Federated meta learning
一、MAML
1、示意图:
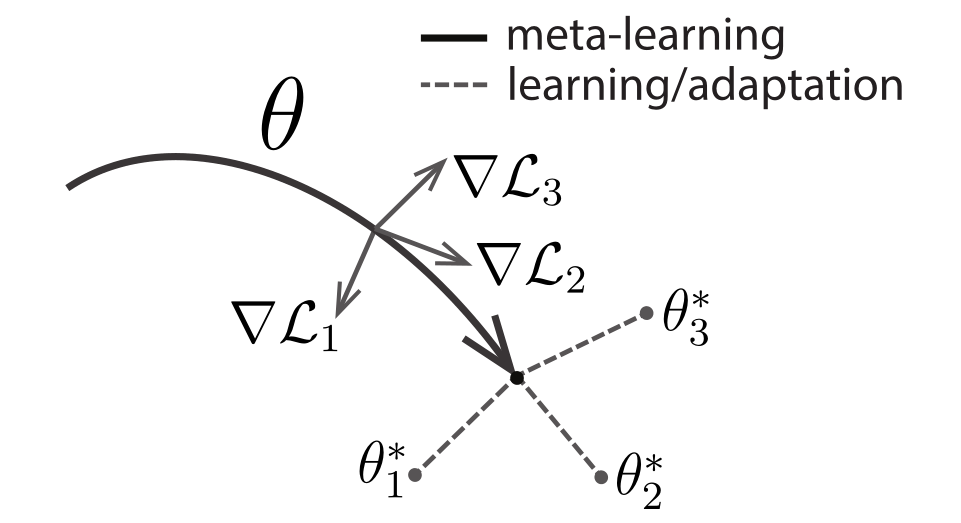
\(\theta_i^*\) 表示不同任务的适应参数,\(\nabla L_i\)表示不同任务上的梯度方向
2、算法:

在每个不同的任务上,使用自己任务的support set对全局的参数\(\theta\) 进行梯度更新(类似微调),并保存各个任务在query set 上的loss function。其和用于更新meta 网络的参数。
二、Meta-SGD
1、示意图:
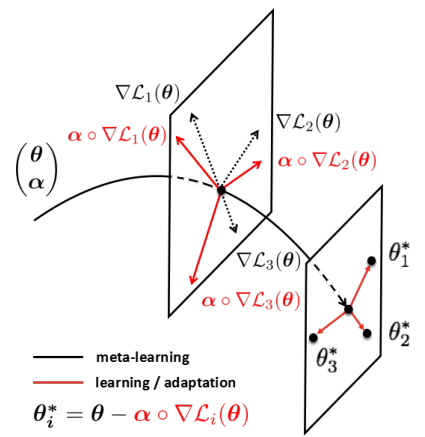
\(\alpha \circ \nabla L_i(\theta)\)的方向表示task上的参数更新的方向,大小表示学习率,\(\alpha\)的大小维度与\(\theta\)一致,\(\circ\)表示element-wise product,例如: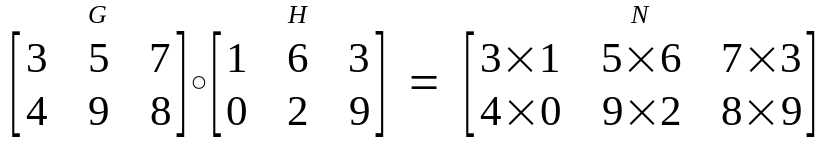
优化了MAML上的梯度更新上可能没办法达到任务最佳参数的问题,\(\alpha 、\theta\)为可学习参数。在inner update时需要更新,在outer也需要聚合更新。
2、算法:

Meta-SGD相比与MAML,增加了用户更新方向的信息,从而提高了准确度
3、更新过程:
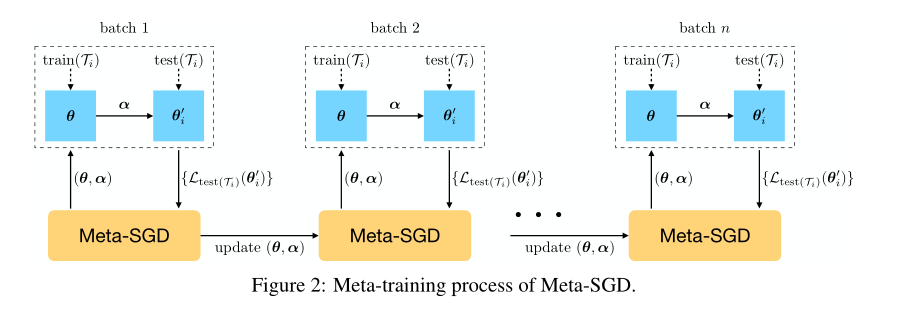 这里的test set 以及train set 应该对应上面说的train set中每个任务中包括的support set 以及query set,其中在每个任务中只需要更新一次的梯度
这里的test set 以及train set 应该对应上面说的train set中每个任务中包括的support set 以及query set,其中在每个任务中只需要更新一次的梯度
三、FedMeta
元学习中的每一个task可以看作是数据分布不同的每个client成员,将元学习应用到个性化联邦中,有利于client端更好得提高精度,收敛速度以及减小通信量。这篇论文就是将元学习中经典的两种算法,应用于联邦学习。
1、Framework:
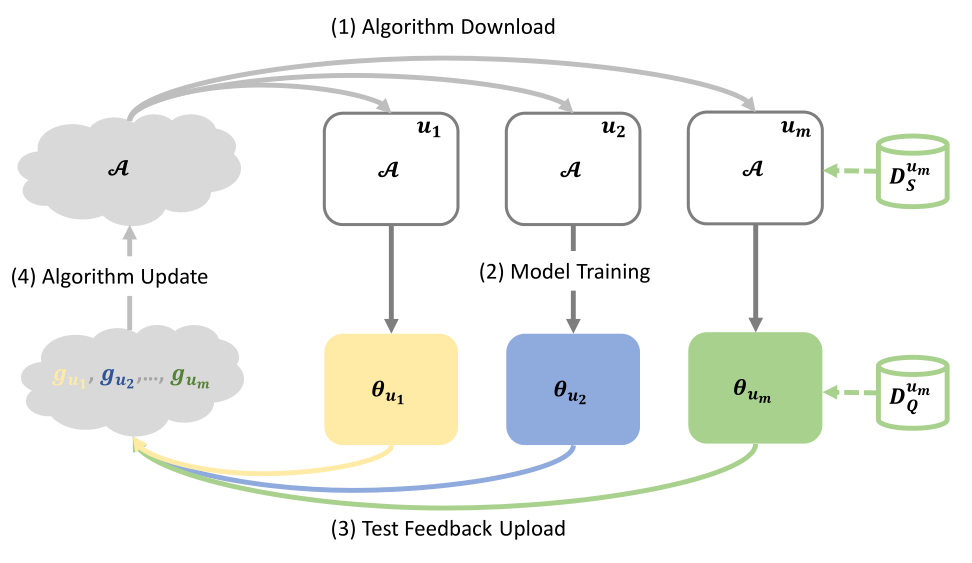
2、算法:

client上传test loss(query set上的loss),在server端聚合并更新参数
四、Meta-Backward:Energy-Efficient Federated
1、理论推导:
对比于MAML以及iMAML算法,这篇文章采用了一种反向的思路以及求解方法,换了一个角度减少了计算量以及通信的次数,从而达到了节能的效果。
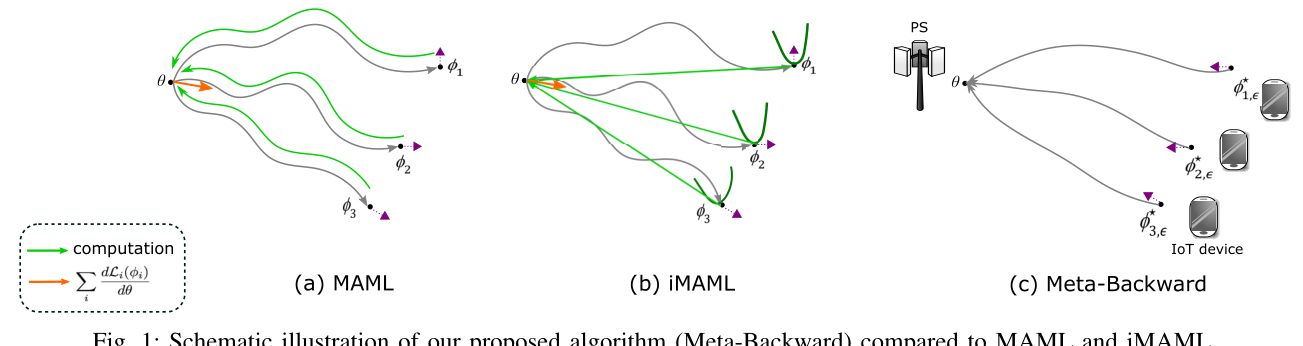
文章假设了,如果本地客户端(or task)已经训练好了一个loss比较小的参数,那么全局参数与客户端的关系应该表示为:
其中\(\phi_{i,\epsilon}^\ast\)表示用户(task)本地训练k次后与全局最优解的差值为一个趋近于0的小量\(\epsilon\)对应的权重,由逆向考虑,全局的参数产生的loss应该与其本地训练好的权重长生的loss相近,但并不要求其gradient要一致。
用贪婪算法求解(1)、(2)两个式子,可以公式化为:
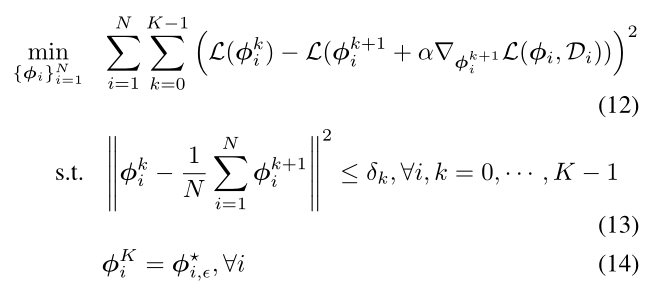
其中$\theta = \frac1 N \sum_{i=1}^N \phi_i^0 ;; ,\delta_0 \le \delta_1 \le ...\le \delta_k-1, ; when; \delta_k \rightarrow 0, ; \phi_i^0 \rightarrow \theta, ; \forall i $
上式之间的关系可以表示为:
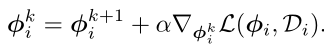
但由于需要迭代求解,进行backword computation,所以这个式子中的梯度就不能被计算,所以用$$\phi_i^k = \phi_i^{k+1} +\alpha \nabla_{\phi_i^{k+1}}L(\phi_i,D_i)$$来代替上面的式子
接下来就是解这个最优化问题(可以跳过):
定义约束条件为一个set:
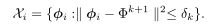
再定义一个function,用于描述全局参数与约束之间的关系:
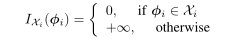
- 所以目标函数可以改写为:
![image]()
其中\(f_i(\phi_i)\)表示为:
![image]()
- 用投影梯度下降法,求解这个目标函数的最优解:
(1)先用下式将\(\phi_i^{k,0}\)投影到可行集中:
![image]()
(2)迭代更新,(只需要少数次的迭代次数就能达到很好的效果)
![image]()
- 最后这个loss function用拉格朗日方程表示为
![image]()
- 所以K.K.T条件以及求解:
![image]()
![image]()
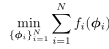
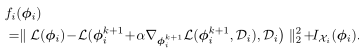
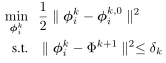
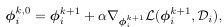
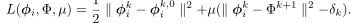
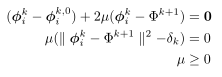

2、算法:

五、Per-FedAvg
这一篇也是基于MaMl的联邦学习,目的是找到一个共享的全局模型,能训练一次或几次,就能对新用有比较优秀的表现,并证明了用户数据分布的差异对于算法性能的影响。
1、证明任务相似度与分布距离的关系
使用了Total Variation(TV)distance,以及1-Wasserstein Distance,证明了在分布情况不变的情况下,算法的正确性是相对不变的。
在我理解这一部分就是在说,分布会影响算法的性能,所以权衡是比较难的,个个性化联邦是需要的
证明过程:


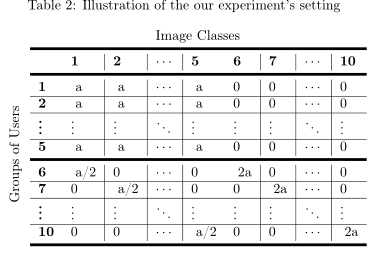
- 构造的数据分布,如下:
![image]()
2、算法:

这个算法的表格参数很多,简单介绍一下:
头带~的参数为client本地的一些参数,没有的是全局的参数,定义\(F(w)\)表示client端的meta-function \(F_1,F_2,...F_i\)的平均,其中当本地只更新一次时,\(F_i(W)\)的定义如下:
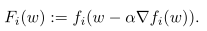
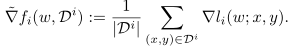
所以其梯度表示为:
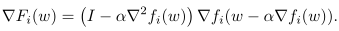
\(\tilde\nabla f_i(w, D^i)\)中\(D^i\)表示用户的数据集,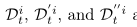 是相互独立的数据集部分,关系如下:
是相互独立的数据集部分,关系如下:
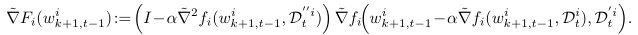
由于per-FedAvg含有Hessien阵,在实验部分,作者引入两种简化计算的方法:

这个算法和FedMate很像,再把它搬过来对比一下,(感觉就是在client端更新的时候用的数据集不同?还是我理解的不够深刻?)
参考文献:
[1]Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 (ICML'17)
[2]Li, Z., Zhou, F., Chen, F., & Li, H. (2017). Meta-SGD: Learning to Learn Quickly for Few Shot Learning. ArXiv, abs/1707.09835.
[3]Wang, Y., Wu, X., Li, Q., Gu, J., Xiang, W., Zhang, L., & Li, V.O. (2018). Large Margin Few-Shot Learning. ArXiv, abs/1807.02872.
[4]A. Elgabli, C. B. Issaid, A. S. Bedi, M. Bennis and V. Aggarwal, "Energy-Efficient and Federated Meta-Learning via Projected Stochastic Gradient Ascent," 2021 IEEE Global Communications Conference (GLOBECOM)
[5]Fallah, A., Mokhtari, A., & Ozdaglar, A.E. (2020). Personalized Federated Learning: A Meta-Learning Approach. ArXiv, abs/2002.07948.
(文中引用:
[33] A. Fallah, A. Mokhtari, And A. Ozdaglar, “On The Convergence Theory Of Gradient-Based Model-
Agnostic Meta-Learning Algorithms,” In International Conference On Artificial Intelligence And
Statistics, Pp. 1082–1092, 2020.
[34] F. Chen, M. Luo, Z. Dong, Z. Li, And X. He, “Federated Meta-Learning With Fast Convergence
And Efficient Communication,” Arxiv Preprint Arxiv:1802.07876, 2018.)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号