
python-基础知识
目录:
0、正则表达式
一、变量和简单数据类型
二、列表
三、操作列表
四、if语句
五、字典
六、用户输入与while循环
七、函数
八、类
九、文件和异常
十、测试代码
################################################################################
0、正则表达式
1、
一 变量和简单数据类型
1. 变量名包含字母/数字/下划线,不能以数字开头;
Python根据缩进来判断代码行与前一个代码行的关系;
2. 字符串处理:字符串单引双引均可以;反斜杠\转义,如果不想转义 字符串前加r,r'ab\t'位abt;'a'*3 为aaa复制三个。
a.title() //对字符串a中的单词首字母大写;
a.upper() //将字符串改为全大写;
a.lower() //将字符串改为全小写;
a.rstrip() //删除字符串末尾的空白;
a.lstrip() //删除字符串开头的空白;
a.strip() //删除字符串两端的空白;
1)撇号位于双引之间:单引号和双引号都可引字符串,单引号中可有双引号,不用转义;双引号中也可有双引号,也不用转义;三引号(单引号或双引号),对应换行的字符串。
2)字符串格式化:%f或%F浮点数,%.4f取到小数点后4位;%b二进制;%d或%i十进制整数;%o八进制;%x 十六进制; %e或%E指数,基底写为e或E;%g或%G,指数e/E或浮点数(根据显示长度)。
3. 数字
a. 3**2表示乘方,9;
b. 浮点数的小数点位数不确定;
>>> 0.1+1.3
1.4000000000000001
c. 将整数类型改为字符串;
str(a) //将非字符串表示为字符串;常在print里打印整数时用;
d. 3/2 结果是1.5,浮点型;3.0/2结果是1.5;3//2为1,取整。
e.复数,可以是浮点,可以用x=a+bj,也可以用complex(a,b) 实数部分和虚数部分为x.real和x.imag
二 列表
1. 用[]表示列表,逗号分分隔;
a=['aa','bb','cc']
a[0].title()即Aa;
a[-2]即倒数第二个;左0开始,右-1开始。
2. 增删查改:
a. append('dd') //结果a=['aa','bb','cc','dd']
a.insert(0,'zz') //结果a=['zz','aa','bb','cc']
del a[0] //结果a=['bb','cc']
b=a.pop() //结果a=['aa','bb'],b=['cc']
b=a.pop(0) //结果b=['aa'],a=['bb','cc']
a.remove('bb) //结果a=['aa','cc'],只删除第一个指定的值;
3. 组织列表:
a.sort() //永久排序,以字母排序;a.sort(reverse=True) //字母顺序降序;不能print(a.sort())
print(a.sorted()) //临时排序,a的值不变;也可加reverse=True;
a.reverse() //结果a倒叙
len(a) //a的长度,3
三 操作列表
1. 遍历整个列表
cats=['cata','catb','catc','catd'] for cat in cats: print(cat.title()+", that is a great cat!") print("\nthank u!") 此行无缩进,只执行1次;有\n中间空一行;
2. 创建数值列表
a. for value in range(1,5):
print(vlaue) 打印1到4
b. numbers=list(range(1,5))
print(numbers) 打印1到4,也可以加步长list(range(1,5,2))结果是1和3
c. 对数字列表执行简单的统计计算
min(numbers) numbers的最小值,max/sum()分别是最大值/总和;
d. 列表解析
squares=[value**2 for value in range(1,11)]
print(squares) 打印1,4,9,16到100
3. 列表的部分元素,切片
a. print(cats[0:3]) 输出0,1,2索引的元素;[:3]不指定第一个索引时从0开始;[3:]表示从索引3到最后;
b. 遍历切片
for cat in cats[:3]:
print(cat.title()) 打印前三个cats元素;[‘’,‘’,‘’,‘’]这种格式打印
c. 复制列表
cat_copy=cats[:] 复制cats表的所有元素到cat_copy
cat_copy=cats 这个是只有一个表,对两个表的操作会同时作用于cat_copy和cats;
4. 元组:不可变的列表(元组:tuple)
a. 访问元组
dimensions=(200,50,10)
print(dimensions[0]) 元组访问元素的方法与列表同;
b. 遍历所有元素
for dimension in dimensions:
print(dimension) 打印(200,50,10)
c. 修改元组变量:重新定义整个元组
5. 设置代码格式
a. PEP 8建议每级缩进都使用四个空格,这既可提高可读性,又留下了足够的多级缩进空间;
可将输入的制表符转换为指定数量的空格;
b. 很多Python程序员都建议每行不超过80字符;
PEP 8还建议注释的行长都不超过72字符,因为有些工具为大型项目自动生成文档时,会在每行注释开头添加格式化字符;
四. if语句
1. 例:
for car in cars:
if car='bmw':
print(car.upper()) else:
print(car.title())
2. 条件测试
car=='bmw' //返回true或false;区分大小写,如果想不区分大小写,可以car.tower(),改成小写比较; car !='bmw' car >= 0 and car <=20 ;用and或or检查多个条件;用in检查特定值是否包含在列表中(not in相反);
3. if-elif-else结构,一个个判断; 中间可加多个elif;最后的else也可不加;
if 'cat1' in cats: print() if 'cat2' in cats: print() 以上两个if,用于测试多个条件时;判断多个元素满足条件;
五. 字典:一系列键值对;值可以是字符串/数字/列表/元组;(字典:dict)
1. 简单字典:
alien_0={'color':'green','points':5}
print(alien_0['color']) //打印green
2. 使用字典
a. 访问字典中的值:alien_0['color']
b. 增加键值对:alien_0['x_position']=0 //在字典里的顺序不确定
c. 先创建一个空字典:alien_0={}
d. 修改字典中的值:alien_0['color']='yellow'
e. 删除键值对:del alien_0['points']
3. 遍历字典
a. 遍历所有的键值对:for key,value in alien_0(): //也可用k,v
b. 遍历字典中的所有键:
for name in alien_0.keys(): print(name.title()) //使用keys() if name in ~: //此处可加一个判断name是不是在某一个列表里;
c. 按顺序遍历字典中的所有键:
for name in sorted(alien_0.keys()) //使用函数sorted按特定顺序排序,字母升序;
d. 遍历字典中的所有值:alien_0.vlaues()
使用集合set,类似于列表,每个元素都必须是独一无二的:set(alien_0.values())
集合set()常用add和update增加和修改集合中数据。
4. 嵌套:将字典存储在列表中,或将列表存储在字典中。
a. 字典列表:
alien_0 = {'color': 'green', 'points': 5}
alien_1 = {'color': 'yellow', 'points': 10}
alien_2 = {'color': 'red', 'points': 15}
aliens = [alien_0, alien_1, alien_2]
b. 在字典中存储列表
pizza = { 'crust': 'thick', 'toppings': ['mushrooms', 'extra cheese'], }
例2:for name, languages in favorite_languages.items(): //name/languages分别代表favorite_languages的键值;
#字典.items() 函数以列表返回可遍历的(键, 值) 元组数组.
c. 在字典中存储字典
users = { 'aeinstein': { 'first': 'albert', 'last': 'einstein', 'location': 'princeton', }, 'mcurie': {'first': 'marie', 'last': 'curie', 'location': 'paris', }, } for username, user_info in users.items(): ....
location=user_info['location']
六. 用户输入和while循环
1. input() //用户输入文本,raw_input()输入的都是字符串;input()则要严格遵守python语法;3.0版本合并了这两个;2.7的版本最好只用raw_input()
a. 例:message = input("Tell me something, and I will repeat it back to you: ")
print(message)
b. 使用int()获取数值;input()获取的是字符串,用int()将字符串形式作为数字;%求模运算;
#int()语法:class int(x, base=10),base默认10进制;若x为数字,则不能有base,作用是取整;若x为str,则base可有可无,此时会检查x是不是base进制,int("9",2)返错,因为2进制没有9,int("1001",2)返回9.
2. while循环
a.使用标志:

prompt = "\nTell me something, and I will repeat it back to you:" prompt += "\nEnter 'quit' to end the program. " active = True while active: message = input(prompt) if message == 'quit': active = False else:
print(message)
b.在循环中使用break/continue;避免无限循环;
3.使用while循环来处理列表和字典
for 循环是一种遍历列表的有效方式,但在for 循环中不应修改列表,否则将导致Python难以跟踪其中的元素。要在遍历列表的同时对其进行修改,可使用while 循环。
a.在列表之间移动元素
# 首先,创建一个待验证用户列表 # 和一个用于存储已验证用户的空列表 unconfirmed_users = ['alice', 'brian', 'candace'] confirmed_users = [] # 验证每个用户,直到没有未验证用户为止 # 将每个经过验证的列表都移到已验证用户列表中
while unconfirmed_users: current_user = unconfirmed_users.pop() //pop()从列表中取值,类似于栈,从后取; print("Verifying user: " + current_user.title()) confirmed_users.append(current_user) # 显示所有已验证的用户 print("\nThe following users have been confirmed:") for confirmed_user in confirmed_users: print(confirmed_user.title())
b.删除包含特性值的列表元素
pets = ['dog', 'cat', 'dog', 'goldfish', 'cat', 'rabbit', 'cat'] print(pets) while 'cat' in pets: pets.remove('cat')
c.使用用户输入来填充字典
responses = {} # 设置一个标志,指出调查是否继续polling_active = True while polling_active: # 提示输入被调查者的名字和回答 name = input("\nWhat is your name? ") response = input("Which mountain would you like to climb someday? ") # 将答卷存储在字典中responses[name] = response # 看看是否还有人要参与调查 repeat = input("Would you like to let another person respond? (yes/ no) ") if repeat == 'no': polling_active = False # 调查结束,显示结果 print("\n--- Poll Results ---") for name, response in responses.items(): print(name + " would like to climb " + response + ".")
七. 函数
1、基本功能
def greet_user(username): print('Hello,'+username.title()+'!') greet_user('min')
a. 关键字实参:传递给函数的名称—值对。以下两个函数调用是等价的,实参的位置与值无关了。
describe_pet(animal_type='hamster', pet_name='harry') describe_pet(pet_name='harry', animal_type='hamster')
b. 默认值:定义函数时给一个默认值,调用函数时有值则可忽略此值。
def describe_pet(pet_name, animal_type='dog'):
c. 让实参变成可选的:
def get_formatted_name(first_name, last_name, middle_name=''): """返回整洁的姓名""" //三个双引号/单引号均可作为注释; if middle_name: full_name = first_name + ' ' + middle_name + ' ' + last_name else: full_name = first_name + ' ' + last_name return full_name.title() musician = get_formatted_name('jimi', 'hendrix') print(musician) musician = get_formatted_name('john', 'hooker', 'lee') print(musician)
d. 返回字典
def build_person(first_name, last_name,age=''): person = {'first': first_name, 'last': last_name} if age: person['age']=age return person musician = build_person('jimi', 'hendrix',age=27) print(musician) 返回{'age': 27, 'last': 'hendrix', 'first': 'jimi'}
e. 传递列表
def greet_users(names): for name in names: msg = "Hello, " + name.title() + "!" print(msg) usernames = ['hannah', 'ty', 'margot'] greet_users(usernames)
f. 禁止函数修改列表:function_name(list_name[:]),将列表的副本传递给函数
例:print_models(unprinted_designs[:], completed_models) //函数获得了所有未打印的设计的名称,但它使用的是列表unprinted_designs 的副本,而不是列 表unprinted_designs 本身。
g. 传递任意数量的实参:
def make_pizza(*toppings): //*toppings 中的星号让Python创建一个名为toppings 的空元组,并将收到的所有值都封装到这个元组中。 //参数中可添加其他形参; def build_profile(first, last, **user_info): //形参**user_info 中的两个星号让Python创建一个名为user_info 的 空字典,并将收到的所有名称—值对都封装到这个字典中。 profile = {} profile['first_name'] = first profile['last_name'] = last for key, value in user_info.items(): profile[key] = value return profile user_profile = build_profile('albert', 'einstein', location='princeton',field='physics') print(user_profile) //打印:{'field': 'physics', 'first_name': 'albert', 'last_name': 'einstein', 'location': 'princeton'}
h. 将函数存储在模块中:import pizza
from module_name import function_0, function_1, function_2 //导入特定的函数,多函数用逗号分隔。 from pizza import make_pizza as mp //导入函数名与现有名称冲突,可用as指定别名。也可以给模块指定别名:import pizza as p。 from pizza import * //导入模块中的所有函数。
2、python列表函数
1)list函数
list() 方法用于将元组转换为列表;
sort() 是list的内置方法,只有list有 :sort(cmp=None, key=None, reverse=False)
sorted()方法是Python内置的,可以对所有可迭代的序列排序生成新的序列,只要可迭代就行,返回的都是一个list:sorted(iterable, cmp=None, key=None, reverse=False) ;
参数:
cmp:比较函数,比较什么参数由key决定。
key:用列表元素的某个属性或函数作为关键字。
reverse:排序规则,可以选择True或者False。
iterable:待排序的可迭代类型的容器
区别:
a.sort()修改待排序的列表内容,返回空,print(a)返回排序后的a;
sorted(a),返回一个新的列表,而对a不产生影响;
2)cmp/len/max/min函数
cmp(list1, list2)
比较两个列表的元素
len(list)
列表元素个数
max(list)
返回列表元素最大值
min(list)
返回列表元素最小值
3)方法
list.append(obj)
在列表末尾添加新的对象
list.count(obj)
统计某个元素在列表中出现的次数
list.extend(seq)
在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.index(obj)
从列表中找出某个值第一个匹配项的索引位置
list.insert(index, obj)
将对象插入列表
list.pop([index=-1])
移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
ist.remove(obj)
移除列表中某个值的第一个匹配项
ist.reverse()
反向列表中元素
list.sort(cmp=None, key=None, reverse=False)
对原列表进行排序
八. 类
1. 创建和使用类
class Dog(): //首字母大写指的是类; def __init__(self, name, age): //Python调用__init__() 来创建Dog 实例时,将自动传入实参self 。每个与类相关联的方法调用都自动传递实参self ,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。 self.name = name self.age = age def sit(self): print(self.name.title()+ " is now sitting.") def roll_over(self): print(self.name.title()+ " rolled over!")
2. 使用类和实例
a. 给属性指定默认值
def __init__(self, make, model, year): self.make = make self.model = model self.year = year self.odometer_reading = 0 // 默认值
b. 修改属性的值
def update_odometer(self, mileage): self.odometer_reading = mileage
3. 继承
a. 定义
class ElectricCar(Car): //父类car def __init__(self, make, model, year): super().__init__(make, model, year) //初始化父类的属性; self.battery_size = 70 python2.7中的继承: class ElectricCar(Car): def __init__(self, make, model, year): super(ElectricCar, self).__init__(make, model, year)
b. 重新父类的方法:直接覆盖
c. 将实例用作属性
class ElectricCar(Car): def __init__(self, make, model, year): super().__init__(make, model, year) self.battery = Battery() my_tesla = ElectricCar('tesla', 'model s', 2016) print(my_tesla.get_descriptive_name()) my_tesla.battery.describe_battery()
4. 导入类
a. 导入单个类:
from car import Car //car是car.py,Car是类;
b. 从一个模块中导入多个类:
from car import Car,ElectricCar
c. 导入整个模块
import car
d. 导入模块中的所有类
from module_name import *
5. python 标准库
from collections import OrderedDict //OrderedDict 实例的行为几乎与字典相同,区别只在于记录了键—值对的添加顺序
九. 文件和异常
文本文件:默认为文本文件。存储普通‘字符’文本,默认为unicode字符集,可以记事本打开。word软件编辑的不是。
二进制文件:把数据内容用‘字节’存储,无法用记事本打开,需要专用软件解码,例图片/音频/视频/doc文档等。
1.文件操作相关模块及属性方法
1)文件操作相关模块
|
名称 |
说明 |
|
io模块 |
文件流的输入和输出操作 input output |
|
os模块 |
基本操作系统功能,包括文件操作 |
|
glob模块 |
查找符合特定规则的文件路径名 |
|
fnmatch模块 |
使用模式来匹配文件路径名 |
|
fileinput模块 |
处理多个输入文件 |
|
filecmp模块 |
用于文件的比较 |
|
cvs模块 |
用于csv文件处理 |
|
pickle和cPickle |
用于序列化和反序列化 |
|
xml包 |
用于xml数据处理 |
|
bz2、gzip、zipfile、zlib、tarfile |
用于处理压缩和解压缩文件(分别对于不同的算法) |
2)文件对象常用属性:
name :返回文件的名字
mode :返回文件的打开模式
closed:若文件被关闭,则返回True;file.closed。
3)文件对象的打开模式
open(name,mode,buffering,encoding=None) #用于打开一个文件,创建一个file对象。name为文件路径和文件名;mode打开模式,r/w/b/a/+,读/写(不存在则创建,存在则重写内容)/追加(不存在则创建,存在则在文件末尾追加内容)/二进制模式/读写模式;r+为读写,w+为读写;buffering=0,不使用缓冲区,仅在二进制模式下有效,=1,仅用于文本模式,使用缓冲区,大于1,则表示缓冲区大小,-1,表示系统默认缓冲区大小;
r/r+/rb+:指针放在文件开始;r/r+文件必须存在;w/w+/wb+:执行后指针在文件开始;a/a+/ab+:文件如果存在,指针在文件结尾。
4)文件对象的常用方法
read()指读(输出)全文;readline()读一行;readlines() 读取整个文件,但是返回的是可迭代对象,是字符串列表,例['a', 'b'];这三个函数每次读完指针都后移。
read([size]) 从文件中读取size个字节或字符的内容返回。例read(4)读取4个字符。
write(a)把字符串a写入到文件中; writelines(b)把字符串列表写入文件中,不添加换行符。
with语句自动执行file.close()来释放文件资源。
seek(offset[,whence]) //把文件指针移动到新的位置,offset表示相对于whence的多少个字节的偏移量;offset:off为正往结束方向移动,为负往开始方向移动;whence:0从文件头开始计算(默认),1从当前位置开始计算,2从文件尾开始计算。
tell() //返回文件指针的当前位置
truncate([size]) //不论指针在什么位置,只留下前size个字节的内容,其余删除。若无size,则从指针位置到末尾全删。
flush() //缓冲区内容写入文件,不关闭文件。
close() //把缓冲区内容写入文件,同时关闭文件,释放文件对象相关资源。
举例:
with open(file,'r+',encoding='utf-8') as f: f.seek(20,0) //20对于英文20个字符,中文指针3为一个字; print(f.tell()) //输出20 print(f.read()) f.seek(20,0) f.truncate(20) f.seek(0,0) print(f.read()) //输出删除后,前20个字节。 结果: 20 know 你知道吗? dont file文件: 你知道吗? dont know
如果加flush()当没有输入回车键时,数据也依然写入到文件中;如果没有flush()方法的话,那么只有按下回车键才会把数据保存到文件中
f = open(file, "w") f.write("aaaaaa") #f.flush() #强行把缓冲区中的内容放到磁盘中 s = input("请输入回车键") f.close()
2. 从文件中读取数据
a. 读取整个文件
with open('pi_digits.txt') as file_object: //关键字with 在不再需要访问文件后将其关闭。文件在python_work中时。 也可以调用open() 和close() 来打开和关闭文件,但这样做时,如果程序存在bug,导致close() 语句未执行,文件将不会关闭。 contents = file_object.read() print(contents) print(contents.rstrip()) //rstrip()删除多出来的空行;
b. 文件路径
with open('text_files/filename.txt') as file_object: //相对文件路径,文件在python_work中;win用反斜杠; file_path = '/home/ehmatthes/other_files/text_files/filename.txt' with open(file_path) as file_object: //也可以绝对路径;
c. 逐行读取
filename = 'pi_digits.txt' with open(filename) as file_object: for line in file_object: print(line)
d. 创建一个包含文件各行内容的列表
filename = 'pi_digits.txt' with open(filename) as file_object: lines = file_object.readlines() for line in lines: print(line.rstrip()) //为删除每行左边的空格,可用strip();
3. 写入文件
a. 写入空文件
filename = 'programming.txt' with open(filename, 'w') as file_object: file_object.write("I love programming.") 可指定读取模式 ('r' )、写入模式 ('w' )、附加模式 ('a' )或让你能够读取和写入文件的模式('r+' );如果你要写入的文件不存在,函数open() 将自动创建它;然而,以写入('w' )模式打开文件时千万要小心,因为如果指定的文件已经存在,Python将在返回文件对象前清空该文件。
b. 写入多行 //需要加换行;file_object.write("I love programming.\n")
c. 附加到文件
with open(filename, 'a') as file_object: file_object.write("I also love finding meaning in large datasets.\n")
4、文件操作补充
1)pickle序列化
序列化反序列化原因:对象本质上是‘存储数据的内存块’,当需要将‘内存块的数据’保存到硬盘上,或者通过网络传到其他计算机上,这时候需要“序列化和反序列化”。
序列化:将对象转换成‘串行化’数据形式,存储到硬盘或通过网络传输到其他地方。
反序列化:相反的过程,将读取到的‘串行化数据’转化成对象。
pickle.dump(obj,file) //obj就是要被序列化的对象,file指的是存储的文件;
pickle.load(file) //从file读物数据,反序列化成对象;
import pickle file='/Users/姓名/min-py/filedemo03' with open(file,'wb') as f: a1='世界' a2=[20,30,40] a3=234 pickle.dump(a1,f) pickle.dump(a2,f) pickle.dump(a3,f) with open(file,'rb') as f: a1=pickle.load(f) a2=pickle.load(f) a3=pickle.load(f) print(a1,a2,a3) 输出: 世界 [20, 30, 40] 234
2)CSV文件的操作
csv(comma Separated Values)是逗号分隔符文本格式,常用于数据交换/excel文件和数据库数据的导入和导出。csv中值没有类型,所有值都是字符串。
import csv with open('/Users/姓名/min-py/csvdemo.csv') as f: f_csv=csv.reader(f) //创建csv对象,它是一个包含所有数据的列表,每一行为一个元素 headers=next(f_csv) //获得列表对象,包含标题行的信息(第一行) print(headers) for row in f_csv: //循环打印各行内容 print(row) 输出: ['姓名', '年龄', '工作', '薪水'] ['张三', '18', '老师', '50000'] csvdemo.csv内容: 姓名,年龄,工作,薪水 张三,18,老师,50000
import csv headers=['工号','姓名','月薪'] rows=[('1001','张三','50000'),('1002','李四','60000')] with open('/Users/姓名/min-py/csvdemo01.csv','w+') as f: f_csv=csv.write(f) f_csv.writerow(headers) //写入一行标题 f_csv.writerows(rows) //写入多行数据 输出: 工号,姓名,月薪 1001,张三,50000 1002,李四,60000
3)os 和os.path模块
os模块可以帮助我们直接对操作系统进行操作。可以直接调用操作系统的可执行文件/命令,直接操作文件/目录等,是系统运维的核心基础。linux的命令行操作更容易,可以通过os.system更容易的调用相关的命令行。
os.system可以直接调用系统的命令。
import os os.system('pip') 结果: 显示pip软件的help(),之后通过exit()。如果是python3,则会调用python3的进程。mac/linux没有os.startfile,可用os.system代替。
>>> import os >>> os.system('ping www.baidu.com') PING www.a.shifen.com (110.242.68.3): 56 data bytes 64 bytes from 110.242.68.3: icmp_seq=0 ttl=51 time=28.213 ms 64 bytes from 110.242.68.3: icmp_seq=1 ttl=51 time=45.092 ms ctrl+z退出
os和os.path下 文件和目录操作:
os下 文件操作:
|
方法名 |
描述 |
|
remove(path) |
删除指定的文件 |
|
rename(src,dest) |
重命名文件或目录 |
|
start(path) |
返回文件的所有属性,win命令。如果是linux或mac,可进到相应目录,然后o s.system('ls -all') |
|
listdir(path) |
返回path目录下的文件和目录列表 |
>>> import os >>> os.rename('text1.txt','one1/text.txt') >>> os.listdir('one1') ['text.txt'] >>> os.remove('one1/text.txt') >>> os.listdir('one1') //返回列表 []
os下 目录操作:
| 方法名 |
描述 |
|
mkdir(path) |
创建目录 |
|
makedirs(path1/path2/path3/...) |
创建多级目录 |
|
rmdir(path) |
删除目录 |
|
removedirs(path1/path2/path3/...) |
删除多级目录 |
|
getcwd() |
返回当前目录 |
|
chdir(path) |
把path设为当前工作目录 |
|
walk() |
遍历目录树 |
|
sep |
当前操作系统所使用的路径分隔符 |
>>> import os >>> os.mkdir('one') >>> os.makedirs('one/one1/one2') >>> os.removedirs('one/one1/one2') >>> os.getcwd() '/Users/姓名' >>> os.mkdir('one') >>> os.chdir('one') >>> os.getcwd <built-in function getcwd> >>> os.getcwd() '/Users/姓名/one' >>> os.mkdir('one1') >>> os.listdir() ['one1'] >>> os.sep //win为\ linux或mac为/ '/' >>> repr(os.linesep) "'\\n'" >>> os.linesep '\n' >>> os.stat('/Users/姓名/one') //返回path指定的路径信息。 os.stat_result(st_mode=16877, st_ino=16112016, st_dev=16777220, st_nlink=3, st_uid=501, st_gid=20, st_size=96, st_atime=1662872562, st_mtime=1662868835, st_ctime=1662868835) >>>os.walk('/Users/姓名/one')
<generator object walk at 0x7fe76b399390>
os.path模块提供了目录相关(路径判断/路径划分/路径连接/文件夹遍历)的操作
| 方法 | 描述 |
| isabs(path) | 判断path是否绝对路径 |
| isdir(path) | 判断path是否为目录(当前目录下) |
| isfile(path) | 判断path是否为文件(当前目录下) |
| exists(path) | 判断制定路径下的文件/目录是否存在(当前目录下) |
| getsize(filename) | 返回文件的大小 |
| abspath(path) | 返回绝对路径 |
| dirname(path) | 返回目录的路径(path至少包括当前目录) |
| getatime(filename) | 返回文件的最后访问时间 |
| getmtime(filename) | 返回文件的最后修改时间 |
| walk(top,func,arg) | 递归方式遍历目录 |
| join(path,*paths) | 连接多个path |
| split(path) | 对路径进行分割,以列表形式返回 |
| splitext(path) | 从路径中分割文件的扩展名 |
>>> os.path.split('/Users/one') //返回元组:目录,文件 ('/Users', 'one') >>> os.path.splitext('/Users/one/text.py') //返回元组:路径,扩展名 ('/Users/one/text', '.py') >>> os.path.join('aa','bb','cc') //返回路径 'aa/bb/cc'
列出指定目录下所有.py文件,并输出文件名:
import os import os.path path=os.getcwd() file_list=os.listdir(path) '''方法1''' for filename in file_list: pos=filename.rfind('.') if filename[pos+1:]=='py': print(filename,end='\t') '''方法2''' file_list2=[filename for filename in os.listdir(path) if filename.endswith('.py')] for filename in file_list2: print(filename,end='\t')
walk()递归遍历所有文件和目录:
os.walk()方法返回一个3个元素的元组,(dirpath,dirnames,filenames),(指定目录的路径/目录下的所有文件夹/目录下的所有文件)。
使用walk()遍历所有文件和目录:
import os all_files=[] path=os.getcwd() list_files=os.walk(path) for dirpath,dirnames,filenames in list_files: for dir in dirnames: //dirnames是该目录下的所有文件夹地址 all_files.append(os.path.join(dirpath,dir)) //此时的dirpath为当前目录 for name in filenames: //filenames是该目录及所有子目录下的所有文件名 all_files.append(os.path.join(dirpath,name)) //此时的dirpath包括所有子目录 for file in all_files: print(file)
4)shutil模块(拷贝和压缩)
是python标准库提供,只有用来做文件和文件夹的拷贝、移动、删除等;还可以做文件、文件夹的压缩、解压缩操作。
shutil.make_archive(base_name, format[, root_dir[, base_dir, verbose, dry_run, owner, group, logger])
base_name:压缩包的文件名,也可以是压缩包的路径;只是文件名时,则保存至当前目录下,否则保存至指定路径。
format:压缩包种类,“zip”, “tar”, “bztar”,“gztar”。
base_dir:指定要压缩文件的路径,可以指定路径下的文件名,也可以指定路径。
root_dir:指定要压缩的路径根目录(默认当前目录),只能指定路径,优先级低于base_dir。
>>> shutil.make_archive('one1','zip','one/') '/Users/姓名/min-py/one1.zip' >>> shutil.make_archive('one1/o','zip','one') '/Users/姓名/min-py/one1/o.zip'
class zipfile.ZipFile(file[, mode[, compression[, allowZip64]]])
创建一个zipfile对象;mode默认值为'r',表示读已经存在的zip文件,'w'表示新建一个zip文档或覆盖一个已经存在的zip文档,'a'表示将数据附加到一个现存的zip文档中;compression表示在写zip文档时使用的压缩方法,它的值可以是zipfile. ZIP_STORED 或zipfile. ZIP_DEFLATED;如果要操作的zip文件大小超过2G,应该将allowZip64设置为True;
>>> z=zipfile.ZipFile('a.zip','w') >>> z.write('one1/demo08.py') >>> z.close()
ZipFile.extractall([path[, members[, pwd]]])
解压zip文档中的所有文件到当前目录。参数members的默认值为zip文档内的所有文件名称列表,也可以自己设置,选择要解压的文件名称。
>>> z2=zipfile.ZipFile('a.zip','r') >>> z2.extractall('one1') //解压到one1目录下。 >>> z2.close()
【例】实现递归的拷贝文件夹内容(使用shutil模块)
>>> shutil.copytree('one','one1',ignore=shutil.ignore_patterns('*.html','*.htm')) //只有one1文件夹不存在时可用。忽略html和htm 'one1'
5. 异常
Python使用被称为异常的特殊对象来管理程序执行期间发生的错误。每当发生让Python不知所措的错误时,它都会创建一个异常对象。如果你编写了处理该异常的代码,程序将继续运行;如果你未对异常进行处理,程序将停止,并显示一个traceback,其中包含有关异常的报告。try-except 代码块处理的;
1、实现结构
1).使用try-except代码块和else代码块:如果try中没有抛出异常,则执行else代码块;如果抛出异常,则执行except,不执行else。
try: answer = int(first_number) / int(second_number) except ZeroDivisionError: print("You can't divide by zero!") else: print(answer)
try 被监控的可能引发异常的语句块 except Exception1: 处理Exception1的语句块 except Exception2: 处理Exception2的语句块 ... except BaseException: 处理可能被遗漏的语句块
3).try...except...finally:finally无论是否发生异常都会执行,通常用来释放try块中申请的资源。
4).由于return有两种作用:结束方法运行/返回值。所以一般不把return放到异常处理结构中,而是放到方法最后(else/finally之后)。
5).常见异常的解决
SyntaxError:语法错误
>>> int a=3 File "<stdin>", line 1 int a=3 ^ SyntaxError: invalid syntax
NameError:尝试申请一个没有申请的变量
>>> print(m) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'm' is not defined
ZeroDivisionError:除数为零错误
>>> 3/0 Traceback (most recent call last): File "<stdin>", line 1, in <module> ZeroDivisionError: division by zero
ValueError:数值错误
>>> float('abc') Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: could not convert string to float: 'abc'
TypeError:类型错误
>>> 123+'abc' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str'
AttributeError:访问对象不存在的属性
>>> a=100 >>> a.sayh() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'int' object has no attribute 'sayh'
IndexError:索引越界异常
>>> a=[1,2,3] >>> a[4] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range
keyError:字典的关键字不存在
>>> a={'a':12,'b':18}
>>> a['c']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'c'
常见异常类型汇总:
| 异常名字 | 说明 |
| ArithmeticError | 所有数值计算错误的基类 |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| BaseException | 所有异类的基类 |
| DeprecationWarning | 关于被弃用的特性的警告 |
|
EnvironmentError |
操作系统错误的基类 |
| EOFError | 没有内建输入,到达EOF标记 |
| Exception | 常规错误的基类 |
| FloatingPointError | 浮点计算错误 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| ImportError | 导入模块/对象失败 |
| IndentationError | 缩进错误 |
| IndexError | 序列中没有此索引(index) |
| IOError | 输入/输出操作失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| KeyError | 映射中没有这个键 |
| LookupError | 无效数据查询的基类 |
| MemoryError | 内存溢出错误(对于Python解释器不是致命的) |
| NameError | 未声明/初始化对象(没有属性) |
| NotImplementedError | 尚未实现的方法 |
| OSError | 操作系统错误 |
| OverflowError | 数值运算超出最大限制 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| ReferenceError | 弱引用(weak reference)视图访问已经被垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| StandardError | 所有的内建标准异常的基类 |
| StopIteration | 迭代器没有更多的值 |
| SyntaxError | python语法错误 |
| SyntaxWarning | 可疑的语法的警告 |
| SystemError | 一般的解释器系统错误 |
| SystemExit | 解释器请求退出 |
| TabError | Tab和空格混用 |
| TypeError | 对类型无效的操作 |
| UnboundLocalError | 访问未初始化的本地变量 |
| UnicodeDecodeError | Unicode解码时的错误 |
| UnicodeEncodeError | Unicode编码时的错误 |
| UnicodeError | Unicode相关的错误 |
| UnicodeTranslateError | Unicode转换时错误 |
| UserWarning | 用户代码生成的警告 |
| ValueError | 传入无效的参数 |
| Warning | 警告的基类 |
| WindowsError | 系统调用失败 |
| ZeroDivisionError | 除(或取模)零(所有数据类型) |
6)with上下文管理
finally一般用做释放代码资源。可以通过with上下文管理,更方便的实现释放资源的操作。
with context_expr [as var]:
语句块
with上下文管理可以自动管理资源,在with代码块执行完毕后自动还原进入该代码之前的现场或上下文,不论何种原因跳出with块,不论是否有异常,总能保证资源正常释放。在文件操作/网络通信相关的场合非常常用。
7)traceback模块
使用traceback模块打印异常信息
>>> import traceback >>> try: ... print('step1') ... num=1/0 ... except: ... traceback.print_exc() ... step1 Traceback (most recent call last): File "<stdin>", line 3, in <module> ZeroDivisionError: division by zero
使用traceback将异常信息写入日志文件
>>> import traceback >>> try: ... print('step1') ... num=1/0 ... except: ... with open('one.txt','a') as f: ... traceback.print_exc(file=f) ... step1 >>> exit() localhost:min-py 姓名$ cat one.txt Traceback (most recent call last): File "<stdin>", line 3, in <module> ZeroDivisionError: division by zero
8)自定义异常类
通常继承Exception或其子类即可,命名一般以Error/Exception为后缀。
自定义异常由raise语句主动抛出。
class AgeError(Exception): def __init__(self,errorInfo): Exception.__init__(self) self.errorInfo=errorInfo def __str__(self): return str(self.errorInfo)+',年龄错误,应该在1-150之间' if __name__=='__main__': age=int(input('input one age:')) if age<1 or age>150: raise AgeError(age) else: print('the age:',age)
输出:
input one age:159 Traceback (most recent call last): File "/Users/姓名/eclipse-workspace/pydemo01/demo01/demo01/exceptiondemo01.py", line 10, in <module> raise AgeError(age) __main__.AgeError: 159,年龄错误,应该在1-150之间
10)开发环境的调试
进行调试的核心是设置断点。
step1:设置断点方法:最前面行号处双击,再双击取消断点。或者是debug视图下,run-toggle breakpoint
step2:进入调试视图:eclipse里进入debug视图。通过run-debug进入。
step3:运行:run-debug或者蜘蛛图标选择文件。
step4:结果检查:右侧variables里是所有参数,属性/类等。下框中console里为运行到断点处的结果。
2、异常类
python中内建异常类的继承层次。
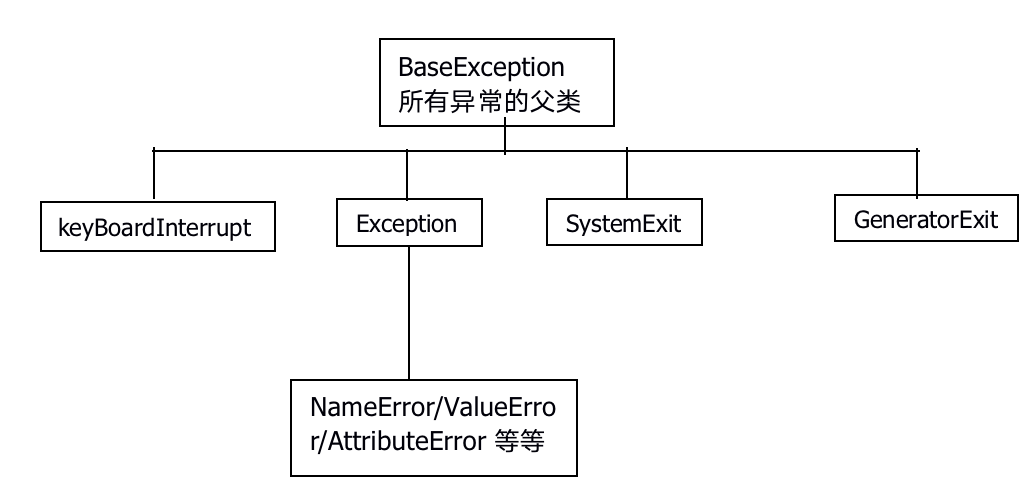
a.例
while True: try: x=int(input('请输入一个数字:')) print('您输入的数字是:',x) if x==88: print('退出程序') break except: print('异常,输入的不是数字!')
b.处理FileNotFoundError异常
filename = 'alice.txt' try: with open(filename) as f_obj: contents = f_obj.read() except FileNotFoundError: msg = "Sorry, the file " + filename + " does not exist." print(msg)
c. 失败时一声不吭
except FileNotFoundError: pass else:
6.存储数据
模块json 让你能够将简单的Python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据。你还可以使用json 在Python程序之间分享数据。
a. 使用json.dump()和json.load()保存和读取用户生成的数据
import json numbers = [2, 3, 5, 7, 11, 13] filename = 'numbers.json' with open(filename, 'w') as f_obj: json.dump(numbers, f_obj) //参数:要存储的数据,用于存储数据的文件对象; 使用json.load()将这个列表读取到内存中: with open(filename) as f_obj: numbers=json.load(f_obj) // print(numbers)
十. 测试代码
1. 单元测试和测试用例:Python标准库中的模块unittest 提供了代码测试工具;
要为函数编写测试用例,可先导入模块unittest 以及要测试的函数,再创建一个继承unittest.TestCase 的类,并编写一系列方法对函数行为的不同方面进行测试。
name_function.py文件: def get_formatted_name(first, last): """Generate a neatly formatted full name.""" full_name = first + ' ' + last return full_name.title() names.py文件: from name_function import get_formatted_name print("Enter 'q' at any time to quit.") while True: first = input("\nPlease give me a first name: ") if first == 'q': break last = input("Please give me a last name: ") if last == 'q': break formatted_name = get_formatted_name(first, last) print("\tNeatly formatted name: " + formatted_name + '.') 测试例test_name_function.py import unittest from name_function import get_formatted_name class NamesTestCase(unittest.TestCase): """测试name_function.py""" def test_first_last_name(self): """能够正确地处理像Janis Joplin这样的姓名吗?""" formatted_name = get_formatted_name('janis', 'joplin') self.assertEqual(formatted_name, 'Janis Joplin') //使用了unittest 类最有用的功能之一:一个断言 方法。断言方法用来核实得到的结果是否与期望的结果一致。 unittest.main() //代码行unittest.main() 让Python运行这个文件中的测试。 输出如下:(第一行句点表明又一个测试通过了,接下来的一行指出Python运行了一个测试,用时不到0.001秒。最后的OK 表明该测试用例中的所有单元测试都通过)
----------------------------------------------------------------------
Ran 1 test in 0.000s OK

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步