【三、深入浅出GCC编译器】一个源文件到可执行文件是如何生成的:GCC编译工具链及编译参数详解

🔈前言
GCC原名为GNU C语言编译器(GNU C Compiler),只能对C语言进行编译等处理。后来随着其功能的扩展,可以支持更多编程语言,如C++、Java、Fortran、Pascal、Objective -C、Ada、Go以及各类处理器架构上的汇编语言等。所以,现在我们所说的GCC是指GNU编译器套件(GNU Compiler Collection)。本文将带你迈入GCC的大门,了解一个C源文件是如何在GCC编译工具链的加工下成为一个可执行性文件的,并详细讲解GCC编译参数以及可能会用到的其他知识。
一、GCC交叉编译工具链
GCC编译工具链包含了GCC编译器在内的一整套工具,主要包含了GCC编译器、Binutils工具集、glibc标准函数库。一般情况下,我们说的GCC编译工具链就是指GCC编译器。
1. GCC编译器
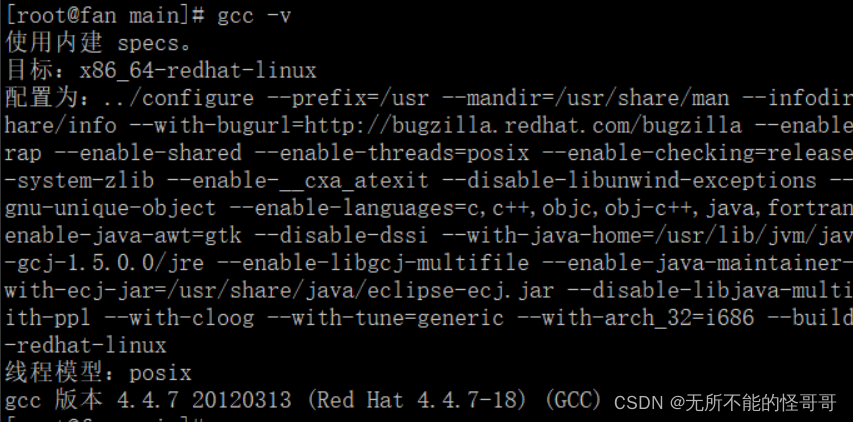
GCC原名为GNU C语言编译器(GNU C Compiler),只能对C语言进行编译等处理。后来随着其功能的扩展,可以支持更多编程语言,如C++、Java、Fortran、Pascal、Objective -C、Ada、Go以及各类处理器架构上的汇编语言等。所以,现在我们所说的GCC是指GNU编译器套件(GNU Compiler Collection),并且现在的GCC还可以进行交叉编译(在一个平台下编译包含另一个平台的代码)。通过下面的命令可以查看GCC版本和GCC的安装路径。
gcc -v
which gcc

C语言编译器是gcc-core,C++语言编译器是gcc-c++。
2. Binutils工具集
(1)链接器与汇编器
binutils(bin utility,GUN二进制工具集),GNU binutils是一组二进制工具集。包括:addr2line ar gprof nm objcopy objdump ranlib size strings strip等。工具集默认在目录 /usr/bin 目录下,在这个工具集中我们必须要知道的工具有两个:ld 链接器和 as 汇编器。这两个工具和我们编译一个源文件息息相关。
as 汇编器用于把汇编文件(汇编语言)转换为目标问价(机器码),完成 .s到 .o 的工作;
ld 链接器用于把编译生成的多个目标文件链接组织为可执行文件;

这两个工具我们一般不会直接调用,它们大多是在GCC编译文件的时候由GCC编译器调用的。
(2)其它常用工具介绍及用法演示
首先我们准备几个文件,包括.s文件.o文件.c文件.i文和可执行文件,具体这些文件怎么生成,以及这些文件是什么含义在后面的章节有详细介绍(可以先看下一章再返回看本小节)。

① size: 列出文件每个部分的内存大小,如代码段、数据段、总大小等。
输入 size 文件名 就可以看到文件的内存占用情况

text是代码段,用于存放代码;data是用来放已初始化的数据;bss是用来放未初始化的数据。
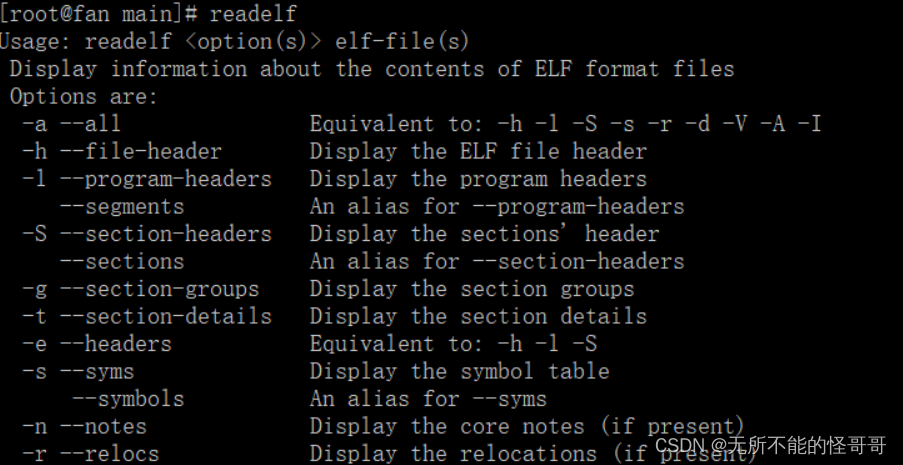
② readelf: 显示有关ELF格式文件内容的信息。ELF格式是UNIX系统实验室作为应用程序二进制接口开发的。ELF格式是Unix/Linux平台上应用最广泛的二进制工业标准之一。
可以输入 readelf 查看说明及选项参数
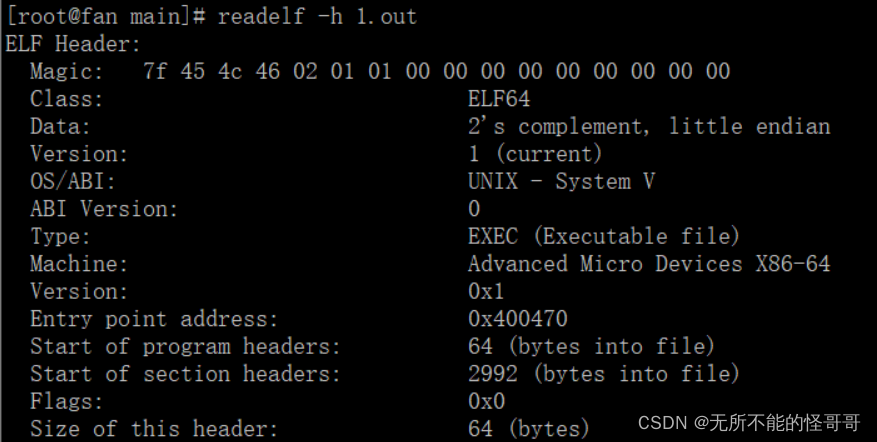
readelf -h 显示可执行文件或目标文件的ELF Header的文件头信息(就是ELF文件开始的前52个字节)
③ nm: 查看目标文件中出现的符号(函数、全局变量等)。
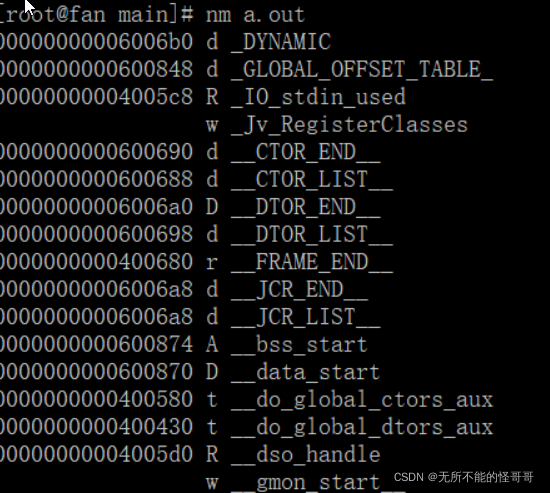
上面可以看到,nm列出的信息总共有三列:第一列是指程序运行时的符号所对应的地址,对于函数来说表示的是函数的开始地址,对于变量则表示的是变量的存储地址;第二列是指相应符号是放在内存的哪一个段;第三列则是指符号的名称。这个命令通常会和 addr2line (后面会介绍)一块使用,因为nm列出了符号的地址,但是并没有行号和源文件名称,而 addr2line 可以根据符号地址给出行号和源文件目录及名称。更多信息可以查看man手册
nm只能用于目标文件和可执行文件,对普通文件无效

④ objcopy: 将目标文件的一部分或者全部内容拷贝到另外一个目标文件中,或者实现目标文件的格式转换。可用于目标文件格式转换,如.bin转换成.elf、.elf转换成.bin等。
比如,格式转换命令
objcopy -O binary xx xx.bin
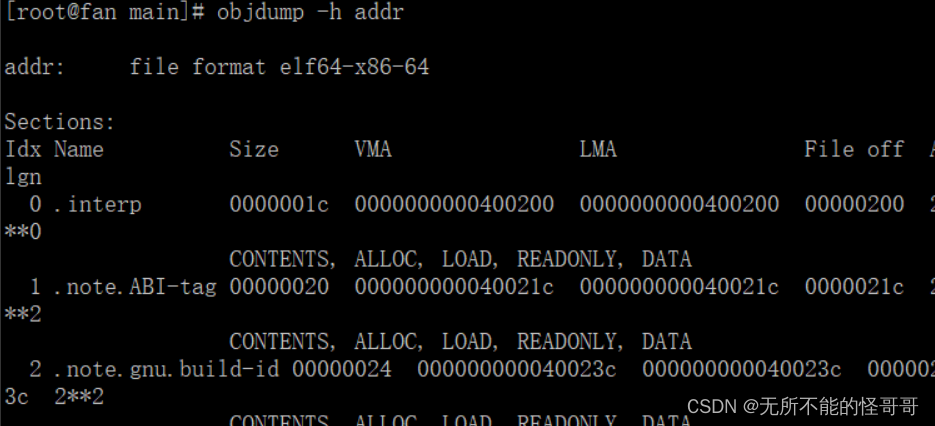
⑤ objdump: 显示程序文件相关信息,最主要的作用是反汇编。这里介绍两个常用的选项参数:
可以通过 -d 选项来对可执行文件进行反汇编
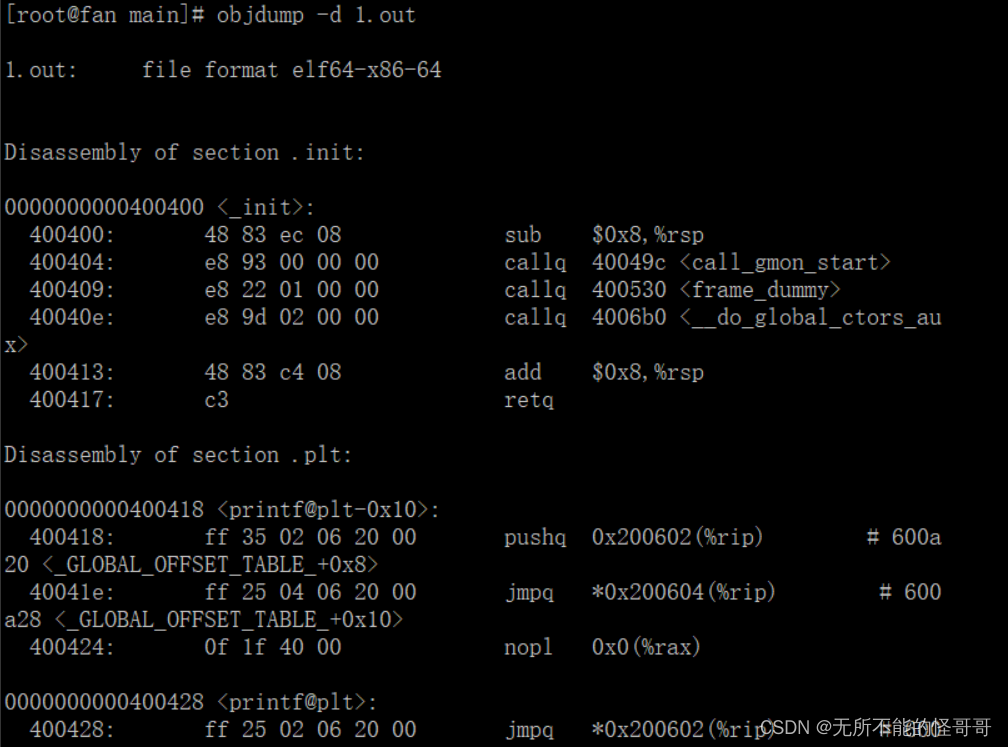
也可以对目标文件反汇编

通过 -h 选项查看目标程序中的段信息和调试信息
⑥ addr2line: 将程序地址翻译成文件名和行号;给定地址和可执行文件名称,它使用其中的调试信息判断与此地址有关联的源文件和行号,通常搭配 nm 使用。
这个命令一般用于调试信息时快速定位错误位置。它的命令用法为addr2line 地址 -e 可执行文件名。为演示这个命令用法,首先创建一个文件,这个文件包含一个函数,函数功能为打印函数地址,代码如下
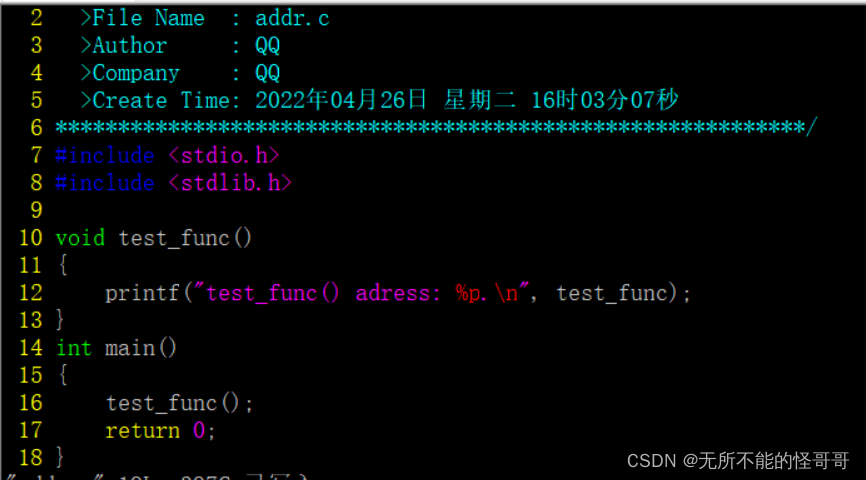
然后编译这个文件,编译时必须要加上 -g 包含调试信息,然后运行,得到打印出的地址

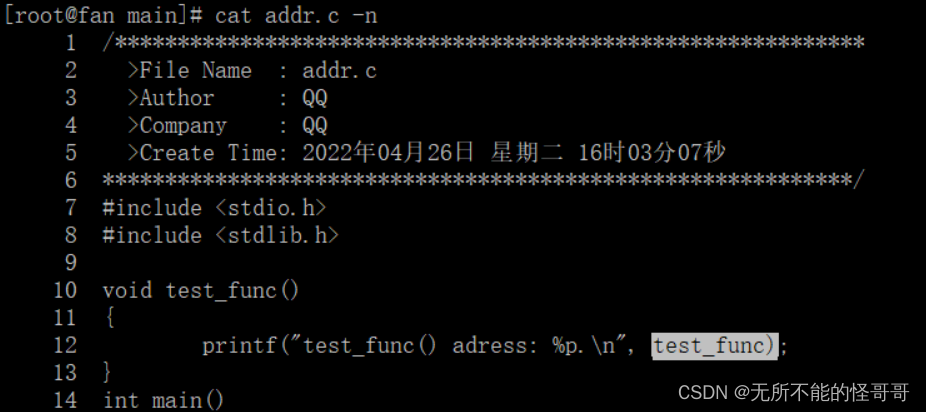
输入命令addr2line 地址 -e 可执行文件名 -f,可以看到文件位置,行号都打印出来了

我么可以确认一下是不是第11行,cat -n 显示行号
⑦ strings: 显示程序文件中的可显示字符串。
可以通过管道和grep过滤自己需要的信息

3. glibc库
glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc和libc都是Linux下的C函数库。libc是Linux下的ANSI C函数库,glibc是Linux下的GUN C函数库。
在CentOS操作系统下,查看glibc的版本
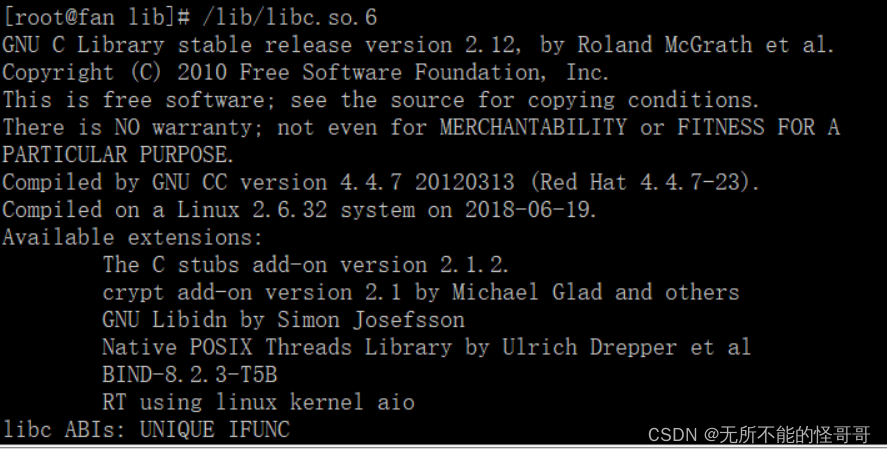
如果你是Ubuntu系统,可以用这个命令
/lib/x86_64-linux-gnu/libc.so.6
二、GCC编译过程
1. 程序的一般编译流程
我们拿到一个.c又或者是.cpp源文件,它是怎么样一步步的变化成一个机器可执行文件的呢,下面就带你解开源文件到可执行文件的神秘面纱。
程序的一般编译流程主要包括四大部分:预处理、编译、汇编和链接。下面讲解这四步的具体工作,带你了解源文件到可执行文件的“进化之路”。
(1)预处理(Preprocess)
这一步由预处理器完成,对源程序中的伪指令(以#开头的指令)和特殊符号进行处理,伪指令包括宏定义指令、条件编译指令和头文件中包含的指令。这一步的主要工作包括以下内容:
- 将所有的#define删除,并将宏定义进行宏展开;
- 处理所有条件编译指令,如#if、#ifdef、#ifndef、#else、#elif、#endif等;
- 处理 #include预编译指令,将被包含的头文件内容插入该预编译指令的位置,如果是多重包含的话会递归执行;
- 处理其他宏指令,包括#error、#warning、#line、#pragma;
- 处理所有注释(C++的//,C语言的/**/),一般会用一个空格来代替连续的注释;
- 添加行号和文件标识,以便于编译时编译器产生调试用的行号信息及编译时产生编译错误和警告时可以把行号打印出来;
- 保留所有的#pragma编译器指令;
- 处理预定义的宏:如__DATE__、__FILE__等;
- 处理三元符:比如会将??=替换为#,将??/替换成\等(对于键盘不提供#等输入的情况,可能会用到三元符,可以直接忽略这一条);
(2)编译(Compilation)
这一步由编译器完成,对预处理后的文件进行词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。
- 词法分析:词法分析是编译过程的第一个阶段,这个阶段的任务可以看成是从左到右一个字符一个字符地读入源程序,从中识别出一个个单词符号,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。上述读入源程序的过程和识别符号的任务通过词法分析程序实现,词法分析整个过程依据的是语言的词法规则。词法分析程序的输出通常是一个二元组,即单词种别和单词自身的值。词法分析程序可以使用lex等工具自动生成。
- 语法分析:语法分析是编译过程的一个逻辑阶段,此阶段的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等。语法分析程序判断源程序在结构上是否正确。
- 语义分析:语义分析是编译过程的一个逻辑阶段,语义是解释控制信息每个部分的意义,它规定了需要发出何种控制信息,以及完成的动作与做出什么样的响应,此阶段的任务是对结构上正确的源程序进行上下文有关性质的审查, 进行类型审查,语义分析将审查类型并报告错误。也就是说,语义分析结合上下文推导出语句真正的含义。
(3)汇编(Assemoly)
由汇编器完成,将汇编代码转变成机器可执行的二进制代码(机器码),并生成目标文件。之所以要经过预处理、编译、汇编这么一系列步骤才生成目标文件,是因为在每一阶段都有相应的优化技术,只有在每个阶段分别优化并生成最为高效的机器指令才能达到最大的优化效果,如果一步到位直接从源程序生成目标文件,可能就会失去很多代码优化的机会。
(4)链接(Linking)
由链接器完成,主要解决多个文件之间符号引用的问题,即symbol resolution。编译时编译器只对单个文件进行处理,如果该文件里面需要引用到其他文件中的符号,比如全局变量或者调用了某个库函数中的函数,那么这时候,在这个文件中该符号的地址是没法确定的,只能由链接器把所有的目标文件链接到一起才能确定最终的地址,并生成最终的可执行文件。无论采用静态链接还是动态链接,都会生成一个可以在计算机上执行的可执行程序。
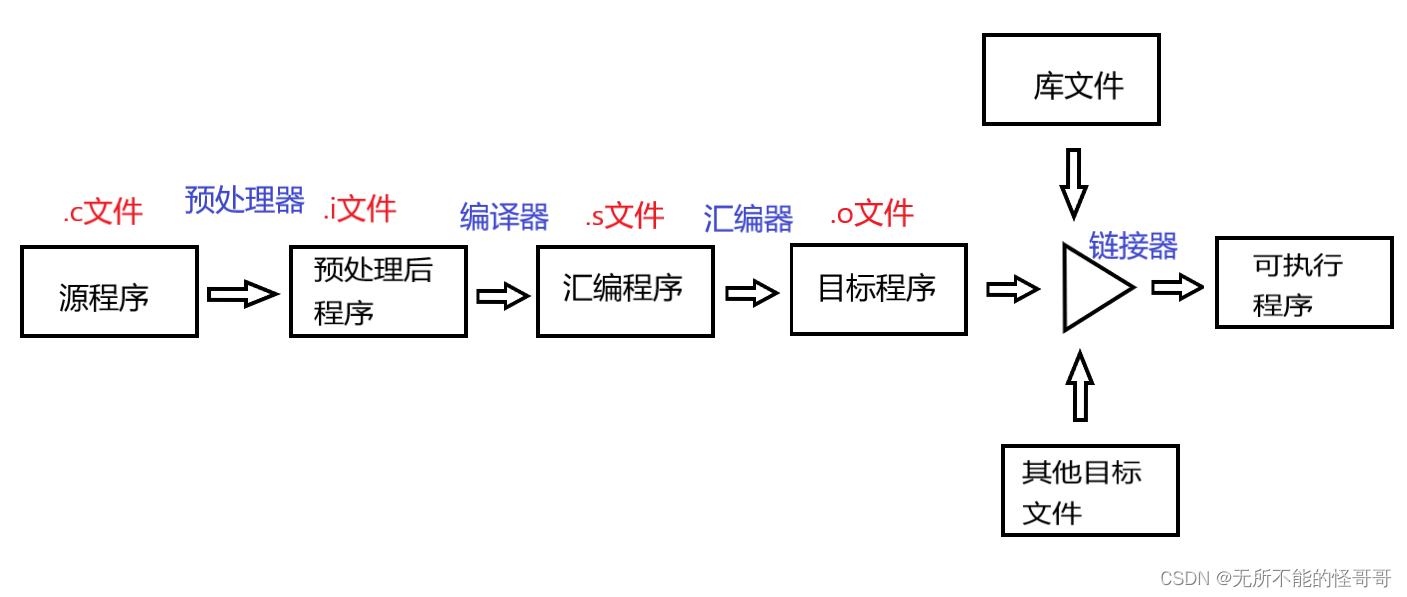
2. GCC编译流程
GCC的编译流程也一样四个阶段,和上节所讲的一致。这里主要讲每个环节所使用的参数以及使用的工具。
(1)文件后缀
每一个环节都会生成一种类别的文件,并作为下一个环节的输入,GCC编译器是通过后缀来区分文件的类型的。
| 后缀 | 类型 |
|---|---|
| .c | C源文件 |
| .cpp / .cxx / .cc / .C | 这些都是C++源文件 |
| .i | C源文件预处理后生成的文件 |
| .s | 汇编语言的源文件 |
| .o | 目标文件(链接后生成可执行文件) |
| .h | 头文件 |
| .ii | C++源文件预处理后生成的文件 |
| .S | 预编译后的汇编源文件 |
补充一下C++的源文件后缀名,通过man可以查到

可以看到,我们上面并没有列出可执行文件的后缀,原因是,在Linux中,可执行文件并没有特定的后缀,Linux主要通过文件的权限来判断文件是否可执行,这一点一定要注意,这也是很多初学Linux的人很容易忽略的一点。

我这里生成了4个可执行文件,有==.out== 后缀的,有没有后缀的,甚至还有一个 .pp 后缀的,但他们都是可执行的
(2)参数及工具
① 预处理阶段
预处理也叫做预编译,这个阶段GCC会调用 cpp 进行预处理,预处理的工作可以参考上一节。gcc预处理的参数是 -E ,如果直接gcc -E一个C源文件的话,默认是不会把生成的文件放出来的,当我们执行命令的时候,会刷刷刷出来一大堆东西,这是因为预处理的时候会进行宏展开和宏替换,所以本来的程序会变成一个非常庞大的代码,而gcc默认不会生成新的文件,所以就把预处理后的代码全都打印在了终端,所以你执行命令后会看到一下子出来一堆代码
gcc -E hello.c
执行完预处理命令后,我们看一下当前目录,并没有发现hello.i这样的文件

我们要想获取这个==.i== 文件,就要通过 > 或 >> 进行重定向,其中 > 表示先清空再重定向, >> 表示追加。命令如下
gcc -E hello.c > hello.i
表示把 gcc -E hello.c生成的文件重定向到 hello.i 文件中

我们这时候再执行预处理命令,发现已经有了hello.i文件,并且屏幕上啥也没显示,不想刚才出来一堆代码,这是因为我们通过 > 把生成的代码重定向到了hello.i文件中了,所以,终端什么也没打印。那么,我们为什么要重定向到一个.i文件中,而不是重定向到.c文件中呢?前面说了,GCC通过文件后缀来区分文件类型,只有.i文件才能作为编译的输入,这么做是为了下一步。我们可以查看下hello.i的内容,非常非常的多,接近2000行,而我们源文件只有短短几行代码。
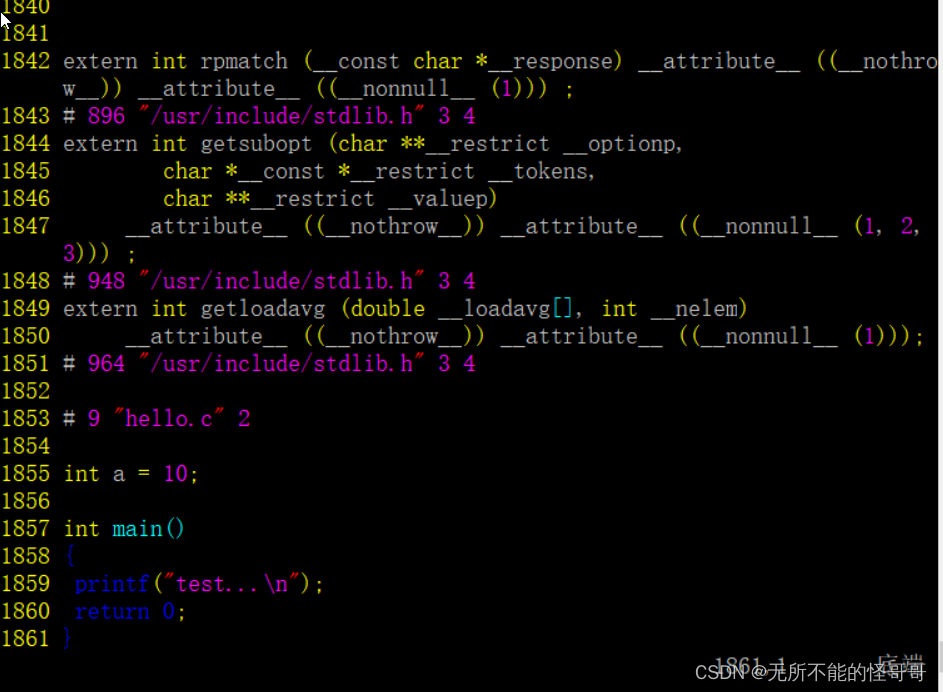
源文件
② 编译
调用 cc 进行编译(一般来说,Linux下 cc 是一个符号连接,指向 gcc),通过 -S 选项参数可以生成 .s 后缀的汇编代码文件,以下两种方式都可以生成 .s 文件,不用指定要生产的文件,会自动生成一个与源文件同名的 .s 为后缀的汇编文件
gcc -S hello.c
gcc -S hello.i

通过 cat 命令查看一下,可以看到里面是汇编代码
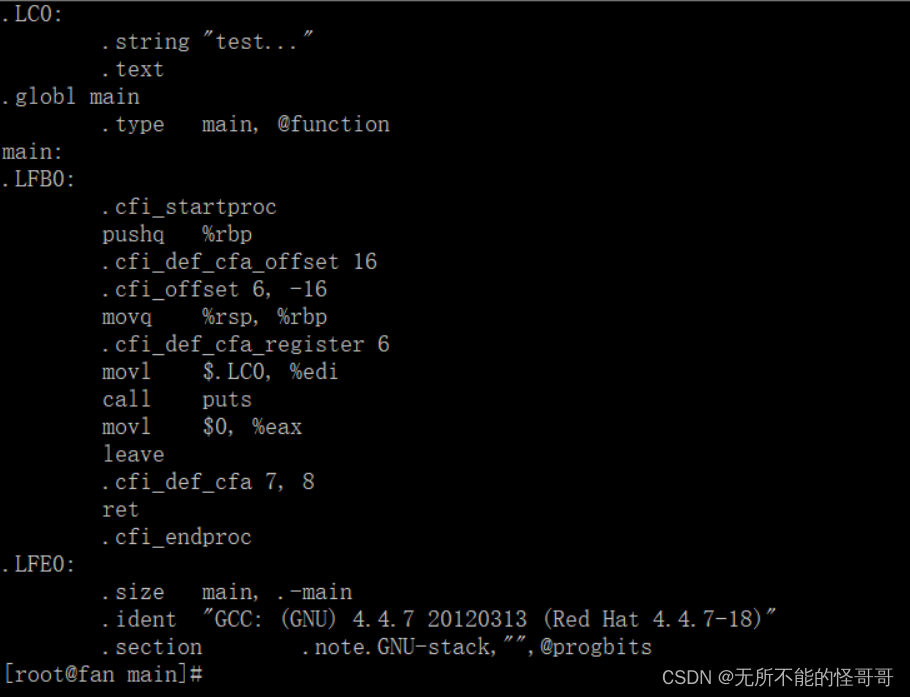
③ 汇编
调用 as 将汇编代码变成 .o 后缀的目标文件,这里使用的选项参数是 -c ,同样不需要指定要生产的文件名,会自动生成一个与源文件同名的 .o 后缀的文件

看一下文件内容,看不懂,因为是机器码,只有机器能看懂,哈哈哈哈
④ 链接
调用 ld 进行链接,生成可执行文件,这一步不需要任何选项参数
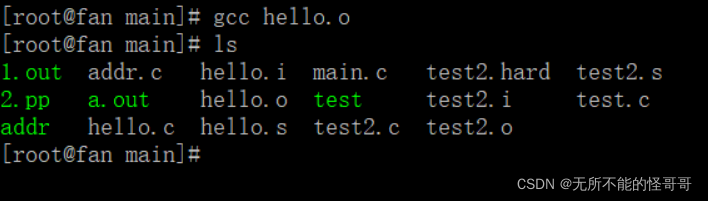
这里要提醒一下,如果你不指定可执行文件名和后缀,gcc会默认生成一个 a.out ,也就是说,只要你不指定可执行文件名及后缀,那么你编译任何源文件,生成的都是 a.out ,那么你也可以根据自己的喜好生成自己喜欢的名字,上图中绿色的都是可执行文件。一般我们都是指定一个与源文件同名,没有后缀的文件作为可执行文件。这里再次强调,在Linux中,可执行文件并没有特定的后缀,Linux主要通过文件的权限来判断文件是否可执行,只要权限是可行的,那么这个文件就是可执行的,和他什么后缀,什么名称没有关系。
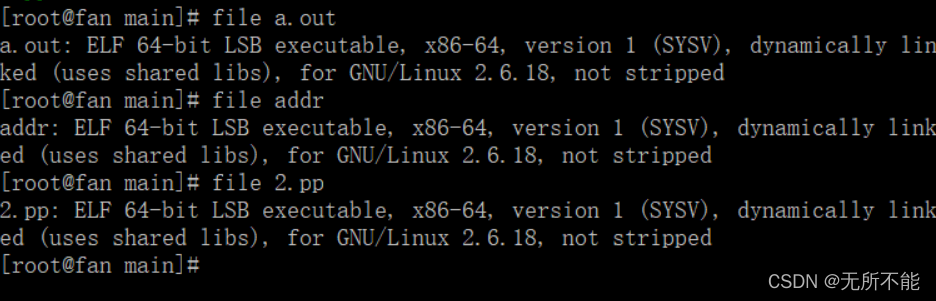
链接有两种方式,我们不加任何选项参数默认使用的是动态链接,使用静态链接要加一个选项 –static。
- 动态链接:动态是指在应用程序运行时才去加载外部的代码库,所以动态链接生成的程序比较小。
- 静态链接:它在编译阶段就会把所有用到的库打包到自己的可执行程序中,生成的程序比较大。
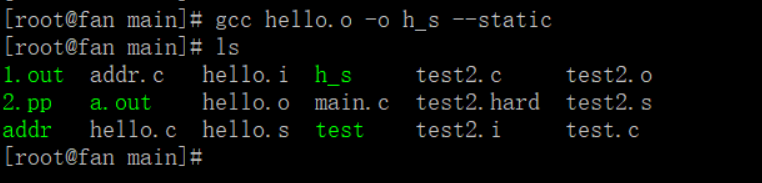
通过对比动态链接生成的a.out和静态链接生成的h_s可以看到其所占空间大小的差距。

⑤ 最后总结为一张图
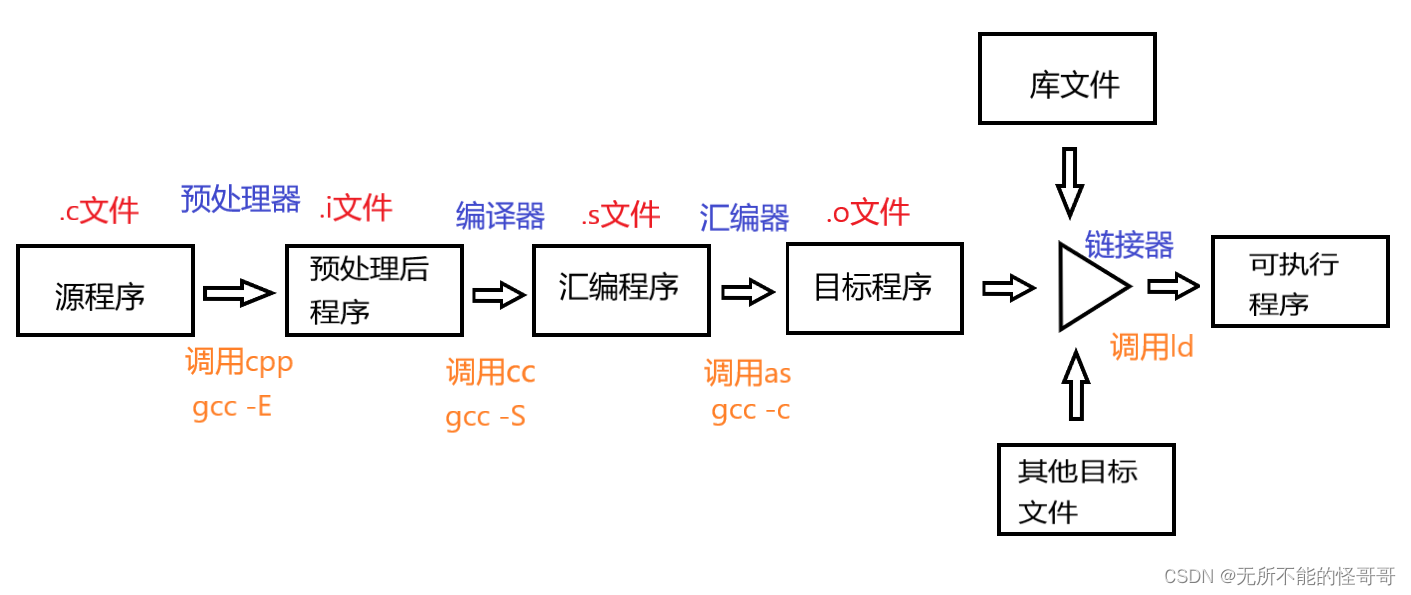
三、GCC编译参数
1. 常用编译选项参数汇总
| 选项参数 | 作用解析 |
|---|---|
| -E | 预处理生成 .i 文件 |
| -S | 编译生成 .s 汇编文件 |
| -c | 汇编生成 .o 目标文件 |
| -o | 指定目标文件 |
| -O | 优化选项,有1-3级 |
| -I (大写i) | 指定包含头文件的路径(绝对、相对路径都可) |
| -l (小写L) | 指定库名,libxxx.a或libxxx.so |
| -L | 包含的库路径 |
| -g | 生成调试信息,用于gdb调试,如果不加这个选项无法进行gdb调试 |
| -Wall | 显示更多警告信息 |
| -D | 指定宏 |
| -lstdc++ | 编译C++源代码 |
-E/-S/-c 在上面已经介绍完毕,下面介绍剩下的选项参数。
2. 使用方法介绍
准本工作,首先准备一个hello.c文件,这是一个单独的文件
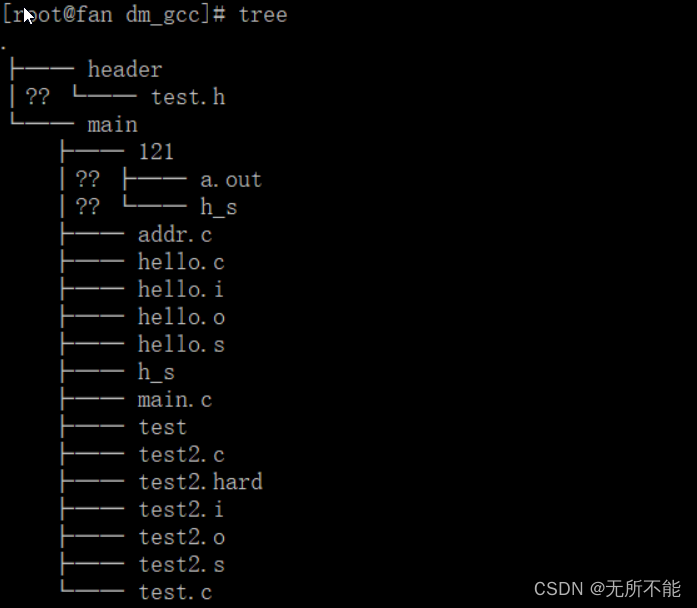
然后准备一个main.c和一个test.h一个test.c文件,main.c文件和test.c文件放在main目录下,test.h放在header目录下,目录结构如下
文件内容如下
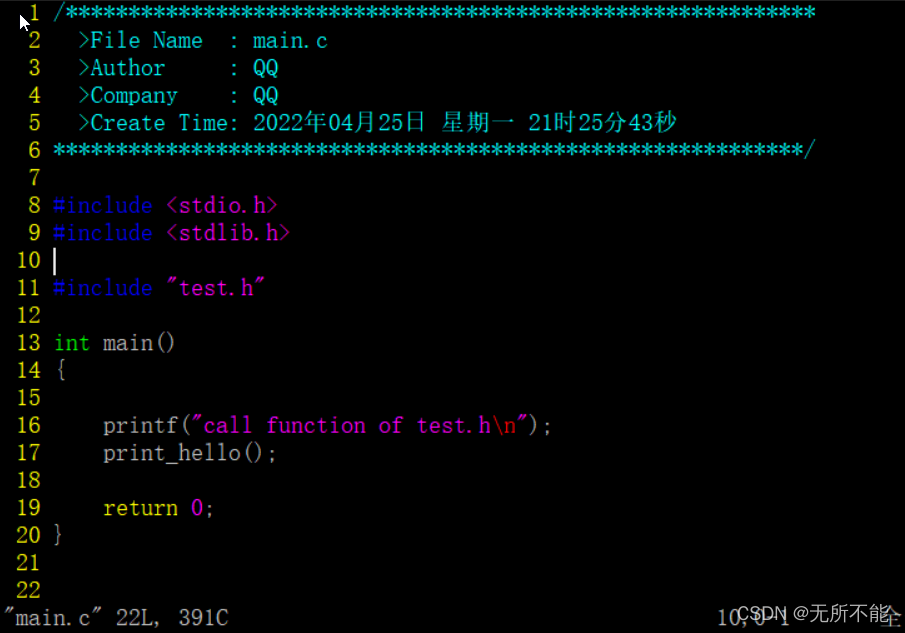
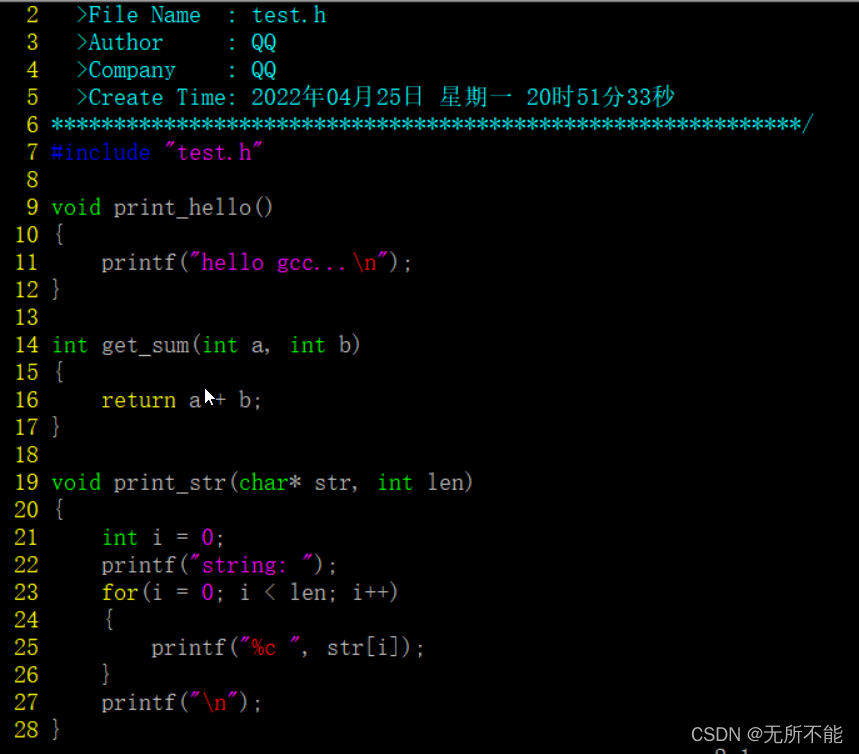
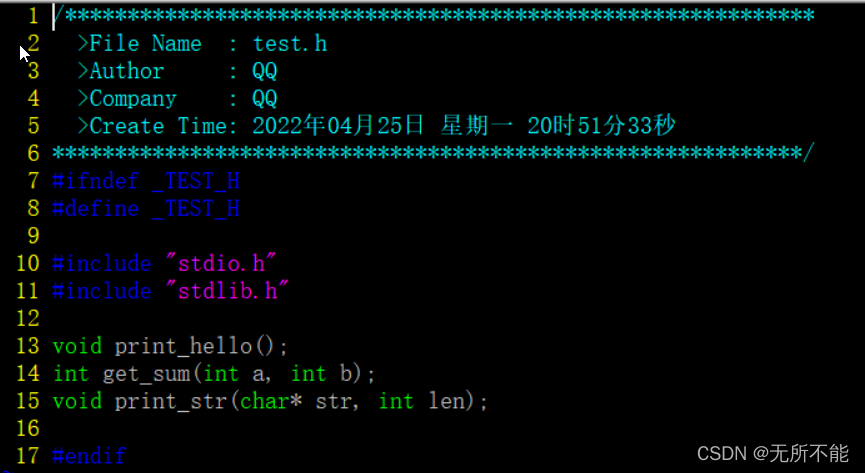
这三个文件的关系是,main.c调用了test.h中的函数,test.c实现了test.h中的函数。下面将使用这三个文件进行演示。
(1)-o 指定目标文件
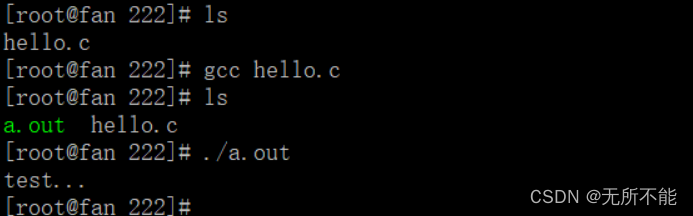
如果使用GCC编译且不加任何选项的时候,默认会生成一个 a.out 的可执行文件
如果加上 -o 选项就可以自己指定可执行文件名甚至是后缀
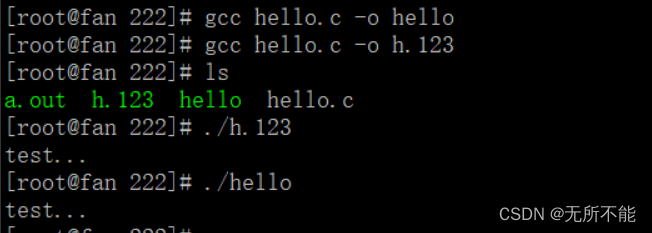
这些绿色的文件都是可执行的,前面已经多次强调过,可执行文件和后缀没有关系,不过我们一般会指定为和源文件同名,无后缀的这种格式,即这里的 hello 文件。
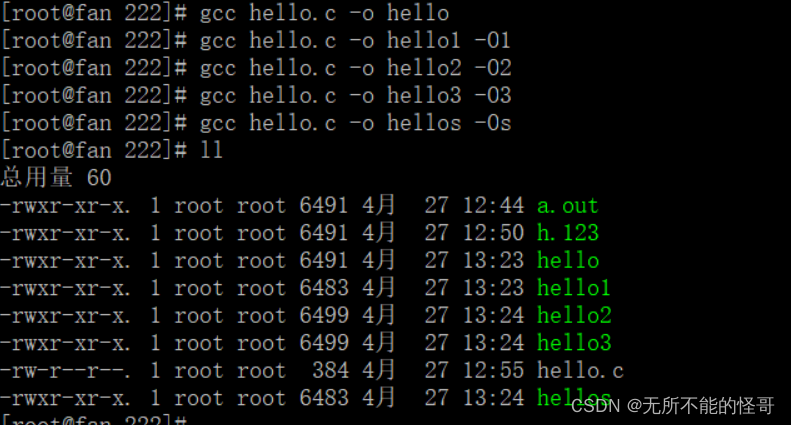
(2)-O 优化选项
优化选项,不写就是默认不优化,1-3优化等级越来越高,但实际上并非优化等级越高就越好。
- O0:关闭所有优化选项,这是编译器默认的编译选项。
- O1:基本优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
- O2:包含-O1的优化并增加了不需要在目标文件大小和执行速度上进行折衷的优化。编译器不执行循环展开以及函数内联。会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。 大多数情况下,推荐使用 O2 这一级优化选项就足够了。
- O3:最高的优化级别,它会使用更多的编译时间,并且会增大二进制文件的体积并让他们更消耗内存。O3 级优化除了会打开所有 -O2 的优化选项外增加 -finline-functions 、-funswitch-loops 、-frename-registers 、-fweb 等优化选项(这些优化选项随着优化级别的增加会添加更多优化选项,每个选项都会完成一定的优化内容,这里就不深入探讨了,只需要了解 O1-O3 的使用即可)。这一级优化编译时间最长,生成的目标文件也更大,有时性能不增反而降低,甚至产生不可预知的问题或错误,所以大多数情况下不推荐使用。
- Os:其实还有一个 Os ,它使用了所有 -O2 的优化选项,但又不会缩减代码的尺寸大小,姑且把它算在第二三级之间吧。
![在这里插入图片描述]()
(3)-I 指定包含头文件路径及头文件引入的两种方法
我们编译一下前面准备好的main.c和test.c
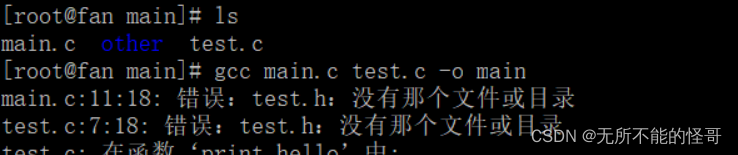
可以看到,编译错误,找不到头文件test.h,这时有人可能会很奇怪,在main.c中和test.c中已经包含头文件了呀,为啥会找不到呢?其实,这是因为这个头文件和main.c、test.c不在同一个目录下。我们应该知道,在包含头文件的时候,标准库文件一般用尖括号 <> ,编译器回到默认的目录下寻找这些.h文件,如果是自己写的头文件,要用双引号 “” 去包含,编译器会在当前目录(源文件所在目录)进行查找。也就是说,出现这个错误的原因是,gcc编译器找不到test.h这个文件,它不知道这个文件在哪个目录下。
- #include <>:将指定文件引入到当前文件,搜索策略为,直接在编译器指定的路径处开始搜索,如果找不到被引入文件,则程序报错。因此系统提供的头文件推荐使用这种方式引入。如果是集成开发环境,比如VS,这个默认路径一般在VS安装目录下的一个名为 include 的路径下。在Linux中,一般默认路径是 /usr/include 或 /usr/lib 下的目录。
- #include “”:将指定文件引入到当前文件,搜索策略为,首先在运行程序所在的目录处进行搜索,搜索失败后再到编译器指定的路径处搜索,如果仍然搜索失败,则直接报错。因此,用户自定义头文件必须用这种方式引入,系统提供的头文件也可以使用这种方式,但是会增加没必要的搜索,所以不推荐。
那么上面问题的解决方法就是加 -I 选项,可以使用相对路径或决定路径:
相对路径
gcc main.c test.c -o main -I ../header/
绝对路径
gcc main.c test.c -o main -I /home/qq/dm/dm_gcc/header/

(4)-l (小写L) 指定库名
通常动态库静态库名字的格式都是 libxxx.so 或 libxxx.a ,所以这个参数的使用方法是直接加库名 -lxxx ,具体使用方法将在我Linux专栏的另一篇文章《自己动手做动态库与静态库》中详细介绍。
(5)-L 包含的库路径
指定动态库和静态库的路径,后面直接加路径即可。具体使用方法将在我Linux专栏的另一篇文章《自己动手做动态库与静态库》中详细介绍。
(6)-g 生成调试信息
这个选项用于gdb调试的时候,只有在编译的时候加 -g 选项,才能进行gdb调试。
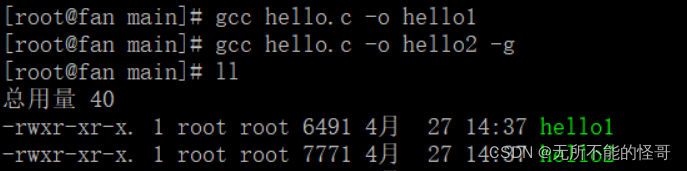
可以看到,加了 -g 选项后,文件变大了,这是因为里面包含了调试所用的信息,关于 -g 选项的更多知识和 gdb 调试相关讲解,将在Linux专栏的另一篇文章《GDB调试器》中详细介绍。
(7)-Wall 显示更多警告信息
当GCC在编译过程中检查出错误的话,它就会中止编译,并报错。但是当检测到警告时却能继续编译并生成可执行文件,这时因为警告只是针对程序结构的诊断信息,它不能说明程序一定有错误,而是说明程序存在风险,或者可能存在错误。GCC提供了非常丰富的警告,但是如果你不启用这些警告的话,GCC编译器是不会报告检测到的警告信息的。
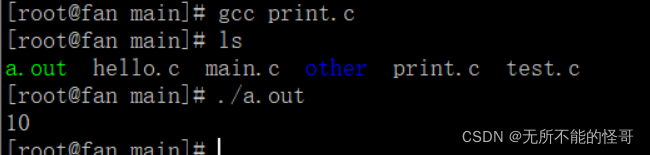
举个例子,我们写一个int类型的main函数,并且不加return语句
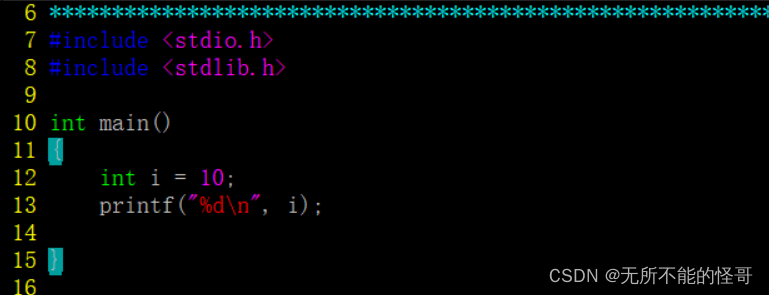
我们直接编译程序,可以看到,编译通过,没人任何报错也没有任何警告,并且程序可以运行并打印出值。实际上,main函数没有return语句至少应该提示警告信息的,甚至在VS中,这个文件直接就无法通过编译且直接报错的。
我们再加上 -Wall 选项,可以看到,虽然生成了可执行文件,但是有警告信息提示。

实际上,即使加了 -Wall 选项,也并非所以警告都会提示,有一些警告是不会提示的,比如隐式类型转换等。我们对下面程序编译,程序中有一个int到char的隐式类型转换

编译一下,虽然没有警告,但是程序没有打印任何东西。
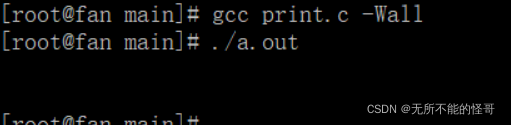
(8)-D 指定宏
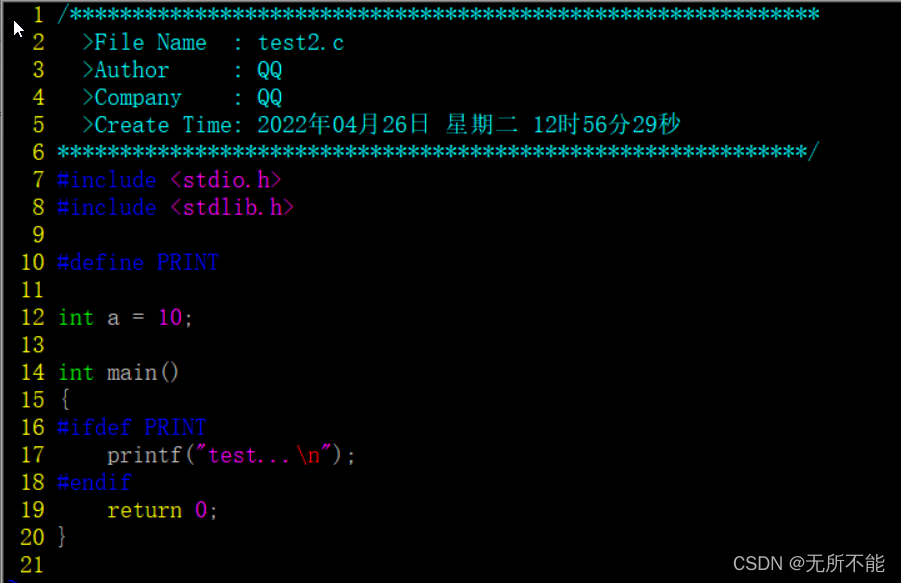
我们将前面准备好的hello.c进行一点修改,把宏定义删除
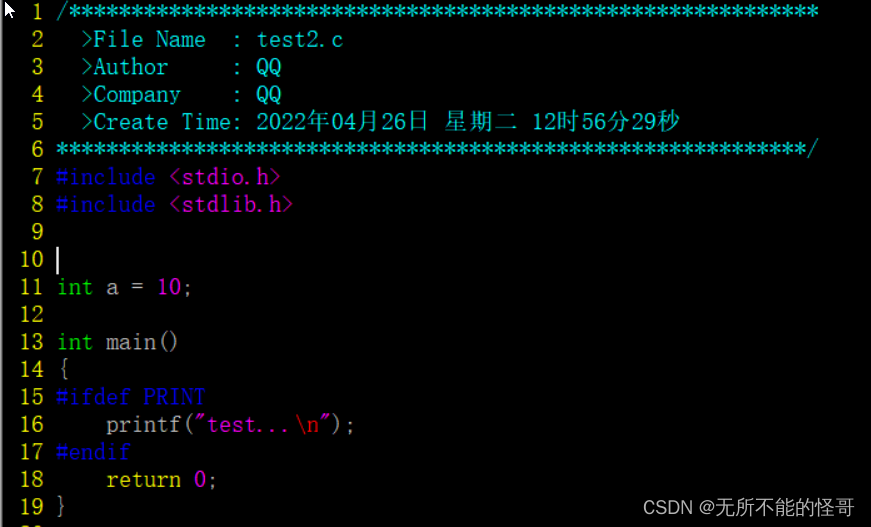
编译运行

因为没有宏定义 PRINT ,所以 printf 语句不会执行,也就不会打印任何东西。我们可以通过 -D 来指导一个宏。
gcc hello.c -D PRINT
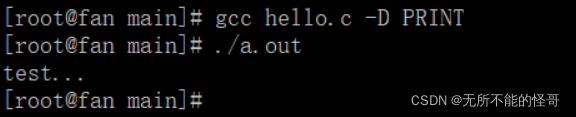
可以看到, printf 函数执行了。
(9)-lstdc++ 编译C++源文件
直接用gcc编译C++源文件,是无法编译的

编译C++源文件有两种方法,一种是使用 -lstdc++ 选项,另一种是使用 g++ 编译。

总结
通过这篇文章你是不是对程序的编译过程和GCC编译工具链有了更加深刻的认识呢,其实GCC也没什么神秘的吧,哈哈哈哈。有句诗我非常喜欢“纸上得来终觉浅,觉知此事要躬行”,对于GCC的学习绝不能止步于这篇文章,一定要打开自己的虚拟机或者双系统进入你的Linux,一个命令一个命令的敲,一个文件一个文件的看,动手实践才能把知识变成自己的。当然,对Linux的学习更不能止步于此,这里分享一个学习Linux的小妙招,重点来了哦,那就是一定要关注我的Linux专栏,把里面的每一篇文章都看透,嘻嘻嘻~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号