HCIP-EI v2.0 培训02: 图像处理理论和应用
图像处理理论和应用
内容
描述计算机视觉技术概览
掌握数字图像处理基础和图像预处理技术
理解图像处理基本任务
区分传统特征提取算法和深度学习卷积神经网络
计算机视觉概论
广义上是和图像相关技术的总称,包括图像的采集获取,压缩编码,存储传输,图像合成,三维图像重建,图像增强,图像修复,图像分类识别,目标检测,跟踪,表达和描述,特征提取,图像的显示和输出等等
应用:

相关学科:传统数学、物理学、生物学、心理学、计算机科学、电子工程等、计算机图形学、图像模式识别、图像工程等
人工智能在计算机视觉中最成熟的方向是图像识别,它实现了如何让机器理解图像中的内容
数字图像处理基础
人眼图像
视网膜上分布了光线接收的神经细胞,分为锥状体和杆状体,每只眼睛约有600W-700W个锥状体,对颜色灵敏度高,负责亮光视觉。杆状体有7500W-15000W个,没有颜色感觉,负责暗视觉
图像的感知和获取
数字图像的采集类似人眼,使用大量光敏传感器构成阵列以获取图像。成像质量由传感器的单元数、尺寸和传感性能决定
图像数字化
多数传感器的输出是连续的电压波形,图像数字化是将连续色调的图像转换为计算机能够处理的数字影像的过程
图像数字化包括两个过程:采样和量化
采样
- 将空间上连续的图像变换成离散点的操作
- 采样是按照某种时间间隔或空间间隔,采集模拟信号的过程,即离散化
- 图像数字化的采样过程是将空间上连续的图像变换为离散的点
- 采样的效果由传感器的采样间隔和采样孔径决定,采样间隔 和 采样孔径的大小 是两个很重要的参数
分辨率
- 分辨率是图像中采样点的多少,它决定了图像可辨别的最小细节
- 分辨率由宽、高组成
量化
- 经过采样,图像被分割为空间上离散的像素点,但其灰度是连续的,还不能用计算机进行处理
- 将灰度转换成离散的整数值的过程叫做量化
- 量化是将模拟信号转换为有限个信号等级上的过程,几信号值等级有限化
灰度级
- 表征了每个采样点的传感器输出中可分辨的最小变化
- 灰度级通常是2的整数次幂,用m级或n位来表示灰度级,灰度级越大视觉效果越好。计算机中常用的是8位图像(2的8次幂,最亮到最暗共256个灰度级)
灰度级由高到低:

数字图像的表示
使用矩阵表示一副数字图像
彩色图像
- RGB
- HSV(hue, saturation, value; 色相0-360,饱和度0-1,亮度0-1)
- YUV(Y:亮度,另外两个是色差信号R-Y 和 B-Y)
- 其重要性是它的亮度和色度信号是分离的。只有Y就能表示黑白灰度值
- YUV主要用于图像压缩和传输
- CMYK(C:青,M:品,Y:黄,K:黑)
- 应用于印刷工业
- 四种油墨的不同网点面积率的叠印来表现丰富多彩的颜色和阶调
- Lab
- 比RGB模式和CMYK模式的色彩空间大,自然界中任何颜色都可以在Lab空间中表达出来
空间位置
- 4-邻域
- 对角邻域
- 8-邻域
像素的连通
如果两像素可以通过两两连接的像素关联,那么他们是连通的,所有关联的像素称为他们之间的通路。
连通域
一幅图像中,一个像素集合内部两两连通,并和集合外部的像素都不连通,这样的像素集合被称为连通域。
- 4-连通域
- 8-连通域
距离度量
- 欧式距离
- 曼哈顿距离
- \(D_4(p, q) = |x-s|+|y-t|\)
- 棋盘距离
- \(D_8(p, q) = max(|x-s|+|y-t|)\)
图像的计算
- 算数运算(点操作)
- 加法
- 差分
- 坐标变换(几何操作)
图像预处理技术
图像处理的形式
- 单幅图像输入,单幅图像输出
- 多幅图像输入,单幅图像输出
- 单幅图像输入,输出数字或符号
- 多幅图像输入,输出数字或符号
对于人工智能方向的图像处理任务,最终的结果通常是数字或符号
所以前两种仍然输出图像的处理方法被称统称为图像预处理
图像预处理
目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性、最大限度简化数据,从而改进特征提取、图像分割、匹配和识别的可靠性
- 灰度变换
- 几何矫正
- 旋转等
- 图像增强
- 对比度增强,对比度压缩
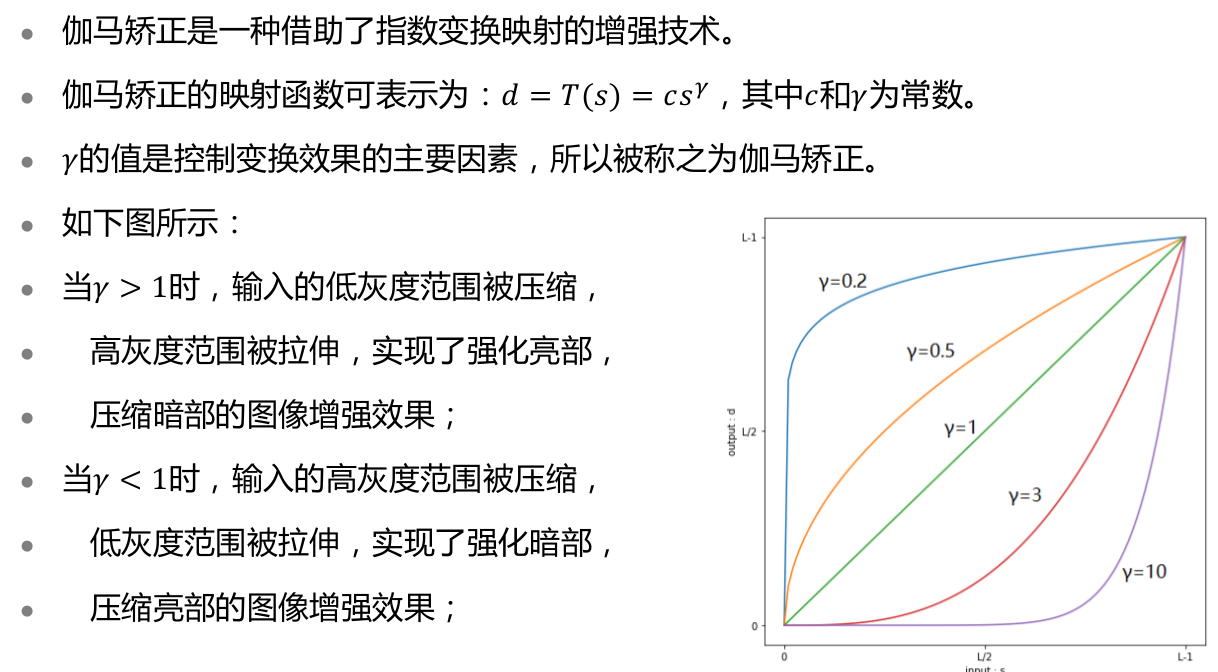
- 伽马矫正
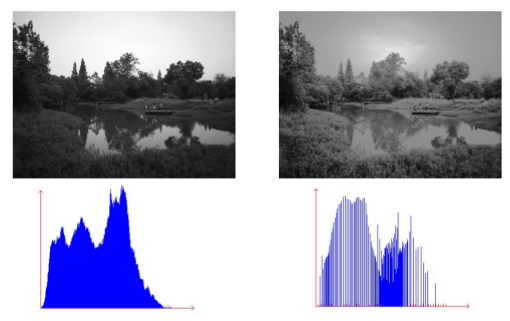
- 直方图均衡
- 使像素值分布趋于均匀
- 图像滤波
- 空间滤波(局部像素计算,卷积)
- 模板滤波
- 均值滤波
- 高斯滤波
- 中值滤波(可消除椒盐噪声 salt& pepper noise)
- 图像锐化(一阶差分,二阶差分)
- 边缘检测
- Prewitt梯度算子,Sobel梯度算子
- Laplacian梯度算子(二阶算子)
- 空间滤波(局部像素计算,卷积)
- 坐标变换
- 平移, 镜像, 旋转, 缩放
- 插值
- 仿射变换
- 平行四边形转换为矩形
- 透视变换
- 任意四边形转换为矩形
插值
实际数字图像中的(x,y)的值都是整数,但坐标变换后得到的坐标(x',y')不一定是整数。非整数坐标处的像素值需要用周围的整数坐标的像素值来进行计算,这个过程叫做插值。
- 最近邻插值法
- 直接用最近邻点的灰度值作为(x',y')的值
- 计算量小,精度低,可能会破坏图像中的线性关系
- 双线性插值
- 采用(x',y')最近邻的四个像素值进行插值计算
仿射变换
二维平面对图像进行线性坐标变换的方法,包括图像平移、缩放、旋转、镜像等。仿射变换保留了图像中的平行性和平直性,即仿射变换后直线和平行线仍然保持直线和平行线。
其中的变换矩阵为仿射变换矩阵。
- 二维码畸变修正示例

透视变换
实际拍的照片都是3维的,图像中的畸变存在近大远小的特点,仿射变换不能进行修正。这时就需要用到三维空间的变换,即透视变换。一种非线性变换。

彩色图像处理
对彩色图像,有两种处理方法,一是将其看做单通道图像的组合体,处理过程中对每个通道的图像单独处理;二是把每个像素看做一个多维向量。直接用向量的表达方式进行图像处理。两种处理方式都十分常用并适合不同的算法。在复杂的图像处理中,两种模式经常切换使用。
色调增强
Hue
- 对HSV空间的H分量进行处理可以实现对图像色调的增强
- 色相H的值对应的是一个角度,并且在色相环上循环。所以色相的修正可能会造成颜色的失真
- 色相的调整通常在H原始值上加上一个小的偏移量,使其在色相环上有小角度的调整。调整后,图像的色调会变成冷色或暖色

饱和度增强
Saturation
- 对HSV空间的S分量进行处理可以实现饱和度的增强
- 饱和度的调整通常是在S原始值上乘以一个修正系数
- 修正系数大于1,会增加饱和度,使图像的色彩更鲜明
- 修正系数小于1,会减小饱和度,使图像看起来比较平淡

亮度增强
Value
- 对HSV空间的V分量进行处理可以实现亮度增强
- 直接将彩色图像灰度化,也可以得到代表图像亮度的灰度图,计算量比HSV颜色空间变换低,但在HSV空间中进行亮度增强处理可以得到增强后的彩色图像

图像数据增强(数据扩充)
缩放,拉伸,加入噪点,翻转,旋转,平移,剪切,对比度调整,通道变换

图像处理基本任务
图像识别
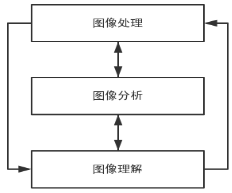
- 图像处理
- 图像分析
- 通过直方图、特征描述和分割等图像处理操作,将以像素描述的图像中感兴趣的目标转变为更简洁的数据描述
- 图像理解
- 主要对图像分析操作提取出的目标进行计算和逻辑推理操作,达到类似人类思维的理解图像内容
- 图像分类
- 目标检测
- 图像分割
- 连通域分割
- 根据连通域将图像中感兴趣的目标趋于分割出来。常用于字符识别技术,比如车牌识别等
- 运动分割
- 利用连续帧图像的运动关系,将图像分割为运动目标前景和场景背景。通过对前景和背景的分离可以实现不同的应用需求
连通域分割:

运动分割:

图像分割性能度量
Dice系数:
目标跟踪
- 首先需要在图像中定位出目标的位置
- 相对于目标检测,目标跟踪技术更强调利用多针图像的连续性,根据上下文相关的信息,预测出目标的准确位置
- 目标跟踪的性能度量和目标检测一样,通过计算gt的iou值,评估跟踪的准确度
文字识别
OCR: Optical Character Recognition
内容检测
图像处理、分析、理解,以识别各种不同模式的目标和对象的技术
自然图像予以内容非常丰富,一个图像包含多个标签内容,可用于相册管理、照片检索和分类、基于场景内容或物体的广告推荐等功能
特征提取和传统图像处理算法
传统图像处理
- 深度学习依赖强大的算力和海量数据集,在这些条件无法满足时,传统图像处理算法仍然能很好地满足一些场景的应用需求
特征提取
将数字图像有效的转换为结构化数据,需要用到图像特征提取的技术降低数据的维度
- 降采样:缩放等
- 分割感兴趣区域
- 特征描述子:使用特征描述子将图像转为固定长度的特征向量
- 二值化
- 阈值分割
- 自适应阈值分割
- 双峰法(适用于对比度较大,且只有两个波峰的情况)
- 最大类间方差法(OTSU)(日本大津提出,又称大津阈值分割法)
- 按图像的灰度特征,将图像分成前景和背景两部分,前景和背景之间的类间方差越大,说明构成图像的两部分的差别越大。当阈值不当分割错误时,会导致前景背景的类间方差变小。因此遍历所有可能的阈值,选择使类间方差最大的分割与之作为最佳阈值。
- 形态学处理
- 模板匹配
- 将模板在图像中滑动,将相应区域作差求平方和,低于阈值认为匹配成功
- 考虑到目标尺寸的不同,实际操作时会使用多个不同尺寸的窗口,这种方法叫做多尺度滑动窗口法
- 特征描述子
- 将图像转成固定长度的特征向量
- 不同的特征描述子描述图像不同属性的特征
- HOG特征、LBP特征和Haar特征等
HOG特征
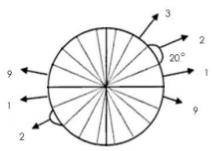
Histogram of Oriented Gradient, 方向梯度直方图
- 将0-360分为18份,每份为20度,对称的角度归为一类,共有9个方向类
- 将图像划分为若干个cell,比如用8*8像素作为一个cell
- HOG特征在应用过程中,有很多优化的变体,例如在深度学习之前效果最佳的目标检测算法,可变形的组建模型(DPM, Deformable Part Model),就使用了改进的HOG特征
LBP
Local BInary Pattern, 局部二值模式
- 一种可以描述图像局部纹理特征的描述子,LBP具有旋转不变性和灰度不变性等显著优点
- 在3*3窗口内,以窗口中心像素值为阈值,将相邻8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样每个像素点会产生8个二进制数,即8位二进制数,这个值反映了该区域的纹理信息
- LBP能很好的表达图像的局部纹理信息,在应用中,LBP被不断改进和优化,发展出圆形LBP算子,旋转LBP算子等。
SVM
- 支持向量机是模式识别中基础的分类算法。配合HOG特征和LBP特征提取出的特征向量,SVM可以很好地完成图像分类和目标检测任务
- SVM的基本想法是寻找最佳分类间隔。对于现行不可分数据,SVM利用核函数将数据隐式映射到高位特征空间中变为线性可分。
行人检测
- HOG对图像角度和光照的形变都能很好地适应。只要杏仁大体上能够保持直立的姿势,一些细微的肢体动作可以被忽略而不影响检测效果。因此HOG特征特别适合做图像中的人体检测的
- 深度学习普及以前,行人检测算法基本上都是用HOG特征加SVM分类器的思路实现的
Haar
- Haar特征定义了四种基本结构,用于提取边缘特征、线性特征、中心特征和对角线特征

- 对ABD,特征数值计算公式为 \(v = sum(白) - sum(黑)\),对于C,计算公式为 \(v = sum(白) - 2 * sum(黑)\)
- 通过改变特征模板的大小和位置,可在图像子窗口中穷举出大量特征
- 在基本的四个Haar特征基础上加入旋转性和比例缩放,产生了更多模式的特征计算结构,能够提取更丰富的图像信息
Adaboost
- Adaboost 是一种经典的自适应boosting方法,可以实现高效地二分类判别
- Adaboost算法就是将多个弱分类器进行合理的结合成一个强分类器。弱分类器一般使用单层决策树模型
- Adaboost每次只训练一个弱分类器,自适应体现在:第N-1次迭代中被错误分类的样本的权值在第N次迭代时会增大,正确样本权重减小,并用来训练下一个弱分类器。每个弱分类器都有对应权重,分类误差率小的弱分类器权重大,在最终的分类函数忠起较大作用。
人脸检测
- Haar特征+Adaboost算法在人脸检测应用中能取得不错的效果
- Haar特征值能反映图像灰度的变化情况。在人脸图像中,脸部的特征能由矩形特征简单地描述,如眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色深等。用Haar特征对正向的人脸检测和一些具备对称性灰度变化的目标都有良好的效果。

深度学习和卷积神经网络
卷积神经网络
1960s,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低前馈神经网络的复杂性,继而提出卷积神经网络
卷积
- 信号与线性系统
- 矩阵论
- 深度学习
深度学习卷积的重要概念
- 卷积核
- 卷积核尺寸:宽高深度
- 特征图:经过卷积核卷积后得到的结果矩阵,每个卷积核会得到一层特征图
- 特征图尺寸:宽高深度,深度即为卷积核个数
- 步长
- 零填充
- 图像不变性
- 旋转、镜像、方向、缩放
卷积神经网络核心思想
- 局部感知
一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是从局部的像素联系较为紧密,而距离较远的像素关联性较弱。因此每个神经元没必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部信息综合起来就得到全局信息。网络部分连通的思想也是受启发于生物学里的视觉系统结构。视觉皮层的神经元就是局部接受信息的
- 参数共享
对输入照片,用一个或多个filter扫描照片,filter自带的参数就是权重,用同一个filter扫描整张图像且这个filter参数保持不变,就是参数共享
卷积神经网络结构
- 输入层
- 卷基层
- 池化层
- 全连接层
- 输出层
不同深度的卷积层提取的特征





池化层
保证平移不变性
全连接层
起到分类器的作用,一般都是用softmax激活函数将输出量化
ILSVRC
ImageNet Large Scale Visual Recognition Challenge,斯坦福ImageNet比赛
ImageNet 是斯坦福大学李飞飞教授于2007年创办,目标是手机大量带有标注信息的图片数据供计算机视觉模型训练。它拥有1500万张标注过的高清图片,总共22000类,其中约100万张标注了图片中主要物体的定位边框。
卷积神经网络
AlexNet
2012
- ReLU
- 重叠的Pooling
- 数据增强
- dropout
VGGNet
2014
- 使用简单的3*3卷积核,不断重复卷积层、池化层,最后经过全连接、softmax
GoogleNet
2014,Google
Inception
Inception v1, 2014
ResNet
Microsoft,2015
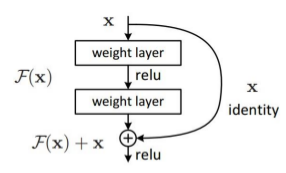
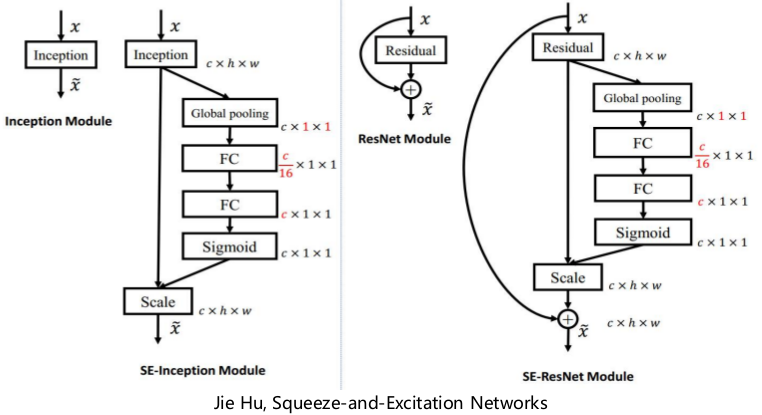
SENet
Squeezed-and-Excitation Networks, 2017

 浙公网安备 33010602011771号
浙公网安备 33010602011771号