HCIP-EI v2.0 培训04: 自然语言处理理论和应用
内容
了解自然语言处理基本知识
掌握循环神经网络算法
掌握自然语言处理关键技术
了解自然语言处理的应用
自然语言处理介绍
NLP: Natural Langauage Processing,自然语言处理
能力模型
- 通常是基于语言学规则的模型,建立在人脑中先天存在语法通则这一假设的基础上,认为语言是人脑的语言能力推导出来的,建立语言模型就是通过建立人工编辑的语言规则集来模拟这种先天的语言能力
- 又称为“理性主义”语言模型
- 建模步骤:
- 语言学知识形式化
- 形式化规则算法化
- 算法实现
应用模型
- 根据不同的语言处理应用建立的特定语言模型,通常是通过建立特定的数学模型来学习复杂的、广泛的语言结构,然后利用统计学、模式识别和机器学习等方法来训练模型的参数,以扩大语言的使用规模
- 又称“经验主义的”语言模型
- 建模步骤:
- 大规模真实语料库中获得不同层级语言单位上的统计信息
- 依据较低级语言单位上的统计信息运用相关的统计推理技术,来计算较高级语言单位上的统计信息
NLP 的发展过程中大致分为两类:
- 基于规则的方法
- 基于统计的方法
NLP 的三个层面
- 词法分析:分词、词性标注、命名实体识别
- 句法分析:句法结构分析、依存关系分析
- 语义分析:最终目的是理解句子表达的真实语义
难点
- 词法歧义
- 分词:词语的切分边界
- 词性标注:同一个词语在不同上下文中的词性不同
- 命名实体识别:人名、专有名词、缩略词等未登录词的识别困难
- 句法歧义
- 句法层面上的依存关系受上下文的影响
- 语义歧义:语法歧义
- 语用歧义:场景不同,意思不一样
NLP 发展现状
- 已开发完成一批具有影响的语言资料库,部分技术已达到或基本达到实用化成都,并在实际应用中发挥巨大作用
- 北大语料库、HowNet
- 新的研究防线
- 阅读理解、图像(视频)、语音同声传译
- 一些理论问题尚未解决
- 未登录词的识别、歧义消解的问题、语义理解的难题
- 缺少一套完整、系统的理论框架体系
预备知识
语言模型
N-gram 语言模型
n元模型,忽略距离大于等于n的上文词的影响,基于统计
NN语言模型(Neural Network Language Model)和统计语言模型的关系:
- 相同点
- 都是将句子看做一个词序列,来计算句子的概率的语言模型
- 不同点
- 计算概率的方式:N-gram基于马尔科夫假设只考虑前n个词,NNLM要考虑整个句子的上下文
- 训练模型的方式:N-gram基于最大似然估计来计算参数,是基于词本身的;NNLM基于RNN的优化方法来训练模型
- 循环神经网络可以将任意长度的上下文讯息存储在隐藏状态中,而不仅限于N-gram模型忠的窗口限制
文本向量化
将文本表示成一系列能够表达文本语义的向量
常用的向量化算法:
- one-hot
- TF-IDF
- word2vec
- CBOW
- Skip-gram
- doc2vec/str2vec
- DM (Distributed Memory)
- DBOW (DIstributed Bag of Words)
TODO: 每种算法详细说明
常用算法
- HMM 模型
- 条件随机场
- 设 \(X = (X_1,X_2,...,X_n) 和 Y = (Y_1,Y_2,...,Y_m)\) 是联合随机变量,若Y构成一个无向图 \(G = (V,E)\) 表示的马尔科夫模型,则其条件概率 P(Y|X) 称为条件随机场(Conditional Random Field, CRF)
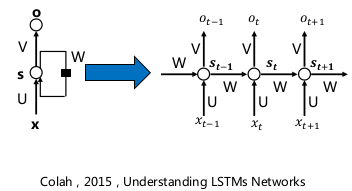
- RNN
- 不同于传统的机器翻译模型,仅考虑有限的前缀词汇信息作为语义模型的条件项,RNN 有能力将语料集中的全部前序词汇纳入模型的考虑范围
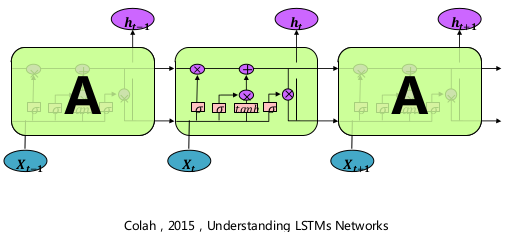
- LSTM
- 一种特殊的RNN类型,可以学习长期依赖信息
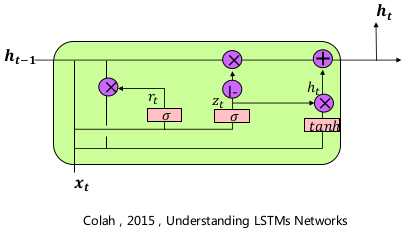
- GRU
- 可以看做是 LSTM 的变种,GRU 把 LSTM 中的遗忘门和输入门用更新门代替,把 cell state 和隐状态 \(h_t\) 进行合并,在计算当前时刻新信息的方法和 LSTM 有所不同
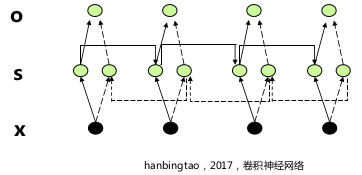
- 双向RNN(BiRNN, 两个 LSTM 构成)
- 经典的RNN中,状态的传输是从前往后单向的,而在一些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关,这时就需要双向 RNN(BiRNN) 来解决这类问题
- 例如预测一个语句中缺失的单词不仅需要根据前文判断,也需要根据后面的内容
- 双向RNN 是由两个 RNN 上下叠加在一起组成的,输出是由这两个 RNN 的状态共同决定
关键技术
分词(词法分析)
中文分词
Chinese Word Segmentation,将一个汉字序列分割为单独的词
规则分词
- 一种机械分词方法,主要是通过维护词典,在切分语句时,将语句中的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不切分
- 按照匹配切分的方式分类:
- 正向最大匹配法(Maximum Match Method, MM法)
- 逆向最大匹配法(Reserve Maximum Match Method, RMM法)
- 双向最大匹配法(Bi-direction Match Method, MM法)
- 特点:简单高效,词典维护困难。网络新词更新不及时,词典很难覆盖到所有的词
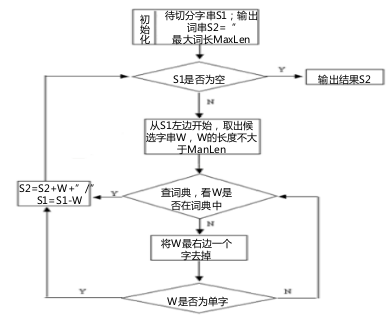
正向最大匹配法:
统计分词
- 将分词作为字在字串中的序列标注任务来实现
- 每个字在构造一个特定的词语时都占据着一个确定的构词位置,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词
- 步骤:
- 建立统计语言模型
- 对句子进行单词划分,然后对结果进行概率计算,获得概率最大的分词方式

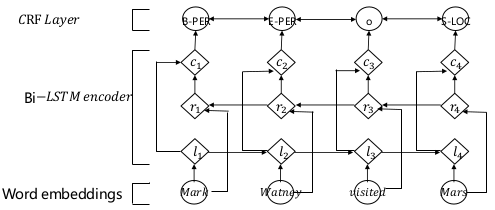
使用深度学习分词
- 使用 word2vec 对语料的词进行嵌入,得到词嵌入后,用词嵌入特征输入给双向 LSTM,对输出的隐层加入一个线性层,然后加入一个 CRF 得到最终实现的模型
混合分词
- 实际工程应用中,多是基于一种分词算法,然后用其他分词算法加以辅助
- 最常用的是先基于词典的分词方式,然后再用统计分词方式进行辅助
词性标注
为句子中的每个单词标注一个正确的词性的程序,即确定每个词是名词、动词、形容词或其他词性的过程
- 词性:词汇最基本的语法属性
- 目的:很多NLP预处理的步骤,如句法分析、信息抽取、经过词性标注后的文本会带来很大的便利性,但也不是不可或缺的步骤
命名实体识别
Named Entities Recognition, NER, 又叫“专名识别”,指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词
- 分类:三大类(实体类、时间类、数字类)和7小类(人名、地名、组织机构名、时间、日期、货币、百分比)
- 作用:与自动分词、词性标注一样,命名实体识别也是自然语言中的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等技术必不可少的部分
- 步骤:
- 实体边界识别
- 确定实体类别(人名、地名、机构名等)
- 难点
- 各类命名实体数量众多
- 命名实体构成规律复杂
- 嵌套情况复杂
- 长度不确定
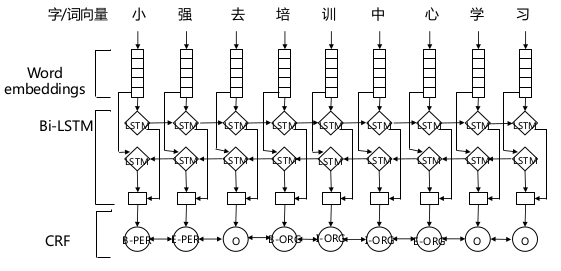
关键词提取
- 分类
- 有监督:主要通过分类的方式进行,通过构建一个比较丰富和完善的词表,然后通过判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到提取关键词的效果
- 无监督:TF-IDF, TextRank, 主题模型算法(LSA, LSI, LDA)
TF-IDF
Term Frequency-Inverse Document Frequency, 词频-逆文档频率算法,是一种基于统计的计算方法,常用于评估在一个文档集中一个词对某份文档的重要程度
- TF算法:一个词在一篇文档中出现的频次
- 一个词在文档中出现的次数越多,其对文档的表达能力越强
- IDF算法:统计一个词在文档集中的多少个文档中出现
- 如果一个词在越少的文档中出现,则其对文档的区分能力就越强
\(|D|\) 是文档集中总文档数,\(|D_i|\) 是文档集中出现词 i 的文档数量
- TF-IDF算法:
TextRank 算法
基本思想来自Google 的 PageRank 算法(1997,拉里佩奇和谢尔盖布林),PageRank 算法是一种链接分析算法
- PageRank
- 链接数量:一个网页被越多的其他网页链接,说明这个网页越重要
- 链接质量:一个网页被一个越高权值的网页链接,则说明这个网页越重要
- TextRank
- PageRank 是有向无权图,而 TextRank 进行关键词提取时是有权图,考虑在同一个窗口内词的共现
LSA/LSI/LDA 算法
Latent Semantic Analysis, 潜在语义分析
Latent Semantic Index, 潜在语义索引
主题模型认为在词和文档之间没有直接的联系,他们应当还有一个维度将它们串联起来,这个维度称为主题。每个文档都应该对应一个或多个主题,而每个主题都会有对应的次分布,通过主题就可以得到每个文档的词分布
- LSA/LSI:都是对文档的潜在语义进行分析,但是潜在语义索引在分析后,还会利用分析的结果建立相关的索引,二者通常被认为是同一种算法。步骤:
- 使用BOW模型将每个文档表示为向量
- 将所有文档词向量拼接起来构成词-文档矩阵(m*n)
- 对词-文档矩阵进行SVD操作([m * r] * [r * r] * [r * n])
- 根据SVD 的结果,每个词和文档都可以表示为r个主题构成的空间中的一个点,通过计算每个词和文档的相似度,可以得到每个文档中对每个词的相似度结果,取相似度最高的一个词即为文档的关键词
- LDA:假设文档中主题的先验分布和主题中词的先验分布都服从狄利克雷分布。然后通过对已有数据集的统计,就可以得到每篇文档中主题的多项式分布和每个主题对应词的多项式分布
- 训练过程:
- 随机初始化,对语料中每篇文档中的每个词w,随机赋予一个topic编号z
- 重新扫描语料库,对每个词w按照吉布斯采样公式重新采样它的topic,在预料中进行更新
- 重复以上语料库的重采样过程直到吉布斯采样收敛
- 统计语料库 topic-word 共现频率矩阵,该矩阵就是LDA的模型
- 然后按照一定的方式针对新的文档的topic进行预估:
- 随机初始化,对当前文档中的每个词w,随机赋予一个topic编号z
- 重新扫描当前文档,按照吉布斯采样公式,重新采样它的topic
- 重复以上过程直到吉布斯采样收敛
- 统计文档中的topic分布即为预估结果
- 训练过程:
句法分析
识别出句子所包含的句法成分以及这些成分之间的依存关系,分为句法结构分析和依存关系分析。一般以句法树来表示句法分析结果。
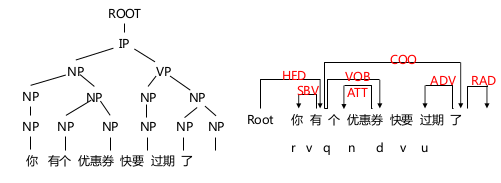
- 句法分析是机器翻译的核心数据结构,是对语言进行深层次理解的基础
- 对复杂句子,标注样本较少的情况下,仅仅通过词性分析,不能得到正确的语句成分关系
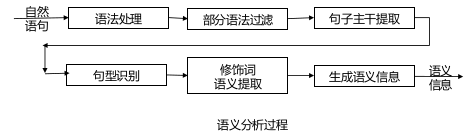
语义分析
编译过程的一个逻辑阶段。语义计算的任务:解释自然语句或篇章各部分(词、词组、句子、段落、篇章)的意义

应用系统
文本分类
- 文本分类:在预定义的分类体系下,根据文本的特征,将给定文本与一个或多个类别相关联的过程。例如:垃圾邮件检测、情感分析等
- 文本聚类(Text clustering):依据同类的文档相似度较大,而不同类的文档相似度较小的聚类假设,将文本进行聚类
- 机器翻译:基于记忆的 -> 基于实例的 -> 统计机器翻译 -> 神经网络翻译
- 问答系统:接受用户以自然语言形式描述的提问,并能从大量的异构数据中查找或推断出用户问题的答案的信息检索系统
自动文摘
- 自动文摘:利用计算机自动地从原始文献中提取文摘,文摘是全面准确地反应某一文献中心内容的简单连贯的短文
- 信息抽取(IE, Information Extraction):把文本里包含的信息抽取出来,然后以统一的形式集成在一起
- 舆情分析:根据特定问题的需要,对针对这个问题的舆情进行深层次的思维加工和分析研究,得到相关结论的过程
- 机器写作:人工只能机器人编写文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号