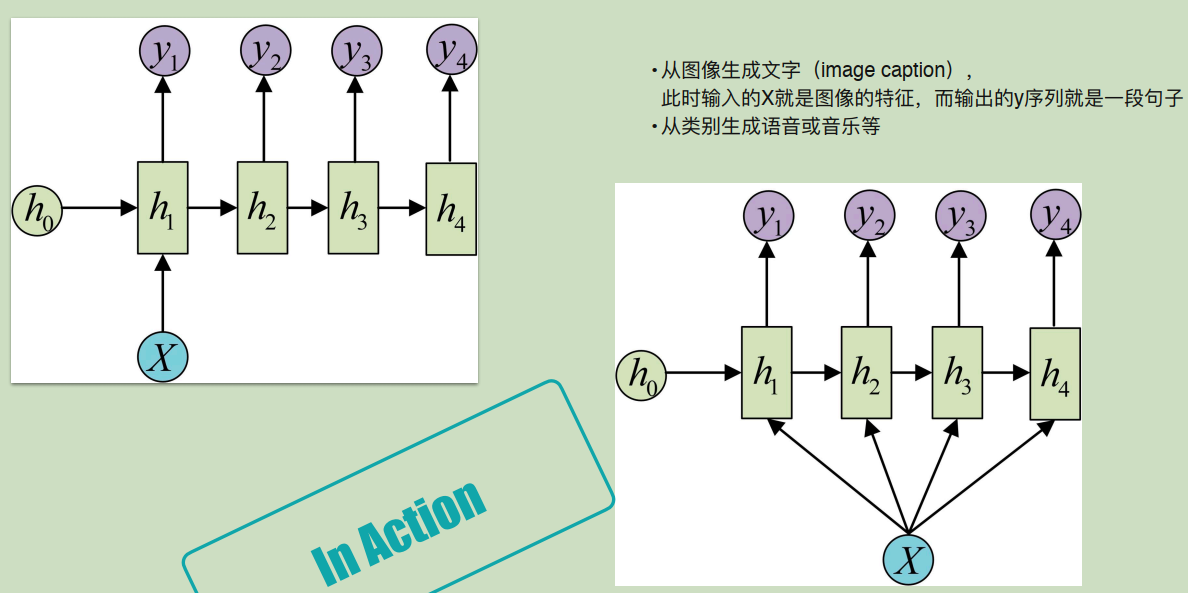
- N vs M
就是对应的seq结构,后续具体展开。
2.2.2 sequence components-LSTM(Long short Term Memory)
针对RNN梯度消失或梯度爆炸、难以训练等问题,提出了lstm模型,其中重要概念在于长短期的记忆如何衡量,其单个结构如下:
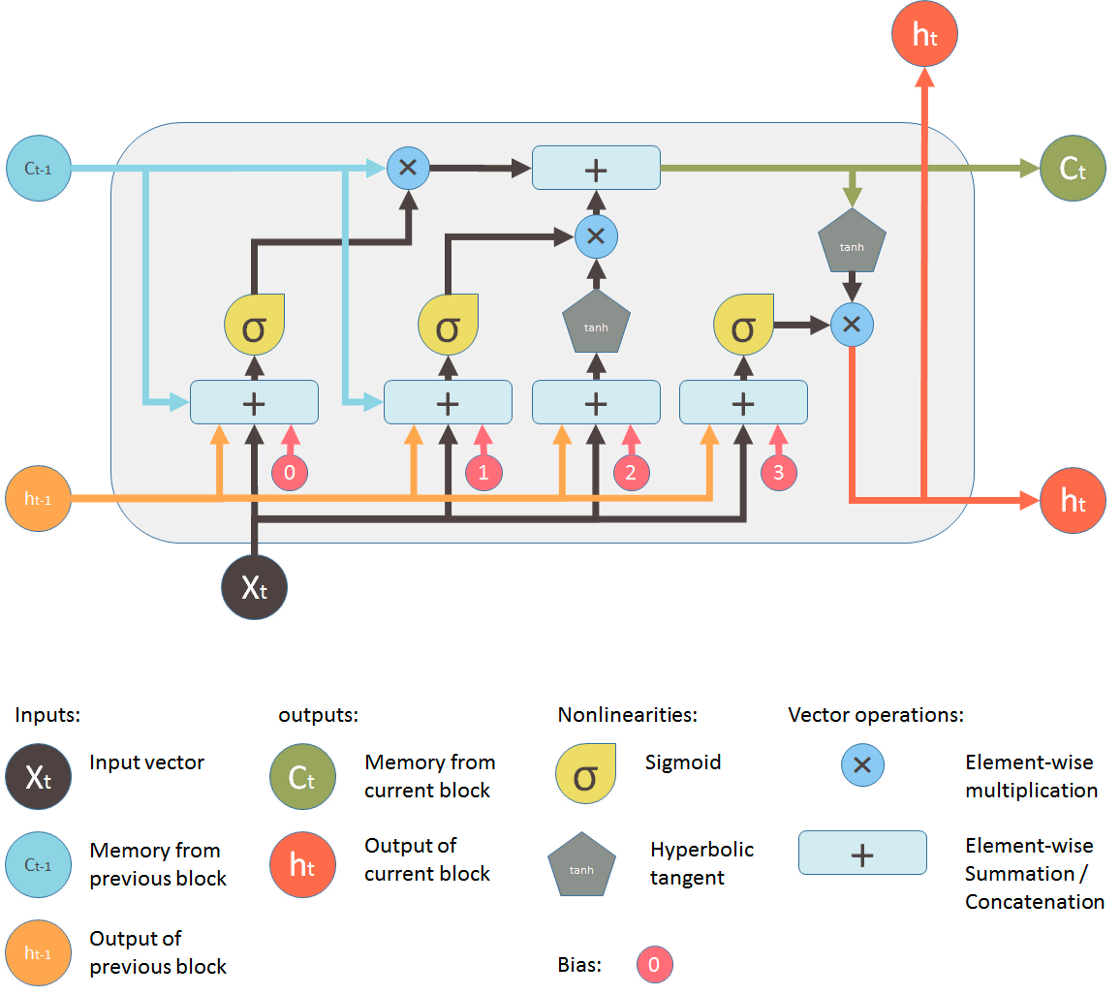
lstm由四个组件构成:遗忘门、更新门、记忆管道、输出门。
- 遗忘门(forget gate)
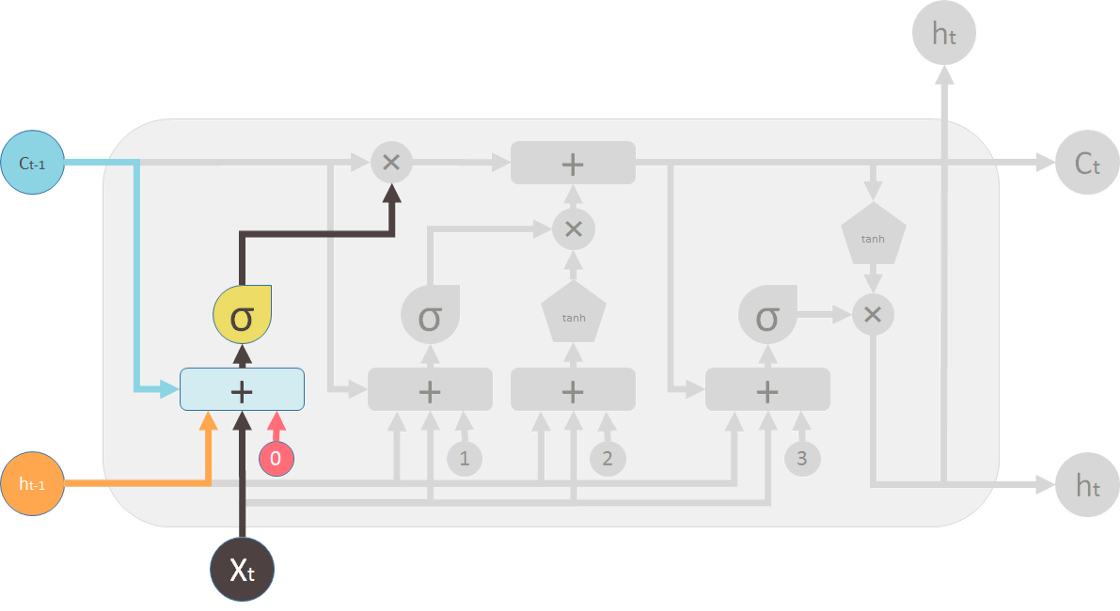
遗忘门决定了有多少信息会被保留。 - 更新门(update gate)
更新门决定了有多少信息会被更新。
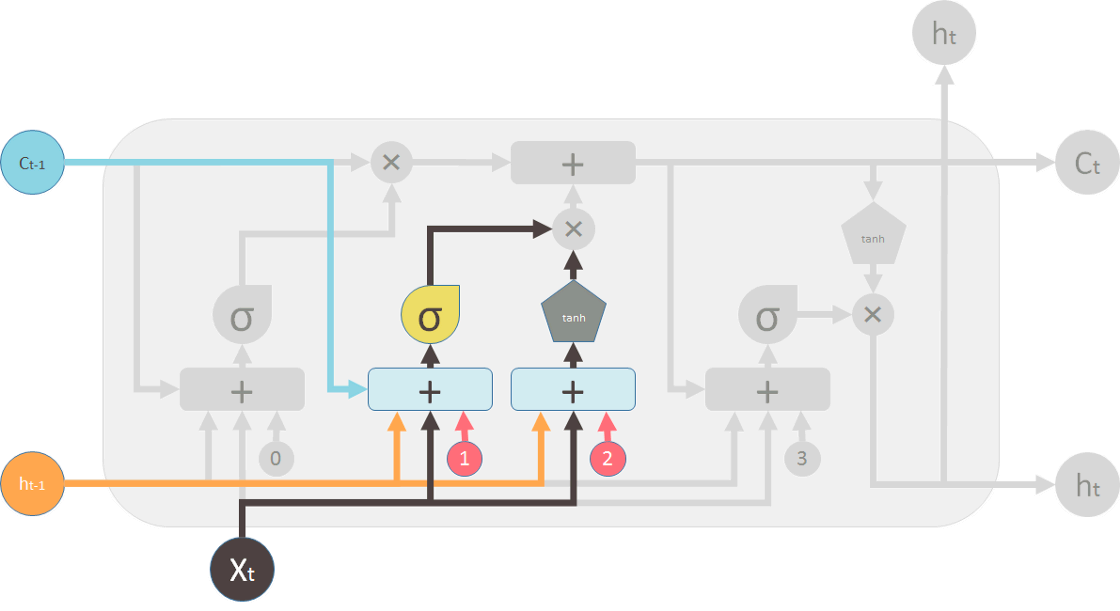
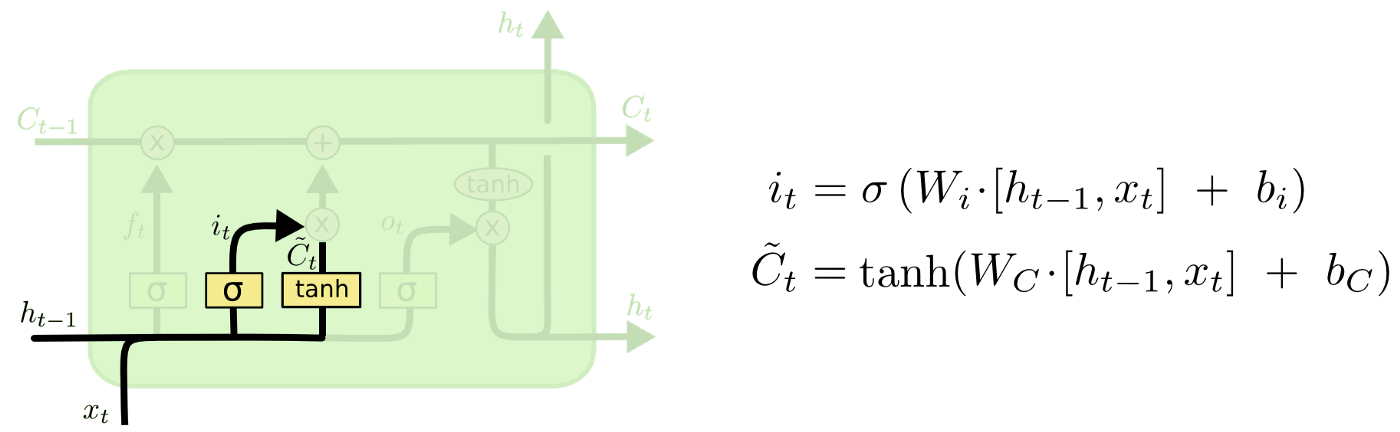
- 记忆管道(Memory Pipe)
在确定了有多少信息会被更新外,就可以输出新的记忆\(C_t\),因此,可以向后传递,参与到后面的运算。
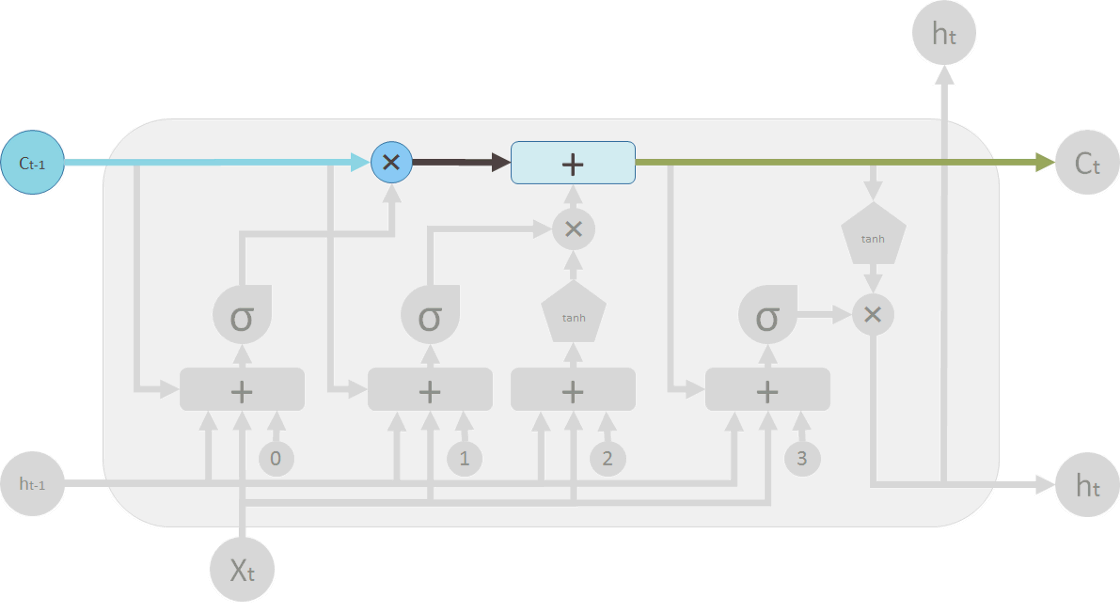
- 输出门(output gate)
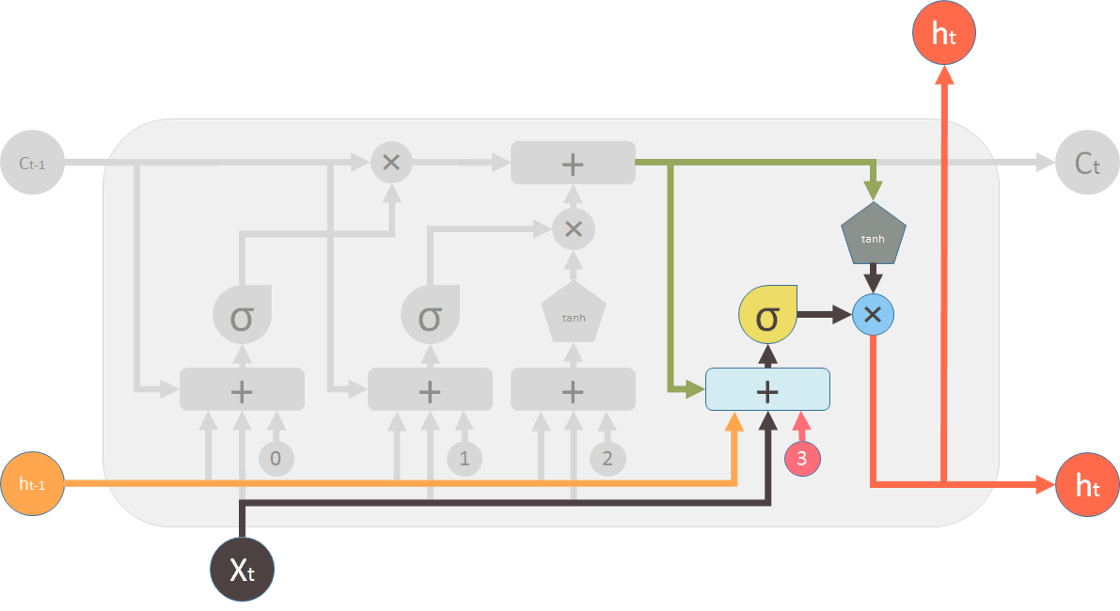
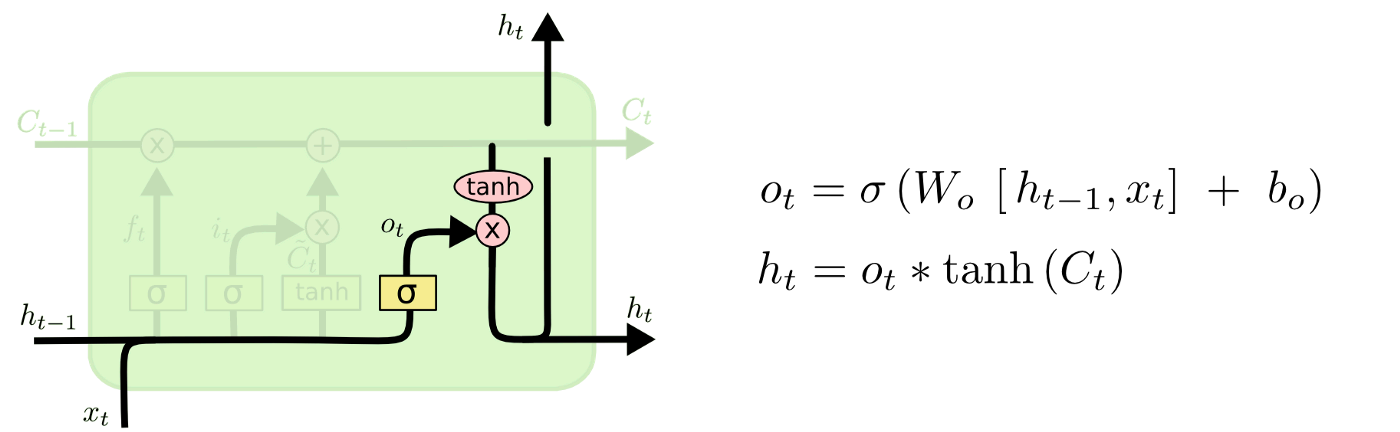
2.2.3 sequence components-GRU
针对lstm参数较多的问题,提出了GRU对其进行简化,其主要结构如下。感觉老师没有具体讲,还是有点模糊,后面找点资料补充学习一下。
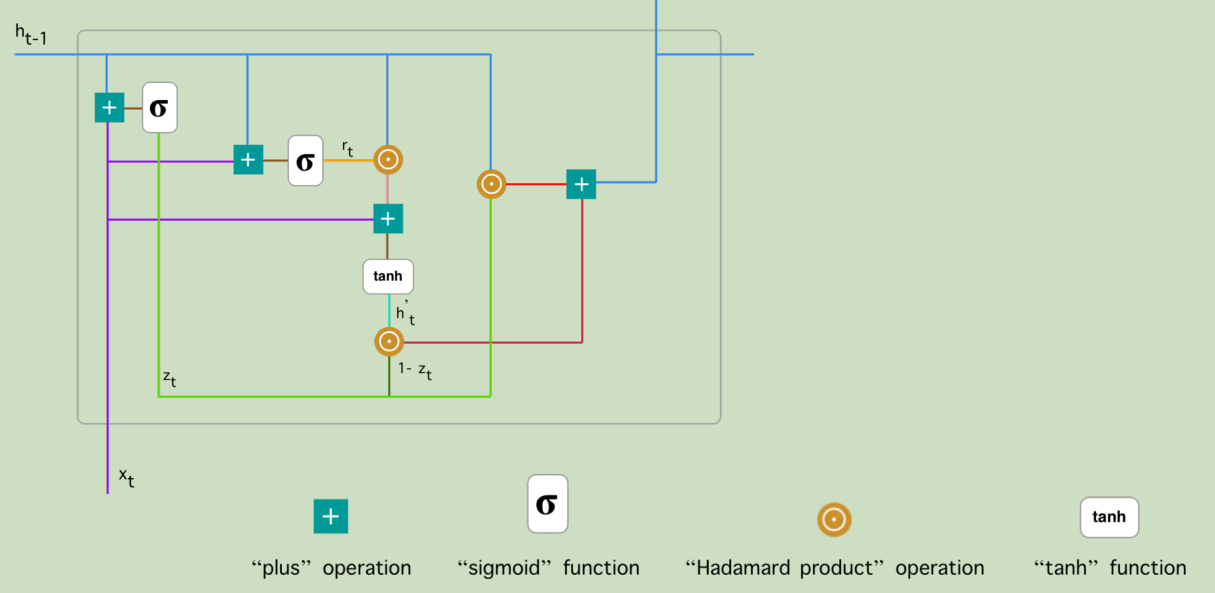
2.2.4 小结
- gru相对于lstm,参数更小,收敛更快
- 从表现上看,二者效果上并没有太大区别。
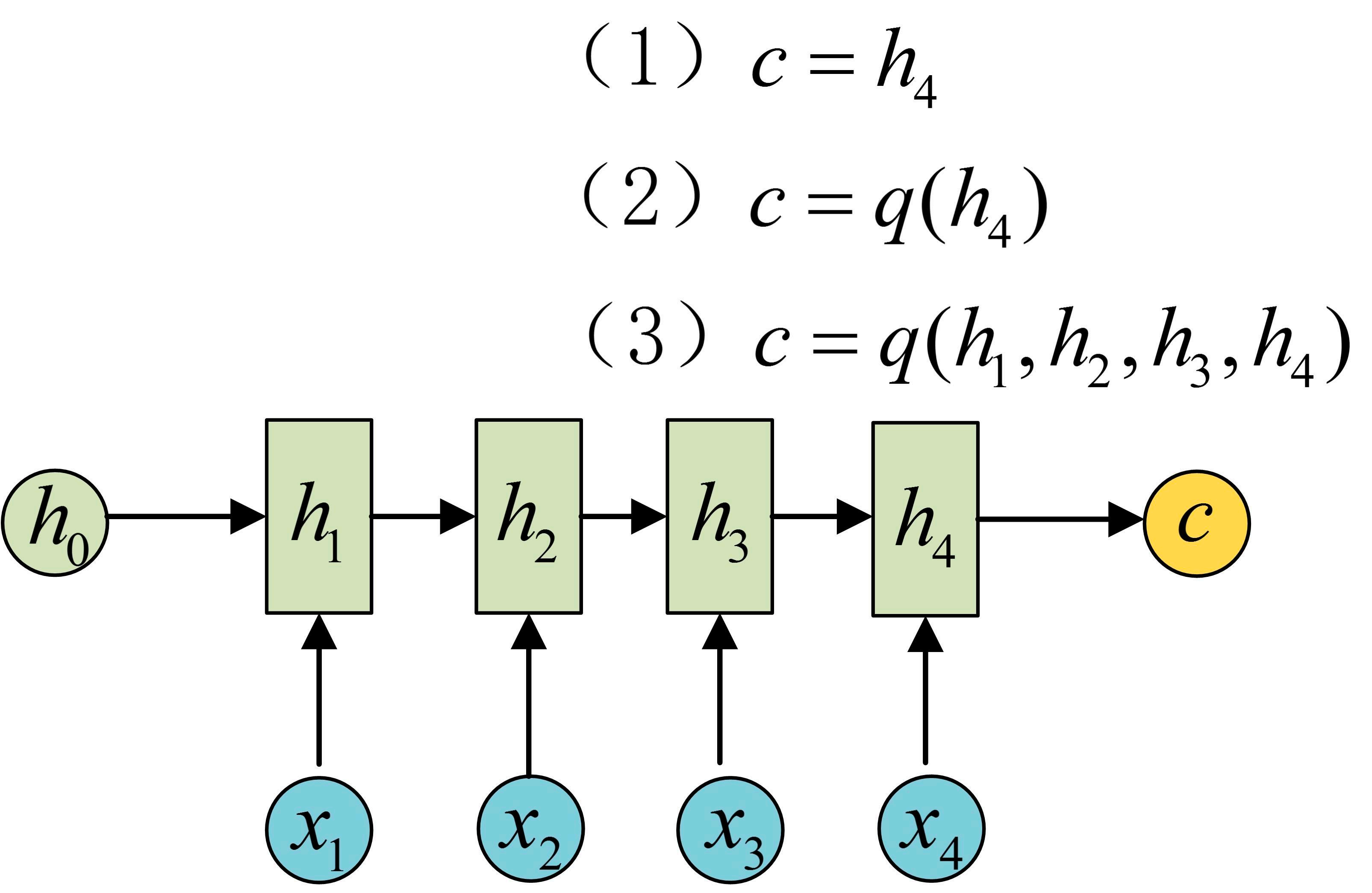
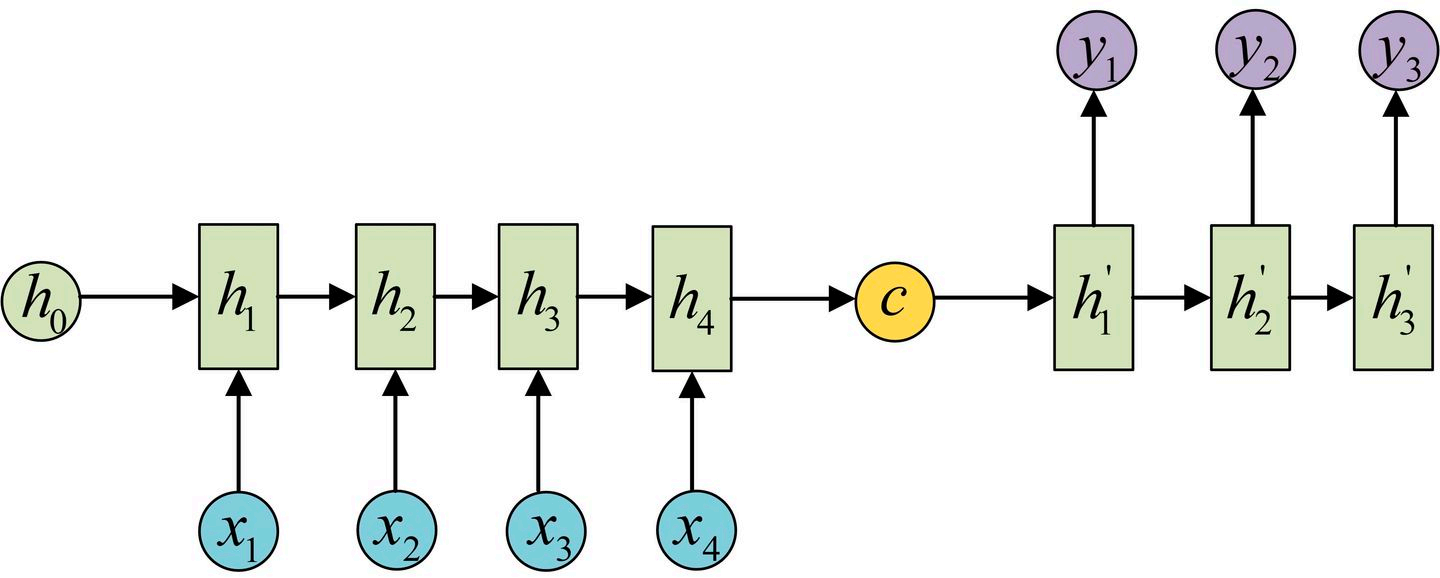
2.3 seq2seq
seq结构有两个形式:
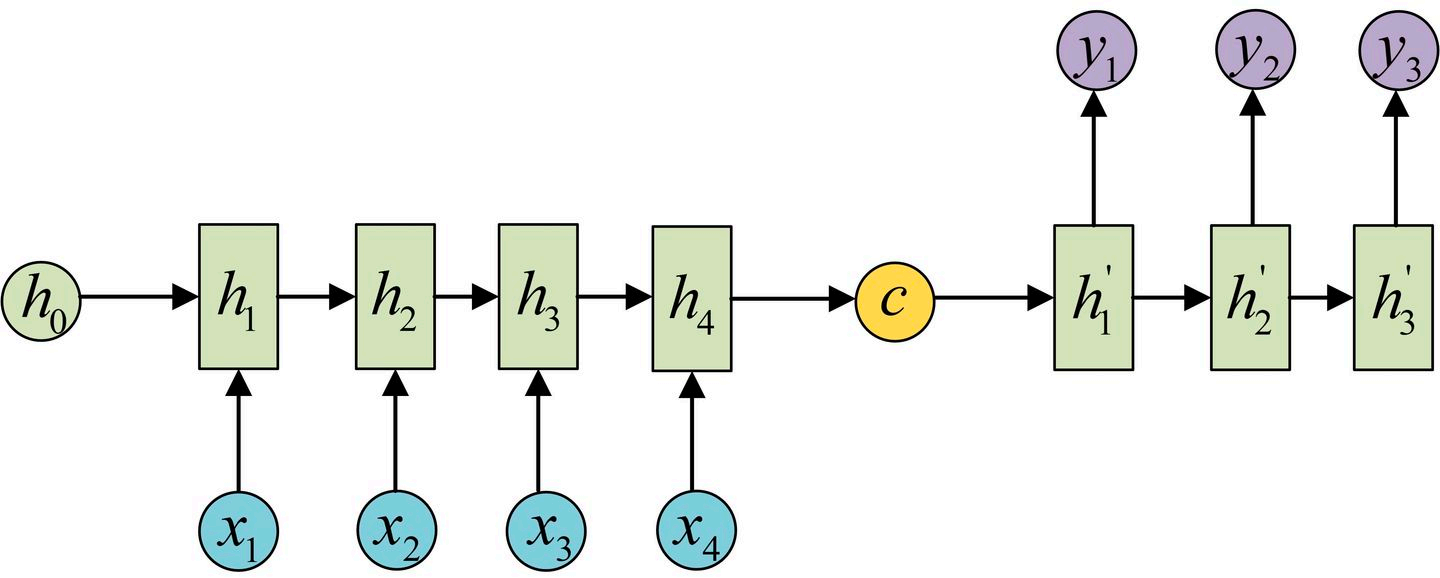
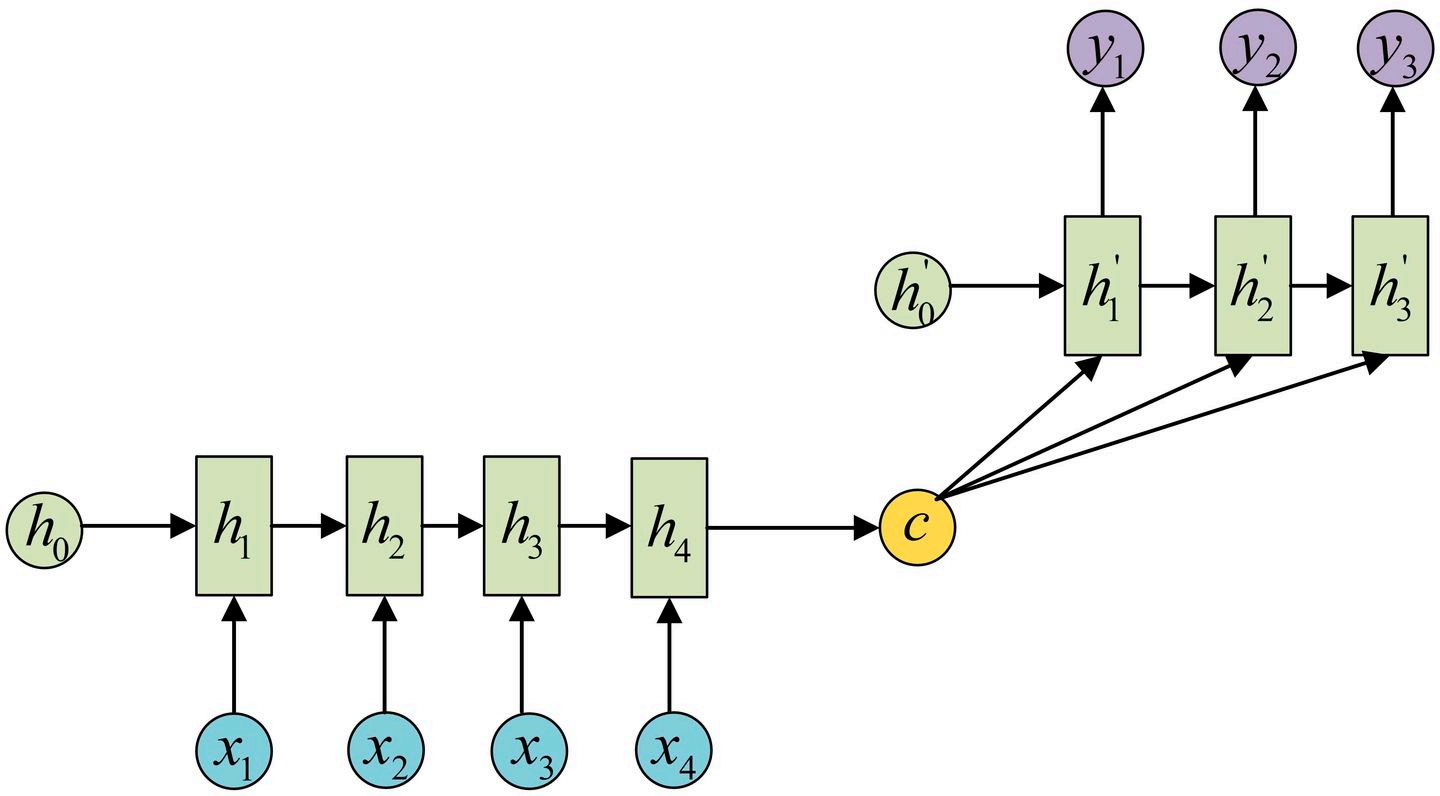
宏观结构如下:
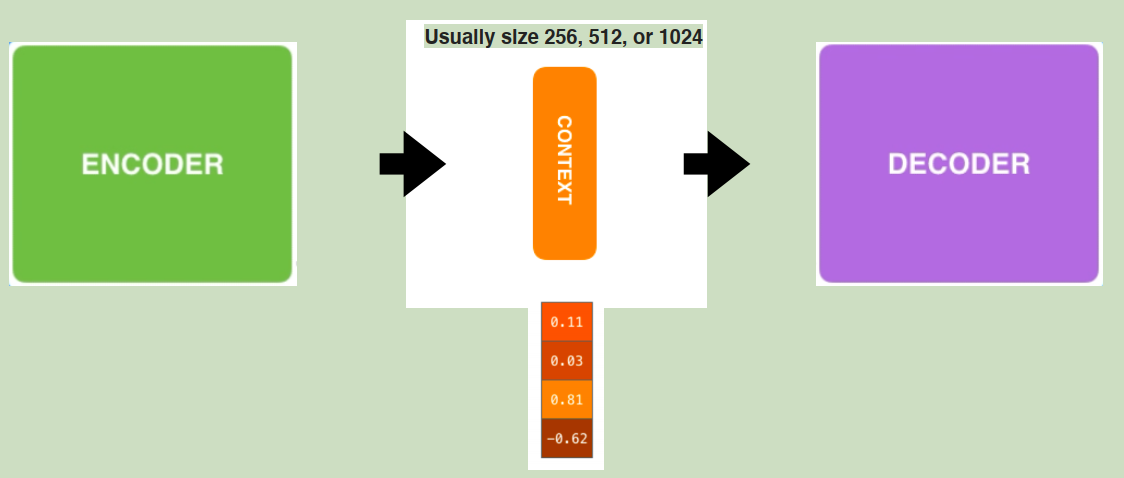
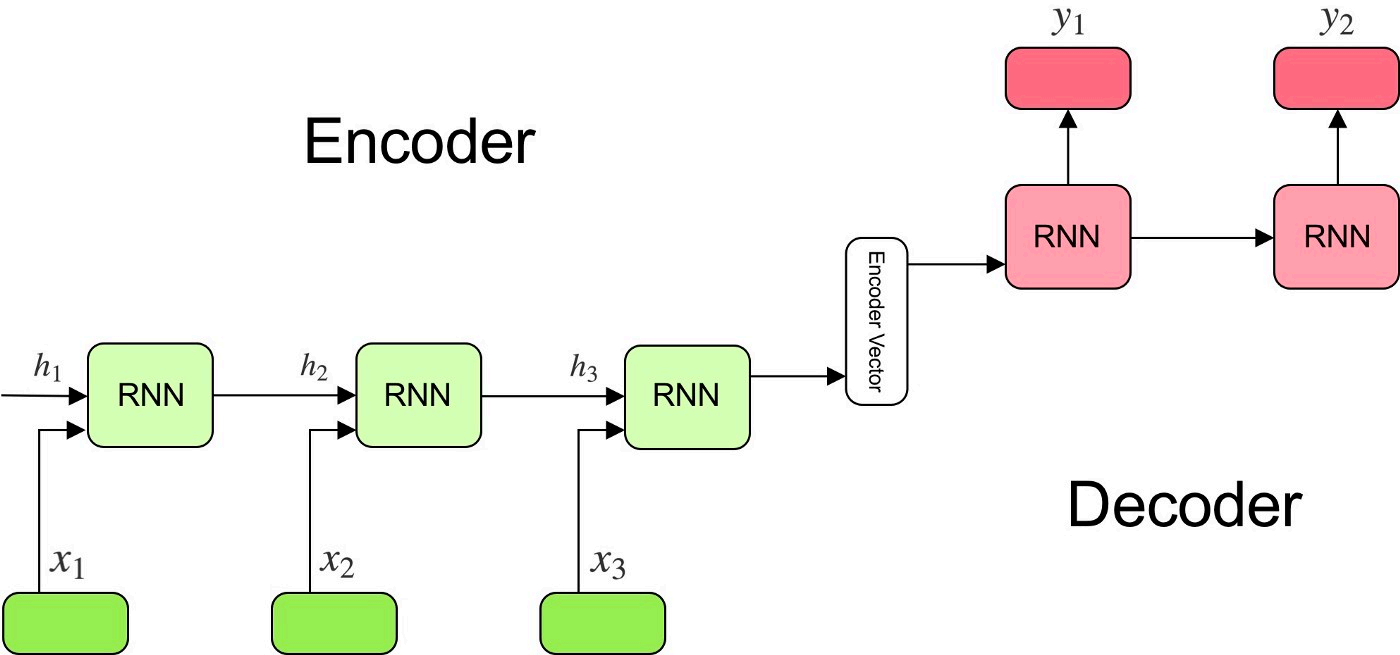
2.4 注意力机制
没有具体展开讲,感觉需要补充一些学习资料。
2.4.1 线性加形式的注意力
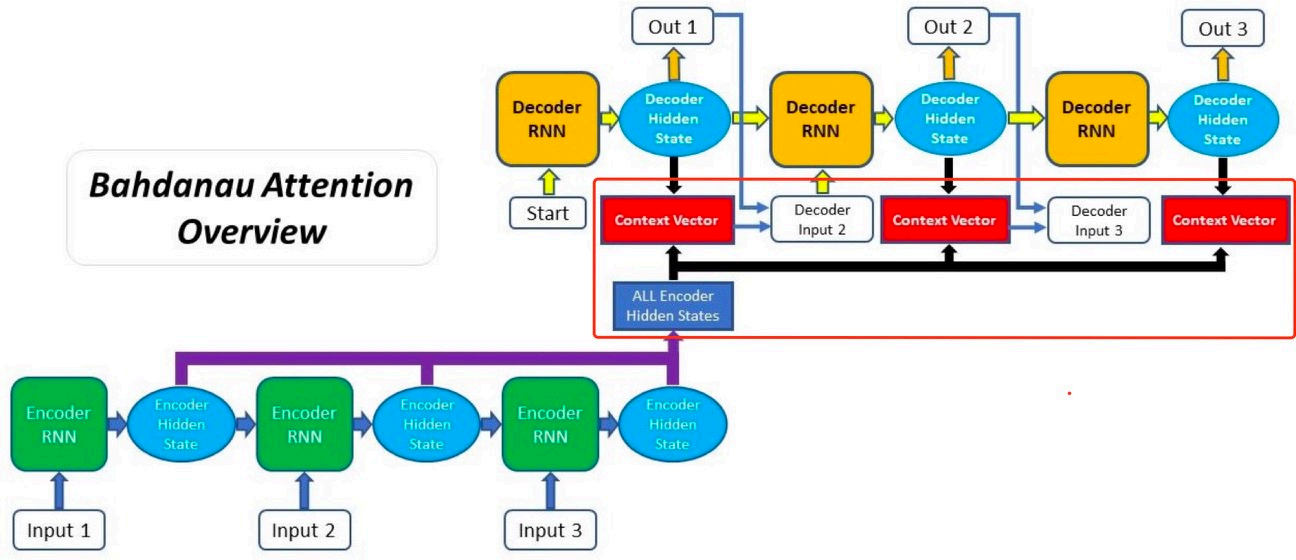
具体计算过程如下:
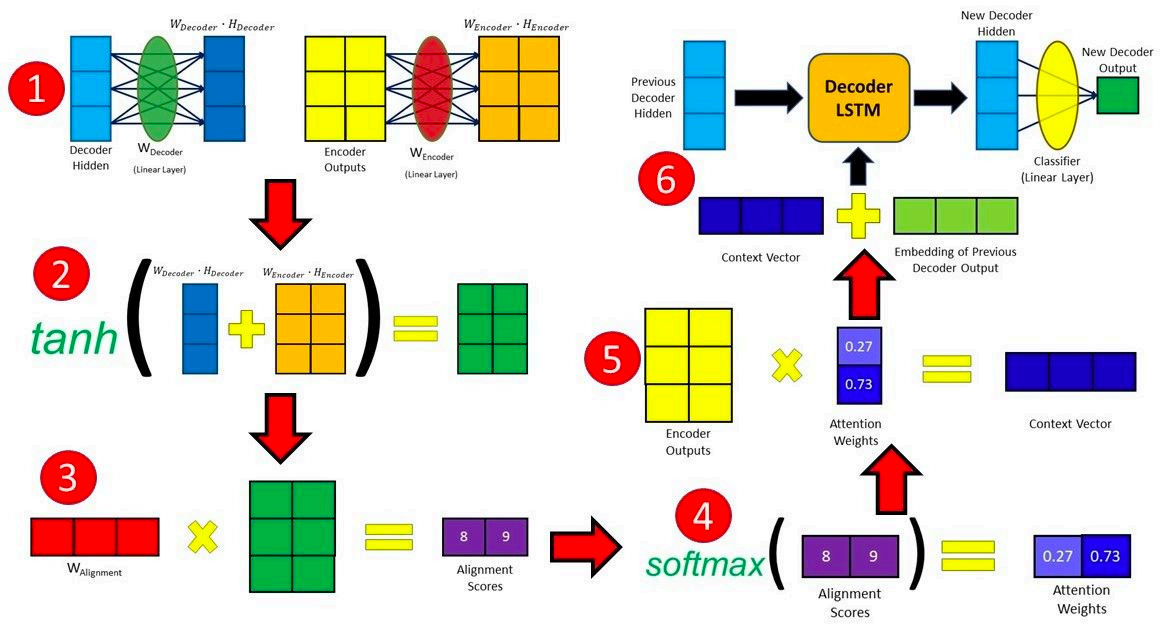
2.4.2 线性乘形式的注意力
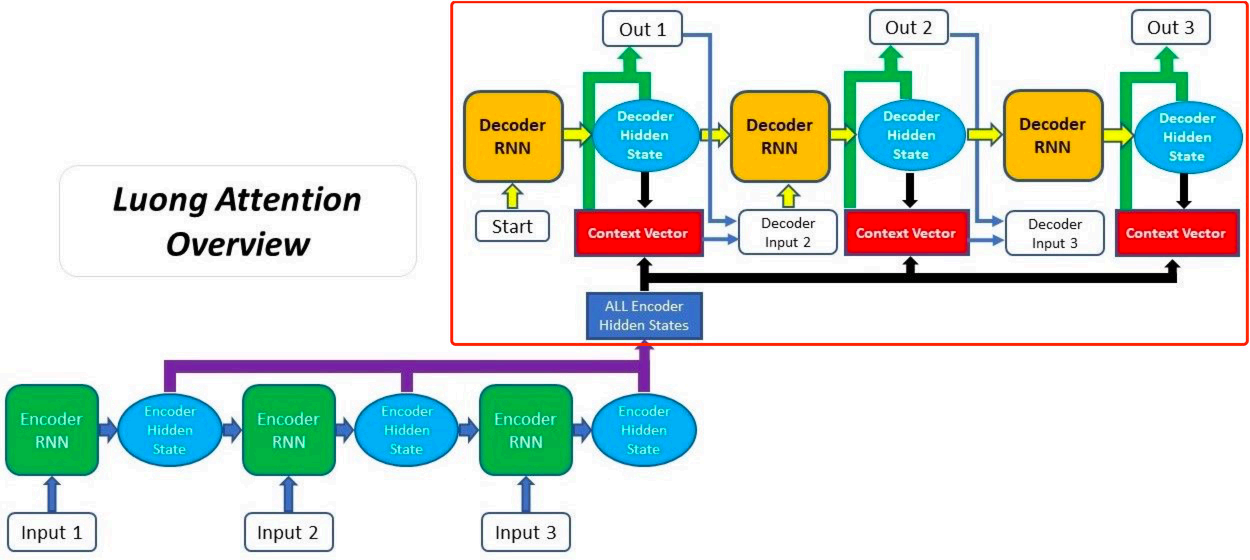
3. 总结
- lstm内容讲解还是清晰的,但是GRU没有具体说,后面补充资料自己学习
- 注意力机制,感觉也没有讲清楚。后续结合代码看下。
4.其他
补充两篇讲解LSTM和GRU的帖子,感觉讲的很清楚。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号