
【Hadoop】3.3.1版本部署
硬件环境:
虚拟机环境配置
硬件:1CPU + [RAM]4G + [DISK]128G
系统:Centos7 x64
这里没有像尚硅谷一样做地址映射解析,直接取IP(我太懒)
192.168.242.131 192.168.242.132 192.168.242.133
前置依赖环境:
前置环境准备(3台机器都需要):
sudo yum install -y net-tools sudo yum install -y vim sudo yum install -y wget sudo yum install -y lrzsz sudo yum install -y pcre pcre-devel sudo yum install -y zlib zlib-devel sudo yum install -y openssl openssl-devel sudo yum install -y unzip sudo yum install -y libtool sudo yum install -y gcc-c++ sudo yum install -y telnet sudo yum install -y tree sudo yum install -y nano sudo yum install -y psmisc sudo yum install -y rsync sudo yum install -y java-1.8.0-openjdk-devel.x86_64
1号机(192.168.242.131)的安装过程
下载Hadoop包(1号机,可以任意一台):
如果是其他版本,注意文件路径和脚本编写的时候,要及时替换过来
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
(可选)用scp命令传输到其他机器上备份:
# 例如1号机下载的,就需要传输到2号机和3号机 scp ~/hadoop-3.3.1.tar.gz root@192.168.242.132:/root/ scp ~/hadoop-3.3.1.tar.gz root@192.168.242.133:/root/
解包到指定【 opt/module/ 】目录(1号机)
mkdir -p /opt/module/ tar -zxvf hadoop-3.3.1.tar.gz -C /opt/module/
配置Hadoop + Jdk的环境变量(1号机)
vim /etc/profile.d/my_env.sh =====添加下面内容===== # HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin # JDK变量 JAVA_HOME export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64 export PATH=$PATH:$JAVA_HOME/bin
将环境变量加入进来,立即生效(1号机)
source /etc/profile
检查(1号机)是否安装成功?
hadoop version
3.3.1版本,我这里展示的信息
[root@localhost ~]# hadoop version Hadoop 3.3.1 Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2 Compiled by ubuntu on 2021-06-15T05:13Z Compiled with protoc 3.7.1 From source with checksum 88a4ddb2299aca054416d6b7f81ca55 This command was run using /opt/module/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar
集群部署的前置准备
一、编写集群分发脚本
在【 /usr/bin/ 】目录下面创建xsync命令脚本(1号机)
vim /usr/bin/xsync
脚本代码:
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in 192.168.242.131 192.168.242.132 192.168.242.133 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
注意 保存后需要给予【可执行】的权限
chmod +x /usr/bin/xsync
这里补充下信息
在视频演示和文档中放置的位置是在用户的bin目录下 ( /root/bin 非root用户是 /home/用户名/bin)
且不存在该目录,需要自行创建
原因是全局PATH变量有指向这个路径(猜测)
[root@localhost ~]# echo $PATH /usr/local/sbin:/usr/local/bin:
/usr/sbin:
/usr/bin:
/opt/module/hadoop-3.3.1/bin:
/opt/module/hadoop-3.3.1/sbin:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64/bin:
/root/bin
测试xsync命令是否可用?
把1号机配置的环境变量文件同步到其他机器上
xsync my_env.sh # sudo 执行时要求文件路径必须是完整的 sudo xsync /etc/profile.d/my_env.sh
此时每一次机器scp的传输都会要求输入登陆账号和密码,
传输完成后检查目标机器上路径是否存在这个文件
二、免登录处理—生成SSH密钥
切换到当前用户(root)目录下的.ssh隐藏目录(每一台机器都执行)
cd ~/.ssh
执行密钥生成命令
三个设置项都直接按回车确认 (每一台机器都执行)
ssh-keygen -t rsa
过程展示:
[root@localhost .ssh]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:3rFBbU4jq2Y6HepDVxJDZEwuldF1NpFzWTWn9Sgc/dQ root@localhost.localdomain The key's randomart image is: +---[RSA 2048]----+ | =B+ .o.=+X| | += .o ++*E| | . .oo B o=.| | ....* o .| | So+ . | | ..oo + | | . +=.o | | ++. | | .oo | +----[SHA256]-----+
生成之后的.ssh目录
[root@localhost .ssh]# ll -a 总用量 12 drwx------. 2 root root 57 1月 28 15:03 . dr-xr-x---. 4 root root 201 1月 28 14:33 .. -rw-------. 1 root root 1675 1月 28 15:03 id_rsa -rw-r--r--. 1 root root 408 1月 28 15:03 id_rsa.pub -rw-r--r--. 1 root root 531 1月 28 14:39 known_hosts
可以看到两个文件 【id_rsa】 和 【id_rsa.pub】
不带pub的是私钥,用于其他机器访问本机校验
pub后缀的就是公钥,用于登陆其他机器校验用的
known_hosts 文件是之前操作scp命令访问过其他机器的ip遗留的公钥信息
举个例子:
A、B 2台机器
A 想不输入密码就登陆B,B就需要知道A的账号信息,就需要把A的公钥放到B的机器中去
反之B登陆A就需要B的公钥在A里面存在
每台机器都需要其他机器的公钥,包括自己的
1号机的公钥给2号机和3号机,自己的加入到授权key中
ssh-copy-id 192.168.242.132 ssh-copy-id 192.168.242.133 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
2号机给1和3,自己加入
ssh-copy-id 192.168.242.131 ssh-copy-id 192.168.242.133 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3号机同理
ssh-copy-id 192.168.242.131 ssh-copy-id 192.168.242.132 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
参考:
https://blog.csdn.net/sinat_35821976/article/details/99939757
集群部署
一、资源规划
建议: NameNode \ ResourceManager \ SecondaryNameNode 三者独立机器部署
原因:硬件资源占用大
资源分配:
1号机 放 NameNode,2号机放 ResourceManager ,3号机放 SecondaryNameNode
二、配置文件编写(1号机)
首先备份需要更改的文件
cp -r $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml.bak cp -r $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml.bak cp -r $HADOOP_HOME/etc/hadoop/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml.bak cp -r $HADOOP_HOME/etc/hadoop/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml.bak
下面放开手脚改配置文件
1、core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定 NameNode 的地址 因为是集群地址,集群都指向这个地址节点 --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.242.131:8020</value> </property> <!-- 指定 hadoop 数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.3.1/data</value> </property> <!-- 配置 HDFS 网页登录使用的静态用户为 atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
2、hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- nn web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>192.168.242.131:9870</value> </property> <!-- 2nn web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.242.133:9868</value> </property> </configuration>
3、mapred-site.xml
下面的环境变量似乎不需要添加...
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.1</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.1</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.3.1</value> </property> </configuration>
4、yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.242.132</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
声明workers文件
注意workers文件不能有多余的空格和空行!
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
===== 文件信息 =====
192.168.242.131
192.168.242.132
192.168.242.133
然后同步到其他机器上面
xsync /opt/module/hadoop-3.3.1/etc/hadoop
Hadoop集群启动
因为没有像尚硅谷教程那样专门设置hadoop程序的专属执行用户
这里要对启动脚本增加执行参数
未设置则会出现这个错误,解决方案也是从这获取的
https://blog.csdn.net/hongxiao2016/article/details/88903289/
1号机打开脚本,在最头上加上这些信息( #!/usr/bin/env bash 的下面)
【/opt/module/hadoop-3.3.1/sbin/start-dfs.sh 】
【/opt/module/hadoop-3.3.1/sbin/stop-dfs.sh】
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
【/opt/module/hadoop-3.3.1/sbin/start-yarn.sh 】
【/opt/module/hadoop-3.3.1/sbin/stop-yarn.sh】
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
同步到其他机器上面:
xsync /opt/module/hadoop-3.3.1/sbin
然后由1号机启动hdfs,2号机启动yarn
1号机首次启动之前进行格式化处理:
hdfs namenode -format
如果后面需要重新格式化启动的,需要先删除 data目录 + logs目录(1号机)【待验证】?
启动HDFS
$HADOOP_HOME/sbin/start-dfs.sh
启动之后成功的信息:
[root@localhost ~]# /opt/module/hadoop-3.3.1/sbin/start-dfs.sh WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER. Starting namenodes on [192.168.242.131] 上一次登录:五 1月 28 18:30:20 CST 2022pts/1 上 Starting datanodes 上一次登录:五 1月 28 18:30:43 CST 2022pts/1 上 Starting secondary namenodes [192.168.242.133] 上一次登录:五 1月 28 18:30:45 CST 2022pts/1 上 [root@localhost ~]#
2号机启动YARN
$HADOOP_HOME/sbin/start-yarn.sh
启动后成功的信息:
[root@localhost ~]# /opt/module/hadoop-3.3.1/sbin/start-yarn.sh Starting resourcemanager 上一次登录:五 1月 28 18:30:38 CST 2022pts/0 上 Starting nodemanagers 上一次登录:五 1月 28 18:31:09 CST 2022pts/0 上 [root@localhost ~]#
访问之前关闭防火墙(所有机器执行)
systemctl stop firewalld
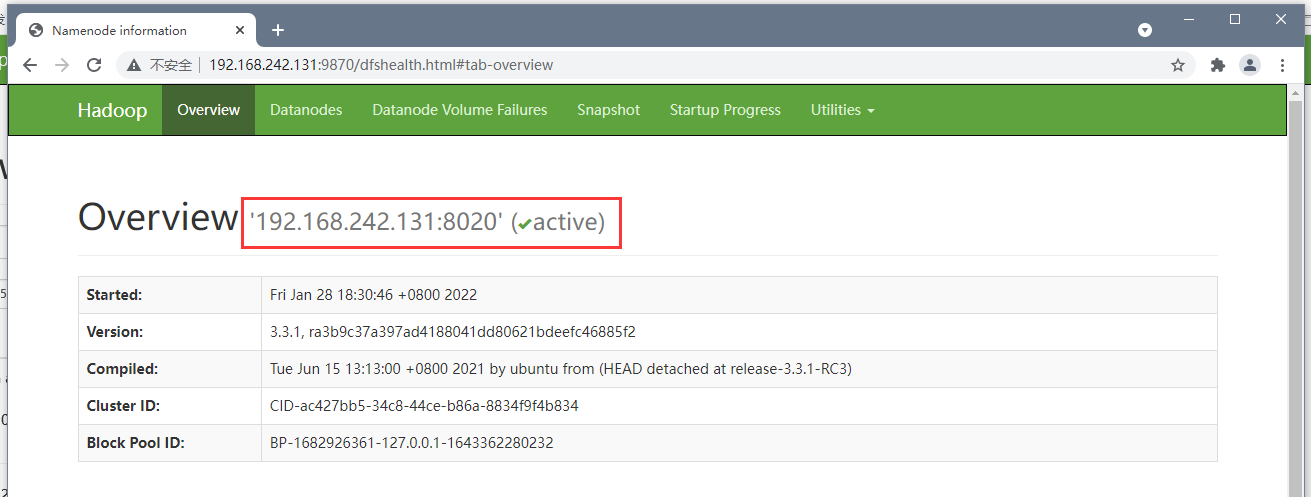
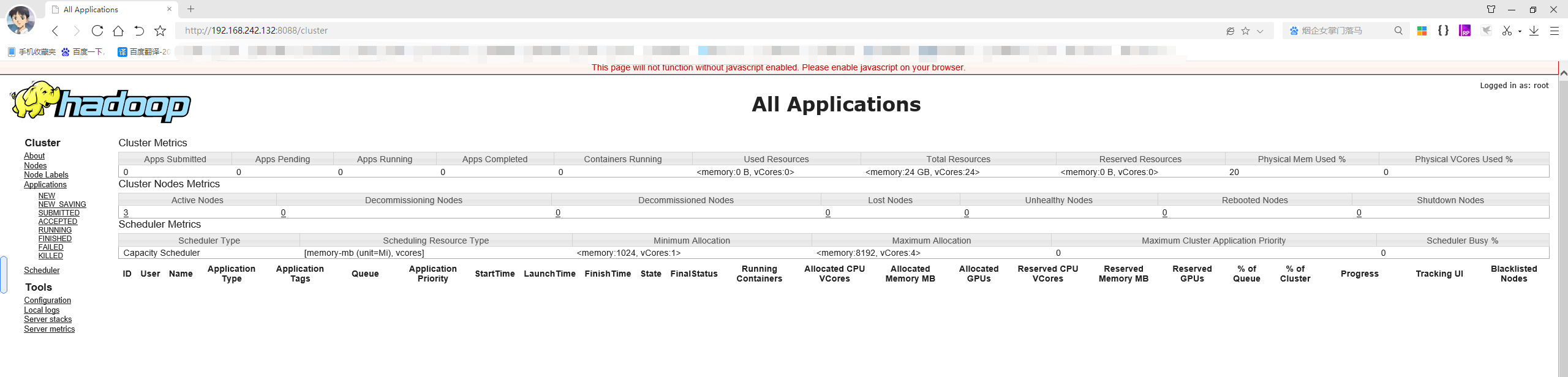
访问页面进行查看:
http://192.168.242.131:9870/explorer.html#/ http://192.168.242.132:8088/cluster
配置历史记录服务器
编辑mapred-site.xml
vim mapred-site.xml
追加配置信息
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property>
分发到其他机器上
xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
在1号机上启动 历史记录服务
mapred --daemon start historyserver
检查是否启动:
[root@localhost hadoop]# mapred --daemon start historyserver [root@localhost hadoop]# jps 6657 Jps 5170 DataNode 4999 NameNode 6631 JobHistoryServer 3288 NodeManager
历史记录服务地址
http://192.168.242.131:19888/jobhistory
日志记录汇聚配置:
更改yarn-site.xml
vim yarn-site.xml
文件内容追加
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://192.168.242.131:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
同步分发:
xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
2号机关闭yarn
$HADOOP_HOME/sbin/stop-yarn.sh
1号机关闭历史记录服务
mapred --daemon stop historyserver
然后再1号机和2号机重新打开
# 2号机
$HADOOP_HOME/sbin/stop-yarn.sh
# 1号机
mapred --daemon start historyserver
编写测试文件进行传输
echo test-hadoop-log > /root/sample.txt
hadoop fs -put /root/sample.txt /
查看记录:
http://192.168.242.131:19888/jobhistory

 浙公网安备 33010602011771号
浙公网安备 33010602011771号