
记Python2.7的一次编解码问题解决
起因:
在pycharm运行脚本的时候,发现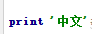 中文字符在控制台输出显示成乱码了。
中文字符在控制台输出显示成乱码了。 。
。
各种百度,查解决方法,误打误撞的发现加个u可以解决乱码问题,其实没有真的懂为什么。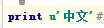
之后就像个抄作业的学渣,就知道“三长两短,选最长”那样,反正遇到要输出中文,管他三七二十一,通通加上u。
但是,把脚本放Linux上,在后台运行时就妥妥的报错了。。。
于是再次走上各种查资料,解决编码问题之路:
1.在脚本的开头加上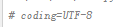 ,意思是源程序用utf-8进行编码。
,意思是源程序用utf-8进行编码。
2.的‘中文’,此时还是utf-8编码。而的u'中文',已经解码成Unicode了,即 print u‘中文’等效于print ‘中文’.decode('utf-8')。
3.在终端运行的时候,输出是按sys.stdout.encoding设置的进行编码。
如果是后台运行,对于字符串‘中文’,还是按照脚本开头声明的utf-8来进行编码。u'中文',由于是Unicode,则按sys.getdefaultencoding()设置的进行编码。
4.Windows上:
sys.stdout.encoding的编码是cp936,即类似gbk的编码。
sys.getdefaultencoding()的编码是ascii,
Linux上:
sys.stdout.encoding的编码是utf-8,
sys.getdefaultencoding()的编码也是ascii,
5.所以,,在终端运行的时候,是将Unicode字符串 用cp936或者utf-8进行编码,且在编码范围内,能正确输出。
用cp936或者utf-8进行编码,且在编码范围内,能正确输出。
但是,后台运行的话,用的是ascii编码,超出了ascii的编码范围,就报错了。
解决:
方法一:
更改sys.setdefaultencoding的默认编码,脚本加上:
reload(sys)
sys.setdefaultencoding('utf-8')
但是不推荐,原因详解:https://blog.ernest.me/post/python-setdefaultencoding-unicode-bytes
方法二:
将已经解码成Unicode的字符串指定正确的编码方式.
print u'中文'.endoce('utf-8')
其他乱七八糟的尝试:
1.在后台执行的时候,查看进程运行情况。其中,运行第一个脚本时,没有报错,而第二个报错了。
看起来都是root来执行脚本的,

执行脚本时的当前目录和使用的解释器也一样

2.所以又回到脚本文件本身来查找原因,
发现,第一个脚本文件导入的模块中,有一个自定义模块是用方法一 ,更改了Python的系统默认编码,所以没有报错。
,更改了Python的系统默认编码,所以没有报错。
而第二个脚本中,是没有导入这个自定义模块的。所以此时还是用ascii来对Unicode字符串进行编码的。
参考资料:
https://www.jianshu.com/p/b1fd7575db08
https://liujiacai.net/blog/2016/06/30/python2-encoding/
http://xnerv.wang/all-truths-about-python-encoding-problem/
https://blog.csdn.net/liuyukuan/article/details/50855748

 浙公网安备 33010602011771号
浙公网安备 33010602011771号