
【学习笔记】动态规划和k-means
1. 背景
跟踪学习某平台人工智能培训课程第二节课的内容,记一下笔记。本节内容主要包括两个小点:动态规划和kmeans两个小知识点,感觉更多的是讲了历史,并没有深入和细节探讨展开讲。
2. 案例
本讲的两个小案例分别是:1.木材售卖最大利益问题。木材不同长度对应了不同的价格,给定一个某长度的木材,如何切割,才能使得获利最大?2. k-means分析中国各城市能源站的地理位置。根据中国各个城市的地理经纬度位置,假设要建立 K 个能源站,使各个能源站距离各个城市位置最近,那么可能会在哪里呢?
2.1 dynamic programing
"""
业务背景:木材获利最大。给定一根长都为n的木材,最大能获利多少
长度: 1米 2米 3米 4米 5米 6米 。。。
价格: 1 5 8 9 10 17 。。。
解决思路:穷举。
将 n 对应的获利价格 记录下来 p1
将n分解为 n-1 1 能获利的值,添加到列表 p1, p2, ...
将n分解为 n-2 2 能获利的值,添加到列表 p1, p2, p3, ...
最后输出列表,最大值即可。
"""
# 假设各个长度对应的价格如下
prices = [1, 5, 8, 9, 10, 17, 17, 20, 24, 30, 33]
# 构造长度与价格的对应关系字典
complete_price = defaultdict(int)
for index, price in enumerate(prices):
complete_price[index + 1] = price
@lru_cache(maxsize=1024) # 提高效率,减少运行时间
def r(n):
candidates = [(complete_price[n], (n, 0))] # 0记录能获利的值,1记录切割方式
for i in range(1, n):
left = i
right = n - i
# total_r = complete_price[left] + complete_price[right]
total_r = r(left) + r(right)
candidates.append((total_r, (left, right)))
optimal, split = max(candidates)
solution[n] = split
return optimal
def parse_solution(n, cut_solution):
left, right = cut_solution[n] # 左 右 的切分方式
if left == 0 or right == 0:
return [left + right, ]
else:
return parse_solution(left, cut_solution) + parse_solution(right, cut_solution)
完成代码如下:
# coding=utf-8
from collections import defaultdict
from functools import lru_cache
prices = [1, 5, 8, 9, 10, 17, 17, 20, 24, 30, 33]
# 构造长度与价格的对应关系字典
complete_price = defaultdict(int)
for index, price in enumerate(prices):
complete_price[index + 1] = price
solution = {} # 记录如何切分?
@lru_cache(maxsize=1024)
def r(n):
candidates = [(complete_price[n], (n, 0))] # 0记录能获利的值,1记录切割方式
for i in range(1, n):
left = i
right = n - i
# total_r = complete_price[left] + complete_price[right]
total_r = r(left) + r(right)
candidates.append((total_r, (left, right)))
optimal, split = max(candidates)
solution[n] = split
return optimal
def parse_solution(n, cut_solution):
left, right = cut_solution[n] # 左 右 的切分方式
if left == 0 or right == 0:
return [left + right, ]
else:
return parse_solution(left, cut_solution) + parse_solution(right, cut_solution)
if __name__ == '__main__':
print(r(18), parse_solution(18, solution))
2.2 k-means
"""
业务背景:
给定各个城市的经纬度数据,利用k-means算法,计算k个能源中心的坐标
1. 数据处理
2. 迭代一次
3. while True迭代
"""
# 原始数据
coordination_source = """
{name:'兰州', geoCoord:[103.73, 36.03]},
{name:'嘉峪关', geoCoord:[98.17, 39.47]},
{name:'西宁', geoCoord:[101.74, 36.56]},
{name:'成都', geoCoord:[104.06, 30.67]},
{name:'石家庄', geoCoord:[114.48, 38.03]},
{name:'拉萨', geoCoord:[102.73, 25.04]},
{name:'贵阳', geoCoord:[106.71, 26.57]},
{name:'武汉', geoCoord:[114.31, 30.52]},
{name:'郑州', geoCoord:[113.65, 34.76]},
{name:'济南', geoCoord:[117, 36.65]},
{name:'南京', geoCoord:[118.78, 32.04]},
{name:'合肥', geoCoord:[117.27, 31.86]},
{name:'杭州', geoCoord:[120.19, 30.26]},
{name:'南昌', geoCoord:[115.89, 28.68]},
{name:'福州', geoCoord:[119.3, 26.08]},
{name:'广州', geoCoord:[113.23, 23.16]},
{name:'长沙', geoCoord:[113, 28.21]},
//{name:'海口', geoCoord:[110.35, 20.02]},
{name:'沈阳', geoCoord:[123.38, 41.8]},
{name:'长春', geoCoord:[125.35, 43.88]},
{name:'哈尔滨', geoCoord:[126.63, 45.75]},
{name:'太原', geoCoord:[112.53, 37.87]},
{name:'西安', geoCoord:[108.95, 34.27]},
//{name:'台湾', geoCoord:[121.30, 25.03]},
{name:'北京', geoCoord:[116.46, 39.92]},
{name:'上海', geoCoord:[121.48, 31.22]},
{name:'重庆', geoCoord:[106.54, 29.59]},
{name:'天津', geoCoord:[117.2, 39.13]},
{name:'呼和浩特', geoCoord:[111.65, 40.82]},
{name:'南宁', geoCoord:[108.33, 22.84]},
//{name:'西藏', geoCoord:[91.11, 29.97]},
{name:'银川', geoCoord:[106.27, 38.47]},
{name:'乌鲁木齐', geoCoord:[87.68, 43.77]},
{name:'香港', geoCoord:[114.17, 22.28]},
{name:'澳门', geoCoord:[113.54, 22.19]}
"""
# 对数据进行预处理
def data_process(source_data):
line_list = source_data.split('\n')
city_location = {}
for line in line_list:
if line.strip():
pattern = r"name:'(.*?)', geoCoord:\[(.*?)]"
city, info = re.findall(pattern, line)[0]
lon, lat = [i.strip() for i in info.split(',')]
city_location[city] = (float(lon), float(lat))
return city_location
定义共组组件
# 1.随机生成聚类中心点
def get_random_center(all_x, all_y):
center_x = random.uniform(min(all_x), max(all_x)),
center_y = random.uniform(min(all_y), max(all_y))
return center_x, center_y
# 2. 计算球面上两个点的距离
def get_geo_distance(origin, destination):
lon1, lat1 = origin
lon2, lat2 = destination
radius = 6371
distance_lat = math.radians(lat2 - lat1)
distance_lon = math.radians(lon2 - lon1)
a = (
math.sin(distance_lat / 2) * math.sin(distance_lat / 2) +
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
math.sin(distance_lon / 2) * math.sin(distance_lon / 2)
)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
d = radius * c
return d
聚类分析
# 一次迭代的过程
def iterate_once(centers, closest_point, threshold):
flag_changed = False
for c in closest_point:
former_center = centers[c] # 当前聚类中心点
neighbors = closest_point[c] # 各个聚类中心下的数据点
# 新的聚类中心点
neighbors_center = np.mean(neighbors, axis=0)
# 判断是否要更新聚类中心
if get_geo_distance(former_center, neighbors_center) > threshold:
centers[c] = neighbors_center
flag_changed = True # 大于阈值,更新
return centers, flag_changed
# 程序聚类的主函数
def kmeans_(X, k, threshold=5):
all_x = X[:, 0]
all_y = X[:, 1]
# 聚类中心个数
K = k
# 1. 初始化k个聚类中心
centers = {(i+1): get_random_center(all_x, all_y) for i in range(K)}
flag_changed = True
while flag_changed:
closest_point = defaultdict(list)
for x, y in zip(all_x, all_y):
# 计算每个点(x, y)到各个聚类中心的距离
distance_centers = [(i, get_geo_distance((x, y), centers[i])) for i in centers]
closest_center, closest_distance = min(distance_centers, key=lambda x: x[1])
# 将各个点,添加到对应聚类中心的列表
closest_point[closest_center].append([x, y])
# 迭代一次,判断是否需要更新
centers, flag_changed = iterate_once(centers, closest_point, threshold)
print('iterating ...')
结果展示:
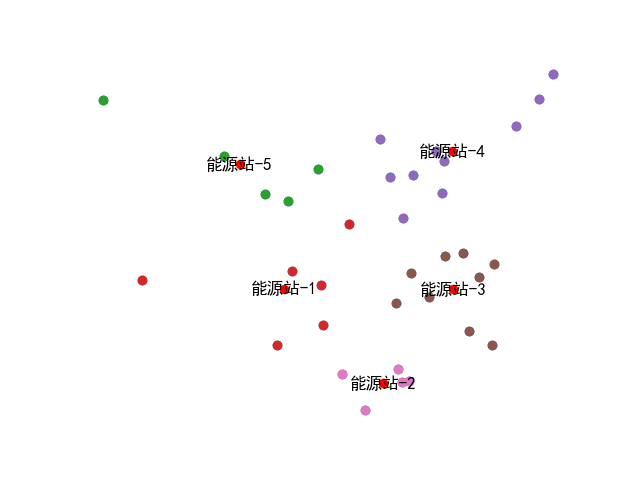
完整代码如下:
# coding=utf-8
import re
import numpy as np
import random
from collections import defaultdict
import math
import matplotlib.pyplot as plt
import networkx as nx
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
def data_process(source_data):
line_list = source_data.split('\n')
city_location = {}
for line in line_list:
if line.strip():
pattern = r"name:'(.*?)', geoCoord:\[(.*?)]"
city, info = re.findall(pattern, line)[0]
lon, lat = [i.strip() for i in info.split(',')]
city_location[city] = (float(lon), float(lat))
return city_location
def get_random_center(all_x, all_y):
center_x = random.uniform(min(all_x), max(all_x)),
center_y = random.uniform(min(all_y), max(all_y))
return center_x, center_y
def get_geo_distance(origin, destination):
# 计算球面上两个点的距离
lon1, lat1 = origin
lon2, lat2 = destination
radius = 6371
distance_lat = math.radians(lat2 - lat1)
distance_lon = math.radians(lon2 - lon1)
a = (
math.sin(distance_lat / 2) * math.sin(distance_lat / 2) +
math.cos(math.radians(lat1)) * math.cos(math.radians(lat2)) *
math.sin(distance_lon / 2) * math.sin(distance_lon / 2)
)
c = 2 * math.atan2(math.sqrt(a), math.sqrt(1 - a))
d = radius * c
return d
def iterate_once(centers, closest_point, threshold):
flag_changed = False
for c in closest_point:
former_center = centers[c] # 当前聚类中心点
neighbors = closest_point[c] # 各个聚类中心下的数据点
# 新的聚类中心点
neighbors_center = np.mean(neighbors, axis=0)
# 判断是否要更新聚类中心
if get_geo_distance(former_center, neighbors_center) > threshold:
centers[c] = neighbors_center
flag_changed = True # 大于阈值,更新
return centers, flag_changed
def kmeans_(X, k, threshold=5):
all_x = X[:, 0]
all_y = X[:, 1]
# 聚类中心个数
K = k
# 1. 初始化k个聚类中心
centers = {(i+1): get_random_center(all_x, all_y) for i in range(K)}
flag_changed = True
while flag_changed:
closest_point = defaultdict(list)
for x, y in zip(all_x, all_y):
# 计算每个点(x, y)到各个聚类中心的距离
distance_centers = [(i, get_geo_distance((x, y), centers[i])) for i in centers]
closest_center, closest_distance = min(distance_centers, key=lambda x: x[1])
# 将各个点,添加到对应聚类中心的列表
closest_point[closest_center].append([x, y])
# 迭代一次,判断是否需要更新
centers, flag_changed = iterate_once(centers, closest_point, threshold)
print('iterating ...')
# 可视化展示
view_ = True
if view_:
plt.scatter(all_x, all_y)
plt.scatter(*zip(*centers.values()))
# plt.show()
for c, points in closest_point.items():
plt.scatter(*zip(*points))
# plt.show()
city_location_with_station = {f'能源站-{i}': position for i, position in centers.items()}
city_graph = nx.Graph()
city_graph.add_nodes_from(list(city_location_with_station.keys()))
nx.draw(city_graph, city_location_with_station, node_color='red', with_labels=True, node_size=30)
plt.show()
def main():
# 1. 数据预处理
city_location = data_process(coordination_source)
# 2. k-means处理
data = np.array(list(city_location.values()))
kmeans_(data, k=5, threshold=5)
if __name__ == '__main__':
main()
3. 总结
- 动态规划的过程,本质离不开递归迭代;而递归的首要是要设置终点,即何时停止递归?案例中,两个递归的点,停止迭代的条件设置很巧妙。
kmeans聚类分析的案例中,聚类停止条件是:原有的聚类中心,与新的聚类中心的距离 是否满足阈值条件。
4. 其他
- 后续再补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号