论文解读: Model Pruning Enables Efficient Federated Learning on Edge Devices
一、PruneFL出发点(解决的问题)
1、减少通信量以及计算开销,
2、在保持精度的同时最小化联邦训练的总体时间
在合理的时间和精力内训练模型
二、简介
pruneFL作为联邦学习与模型剪枝相结合的一种新的范式,,主要有以下两个部分:
a)distributed prunning
分为两个stage,用户本地的初始修剪,之后再于标准FL算法交织训练;(为保证初始修剪得有效性,用的思想是基于彩票假设的剪枝算法模型【sinp、SynFlow等】)
b)adaptive Pruning
在交织训练的过程中,提高模型剪枝的有效性,保持精度的同时,添加约束让模型最小化训练的时间,这个过程中获得的任何一个小模型都是原始模型的一张彩票。
三、相关工作
1、模型剪枝
模型剪枝常用的方法:
a)基于参数的
1)在预训练后的网络中,将对模型影响不大的参数剪调。
2)彩票假设,在网络训练之前进行剪枝得到的子网络就可以达到与原始网络相似的精度。
彩票对于在不同但相似的数据集上重新训练修剪后的模型很有用。
b)基于网络结构的
本文解决了模型尺寸的自动调整问题(根据时间)
2、高效的联邦学习
基于全局联邦的方式,大多联邦学习算法都还处于实验仿真阶段,本文在嵌入式设备上实现了联邦学习的模型剪枝。
本文是基于FedAvg的扩展
四、文章的实现
PruneFL方法包括两个阶段:在选定的客户机上进行初始修剪,以及在FL过程中涉及服务器和客户机的进一步修剪。初始修剪可以在具有相对较高计算能力的单个客户机上使用有偏差的数据进行,进一步的修剪阶段将“消除”偏差并优化模型


为了减少通信量:
在经验损失的估计中,参数w的更新可以表示为:
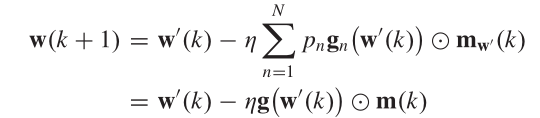
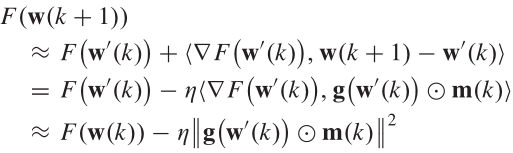
在时间约束上:
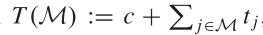
由于\(\Delta M\)受上面训练的约束,故而在加入时间约束上要满足:
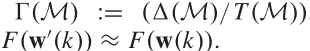
此时整个网络的优化问题变为:
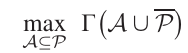
最后文章做了收敛性说明。
