Personalized Federated Learning using Hypernetworks 论文解读
pFedHN
文章的主要贡献
(1)提出了新的基于Hypernetworks的个性化联邦学习
(2)模型的泛化能力强,对于新用户也能有良好的表现
(3)对于拥有不同的计算资源的客户端能有一个适配的不同大小的模型
idea
使用embedding层,根据id生成一个 vector Vi,成为超网络的传入参数,embedding的权重可以是可训练参数也可以是固定的。使得网络输出能够根据网络的输入而改变,主网络布在client端,从而对不同的client有着很好的性能,且对于Novel client也能有很好的适应性。
超网络(hypernetwork)是谷歌在16年提出的一种网络,普通的网络是直接输出是我们想要的结果,而超网路的输出是另一个主网络B的权重,主网络B加载超网络学习到的权重之后,就能输出我们想要的结果了。通常超级网络的权重数是小于网络B的权重数量的>
这个思想应用于联邦学习则允许超网络可以大一些负责一部分的运算量,在client端层数可以少一些,增加一个本地的个性化分类层来解决数据异构问题。
https://blog.csdn.net/weixin_42419002/article/details/104012165
网络框架:
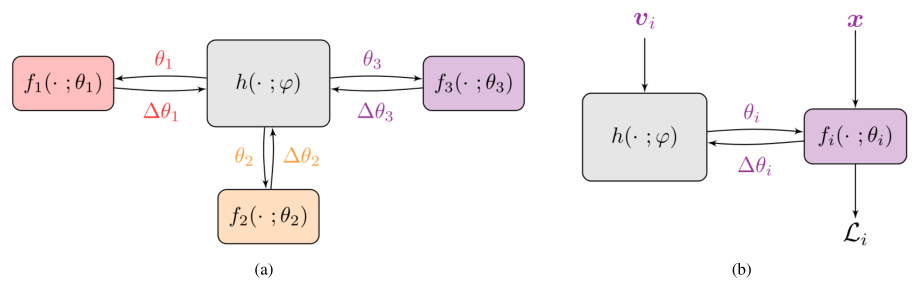
\(f_i(\).\(;\theta_1)\)表示client端的target network参数函数,
\(h(\).\(;\psi)\)表示server端hypernetwork的参数函数,
交换参数\(\theta_i\)为传输的参数,其怎么来的,下面是公式的推导: PFL的目标函数: $$arg_{\psi,v_1,...,v_n}min \frac{1}{n}\sum_{i=1}^n L_i(h(v_i;\psi))$$ 其中的参数: $$\theta_i=h(v_i;\psi)$$ client端的loss function:
由链式法则可将client与server端的参数解耦:
所以client只需要向server端传输 \(\nabla_{\theta_i}L_i\)
\(\psi\)的更新通过以下原则 $$\Delta\psi =(\nabla_\psi \theta_i)^T \Delta\theta_i$$
其中 \(\Delta\theta_i= \hat{\theta_i}-\theta_i\)更新子sever端

初始化的时候,client端加载来自server端发来的权重,\(\theta_i=h(v_i;\psi)\)
之后Target network转载权重后再本地训练,自行更新参数,把梯度回传后求一个\(\Delta\theta_i\)用于更新\(\psi\)以及\(v_i\).
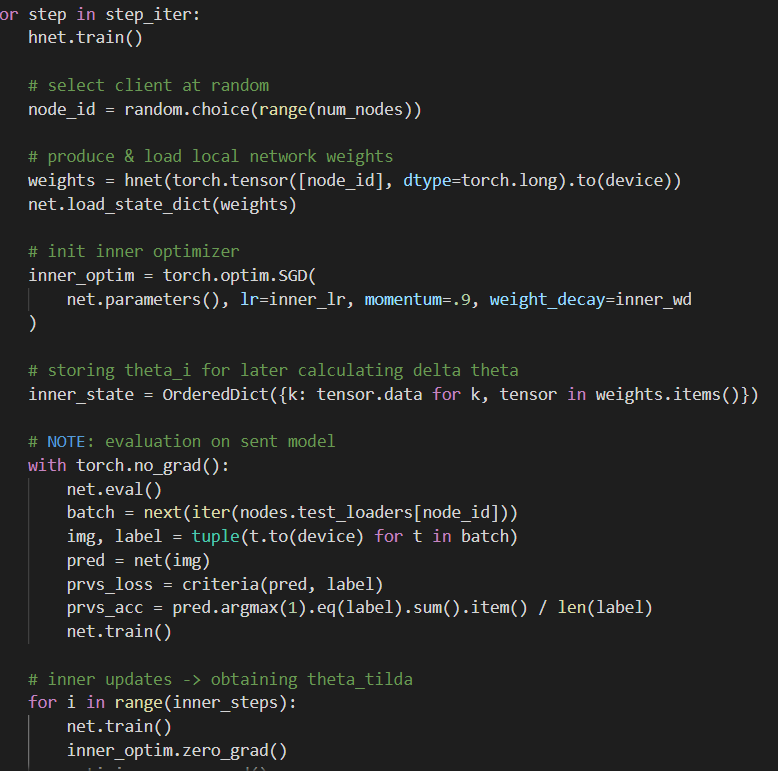
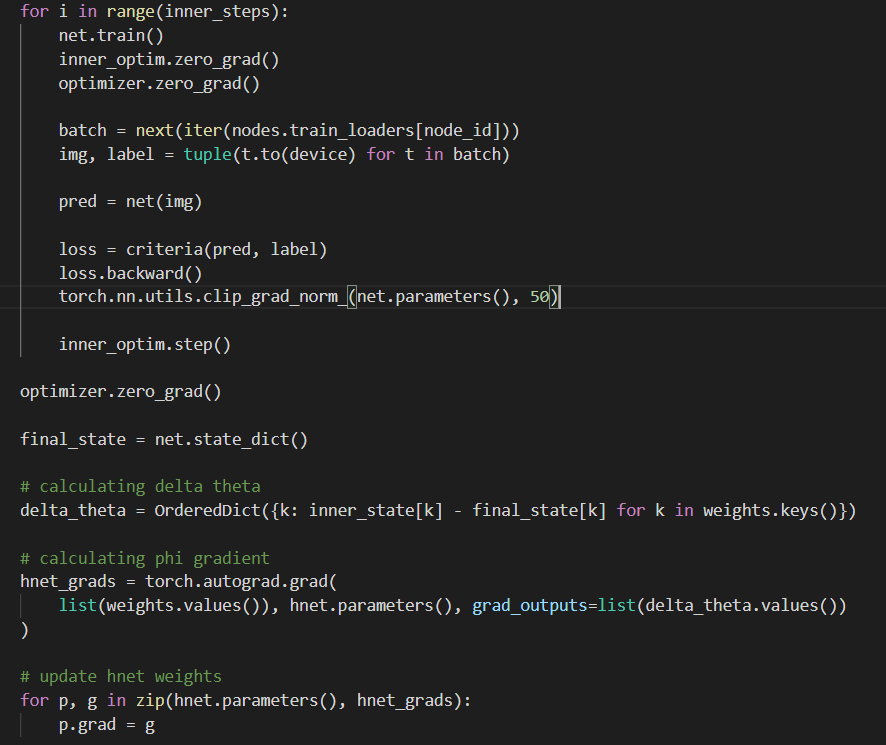

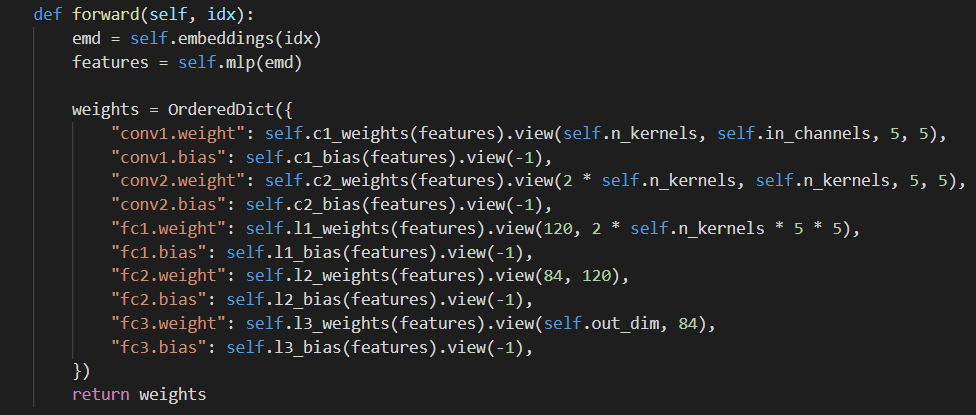
client端的初始化权重对应的字典,每个值都由一个线性层产生。
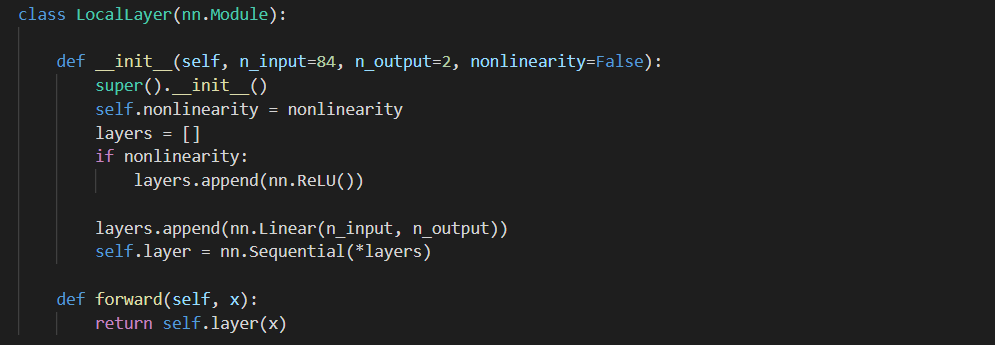
对于分类层,由于client端数据的异构性,所以也采用Hypernetworks来为不同的用户产生不同的output 在上面的基础上,建模为: $$arg_{\psi,v_1,...,v_n,w_1,...,w_n} \frac{1}{n}\sum_{i=1}^n L_i(\theta_i,w_i)$$ 在client端本地更新: $$w_i = w_i-\alpha\nabla_{w_i} L_i$$
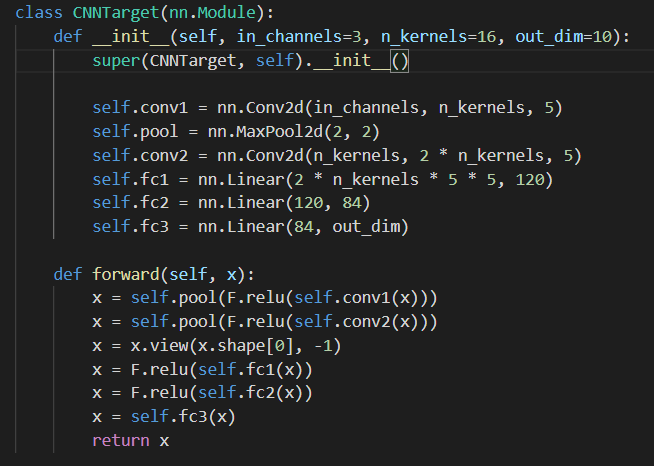
个性化层:
实验部分
- Compared Methods:
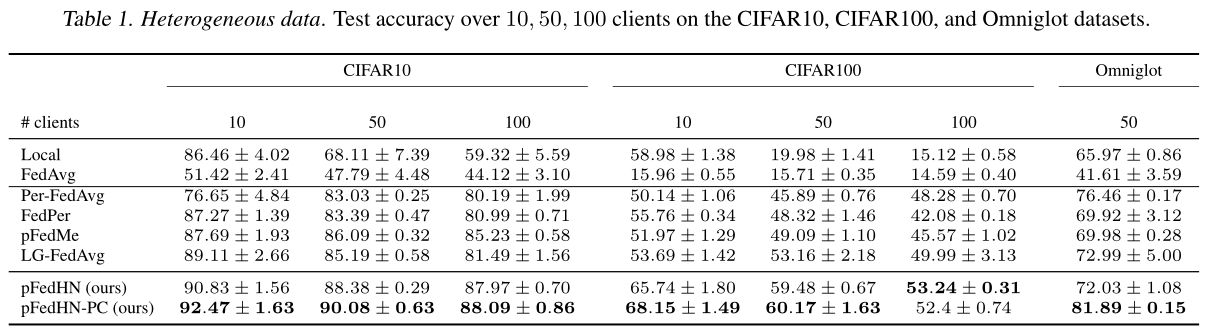
- Computation Budget:
FL需要考虑设备的异构性问题, 文中提出pFedHN能够适应不同的输入,由此将client分为3种equal-sizes group (S、M、L)local Model,其参数量是不一样的,但其共享同一个Global Model。 - 对Novel Clients:
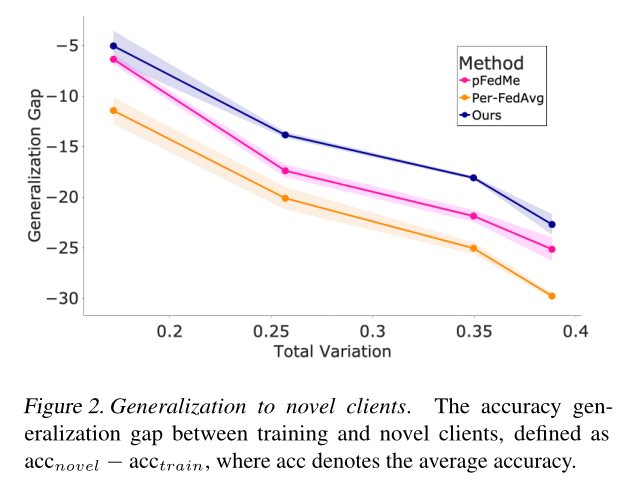
- Heterogeneity of personalized classifiers
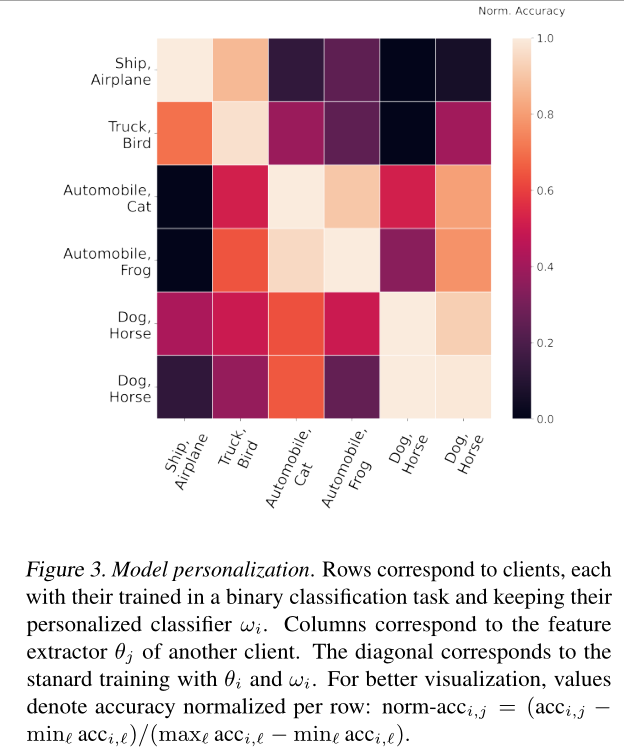
小结
即用线性网络训练的权重(HyperNetwork)与本地的卷积网络的权重, 不停装载交替更新着本地对server端的影响只有一个\(\Delta \theta_i\)
