

kafka集群部署及使用记录

一、 简介
Kafka是用scala语言编写,由Linkedin公司于2010年贡献给Apache成为一个开源的消息系统,它主要用于处理活跃的流式数据。遵从一般的MQ结构。Kafka对消息保存时根据Topic进行归类,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。Kafka是依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
注意:官方在Kafka 3.0版本中宣布下一次的升级将弃用java8,选择 Java 11 作为最低支持版本。
二、 应用场景
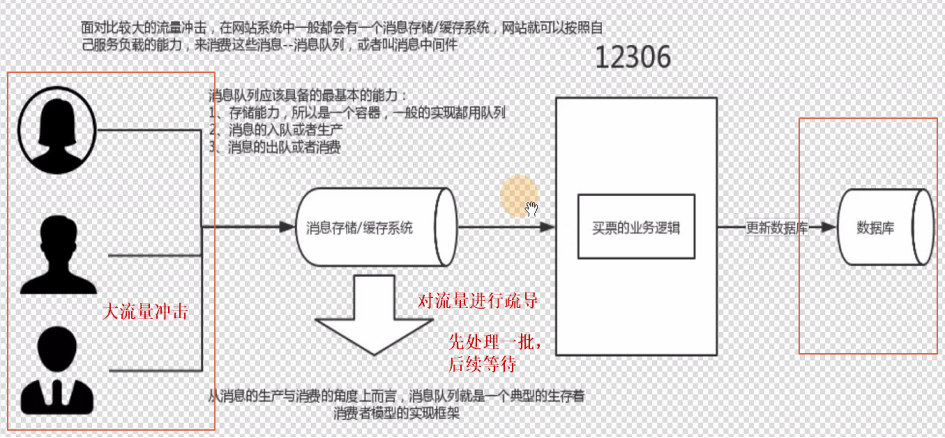
三、 消息传输流程
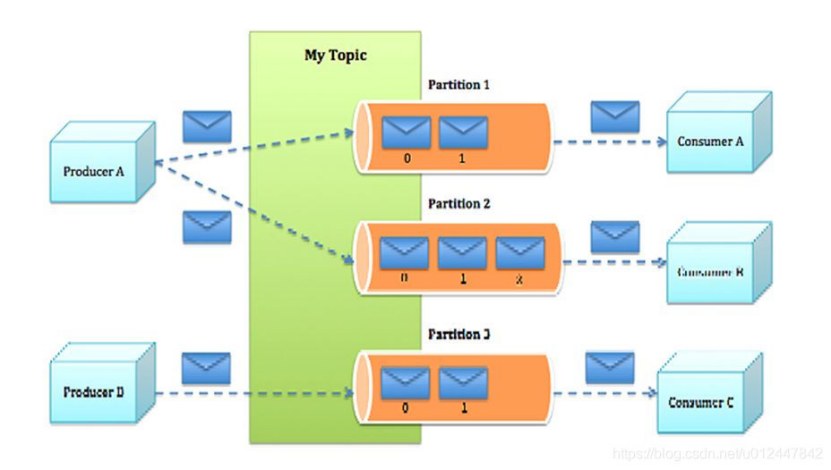
kafka集群的负载均衡:
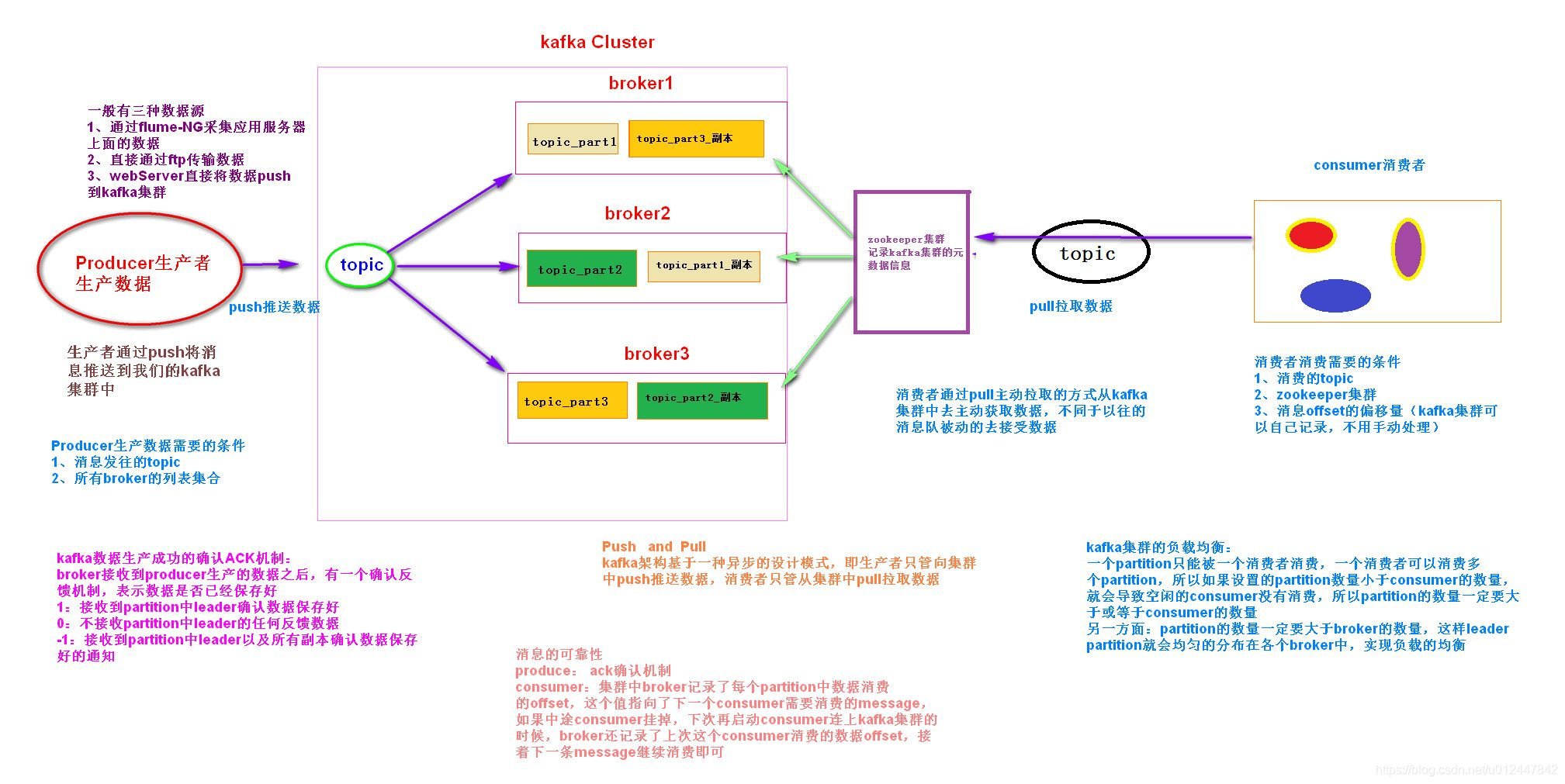
1.一个partition只能被一个消费者消费,一个消费者可以消费多个partition,所以如果设置的partition数量小于consumer的数量,就会导致空闲的consumer没有消费,所以partition的数量一定要大于或等于consumer的数量。
( 注意:topic有多个分区,才能实现多个consumer消费一个topic。)
2.多副本冗余的高可用机制,比如Partition1有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
四、 API
- 基础API:
- Producer :消息生产者,决定消息发送到指定Topic的哪个分区上。
- Consumer :消息消费者,向 Kafka broker 取消息的客户端;
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :经纪人,一台Kafka服务器就是一个broker。一个集群由多个broker 组成。一个broker可以容纳多个topic。
- Topic :主题,可以理解为一个队列,生产者和消费者面向的都是一个 topic。通俗来讲的话,就是放置“消息”的地方,是消息投递的一个容器。假如把消息看作是信封的话,那么 Topic 就是一个邮箱 。
- Partition:为了实现水平扩展和负载均衡,一个非常大的 topic 可以分布到多个 broker(即服务器)上,每台服务器上又可以分为多个 partition,每个 partition 是一个有序的队列;
- Replica:副本(Replication),为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 Kafka仍然能够继续工作,Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- Follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。 leader 发生故障时,某个 Follower 会成为新的 leader。
扩展API:
- Consumer Group:消费者组是 Kafka 提供的可扩展且具有容错性的消费者机 制。组内可以有多个消费者,共享一个公共ID,这个ID 被称为 Group ID。组内的所有消费者协调在一起来消费订阅主题(Topics)的所有分区(Partition)。当然,每个分区只能由同一个消费者组内的一个 Consumer 实例来消费。(新版本的Consumer Group将位移保存在Broker端的内部主题中)
三大特性:
1. 组内可以有一个或多个 Consumer 实例。这里的实例可以是一个单独的进程,也可以是同一进程下的线程。在实际场景中,使用进程更为常见一些。
2. Group ID 是一个字符串,在一个 Kafka 集群中,它标识唯一的一个 Consumer Group。
3. 组内所有主题的单个分区,只能分配给组内的某个 Consumer 实例消费。这个分区当然也可以被其他的 Group 消费。
两大模型:
Kafka仅仅使用Consumer Group这一种机制,却同时实现了传统消息引擎系统的两大模型:
- 如果所有消费者实例都属于同一个Group,那么它实现的是消息队列模型; (队列的处理方式是一组消费者从服务器读取消息,一条消息只由其中的一个消费者来处理。)
2. 如果所有消费者实例分别属于不同的Group,那么它实现的就是发布/订阅模型; (发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。)
2. KRaft模式: kafka之前一直使用Zookeeper来进行所有Broker的管理,每个Broker服务器启动时都会到连接到Zookeeper注册,创建brokers节点,写入IP,端口等信息。当Broker发生状态变化,比 如下线,对应Broker节点也就被删除。2.8版本以后使用 Raft 模式,可以不再依赖Zookeeper,将之前存放在Zookeeper的元数据(元数据将被视为日志)、配置信息都会保存在 @metadata 这个 Topic 中,自动在kafka集群中复制。这样 Kafka 就会简单轻巧很多。
五、 代码实例
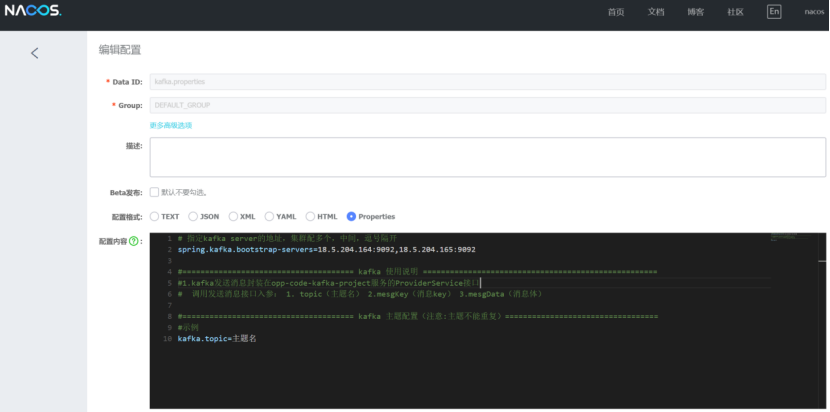
1.配置kafka.properties:
- 封装的生产者:
/**
* kafka封装生产者发送消息
* @param reqDTO 入参:1. topic(主题名)
* 2. mesgKey(消息key)
* 3. mesgData(消息体)
*/
public KafkaResDTO ProviderService(KafkaReqDTO reqDTO) throws Exception {
KafkaResDTO respDTO = new KafkaResDTO();
if (logger.isDebugEnabled()) {
logger.debug(">>>>kafka发送消息入参->{}", reqDTO);
}
if (reqDTO == null) {
logger.error("请求参数为空,kafka消息发送失败。");
respDTO.setRespMesg("请求参数为空,消息发送失败。");
respDTO.setRespCode("500");
return respDTO;
} else {
if (StringUtils.isBlank(reqDTO.getTopic())) {
logger.error("主题为空,kafka消息发送失败。");
respDTO.setRespMesg("主题为空,kafka消息发送失败。");
respDTO.setRespCode("500");
return respDTO;
} else {
try {
kafkaTemplate.send(reqDTO.getTopic(),JSONUtil.toJsonStr(reqDTO.getMesgKey()),JSONUtil.toJsonStr(reqDTO.getMesgData()));
logger.info("kafka消息发送成功:{}", reqDTO);
respDTO.setRespCode("200");
respDTO.setRespMesg("kafka消息发送成功");
} catch (Exception e) {
//e.printStackTrace();
logger.error("kafka发送消息失败:{}", e.getMessage());
respDTO.setRespMesg("kafka发送消息失败:{}" + e);
respDTO.setRespCode("500");
}
}
}
return respDTO;
}
- 消费者(需要引入该项目依赖:opp-code-kafka-project)
@KafkaListener(topics = {"t3"},groupId = "group1",containerFactory="kafkaListenerContainerFactory")
public void m1(ConsumerRecord<String, String> record){
try {
System.out.println("消费key和value "+record.key()+" : "+record.value());
//ack.acknowledge();
logger.info("kafka消息消费成功:{}",record);
} catch (Exception e) {
//e.printStackTrace();
logger.error("kafka消息消费失败:{}",record,e.getMessage());
}
}
六、 消息确认机制
1.生产者:ack确认机制
2.消费者:
1.自动提交确认
2.手动提交确认
#禁止自动提交
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.auto-offset-reset=earliest
#手动确认消息
spring.kafka.listener.ack-mode=manual_immediate
# 批量一次最大拉取数据量
max-poll-records: 3
# 自动提交时间间隔,这种直接拉到数据就提交 容易丢数据
auto-commit-interval: 2000
# 批量拉取间隔,要大于批量拉取数据的处理时间,时间间隔太小会有重复消费
max.poll.interval.ms: 5000
七、 重复消费问题
- 重复消费的原因:
1:消费者端宕机、重启或者被强行kill进程,导致消费者消费的offset没有提交。
2:设置enable.auto.commit为true,如果在关闭消费者进程之前,取消了消费者的订阅,则有可能部分offset没提交,下次重启会重复消费。
3:客户端消费超时被判定挂掉而消费者重新分配分区, 导致重复消费。
- 解决方法:
- 提高消费者的处理速度。例如:对消息处理中比较耗时的步骤可通过异步的方式进行处理、利用多线程处理等。在缩短单条消息消费的同时,根据实际场景可将max.poll.interval.ms值设置大一点,避免不必要的Rebalance。可根据实际消息速率适当调小max.poll.records的值。
- 引入消息去重机制。例如:生成消息时,在消息中加入唯一标识符如消息id等。在消费端,可以保存最近的max.poll.records条消息id到redis或mysql表中,这样在消费消息时先通过查询去重后,再进行消息的处理。
- 保证消费者逻辑幂等性。
八、 可视化工具(Kafka Tool)
- 下载地址:http://www.kafkatool.com/download.html
- 简单使用(查看主题消息):
九、 linux集群部署
1.服务器
18.5.204.164
18.5.204.165
2.JDK
安装环境所需jdk
3.zookeeper
1.使用的是稳定版:zookeeper-3.5.6-bin
官网下载链接:https://zookeeper.apache.org/releases.html
2.将zookeeper包解压在 /home/fwzt/kafka/local文件夹下
3.cd zookeeper-3.5.6/conf/ 然后 cp zoo_sample.cfg zoo.cfg复制一份配置文件并重命名zoo.cfg
4.cd zookeeper-3.5.6/ 然后 新建data和zlog 两个同级文件夹
5.vi zoo.cfg 进行编辑:
修改dataDir路径: dataDir=/home/fwzt/kafka/local/zookeeper-3.5.6/data
修改日志路径:dataLogDir=/home/fwzt/kafka/local/zookeeper-3.5.6/zlog
端口默认:clientPort=2181
配置两台服务器集群: server.0=18.5.204.164:2888:3888
server.1=18.5.204.165:2888:3888
6.cd zookeeper-3.5.6/data 然后 vi myid 输入0 保存(此处是创建serverID,此处的对应zoo.cfg文件里配置集群时在server.后面的那个0)
7.vi /etc/profile 进行编辑:
#zookeeper
export ZOOKEEPER_HOME=/home/fwzt/kafka/local/zookeeper-3.5.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
8.执行 source /etc/profile使文件生效
9.其他集群服务器使用相同配置,只有第6步需要改变:vi myid 输入的节点数字和本服务器节点数字对应。
10.启动:sh zkServer.sh start
(先启动的服务都会报错 属于正常,等最后一台启动后,就都不会再报错)
查看是否启动:zkServer.sh status
此处为启动成功(Mode: follower 为集群副本的从, Mode: leader为集群副本的主)
停止: sh zkServer.sh stop
4.Kafka
1.使用版本:kafka_2.12-2.4.0
官网下载链接:https://kafka.apache.org/downloads
2.将kafka_2.12-2.4.0包解压在 /home/fwzt/kafka/local文件夹下
3.cd kafka_2.12-2.4.0/ 然后 mkdir logs
4.cd kafka_2.12-2.4.0/config/ 然后 vi server.properties 进行编辑:
修改:broker.id=0 (每台此处设置和zookeeper的myid相对应)
修改:listeners=PLAINTEXT://18.5.204.164:9092 (每台服务器使用各自的ip)
修改topic创建分区数:num.partitions=5
修改日志保留时间:log.retention.hours=72
修改日志路径:log.dirs=/home/fwzt/kafka/local/kafka_2.12-2.4.0/logs
修改对应zookeeper的集群ip:zookeeper.connect=18.5.204.164:2181,18.5.204.165:2182
5.vi /etc/profile 进行编辑(覆盖之前zookeeper配置):
#ZOOKEEPER_HOME
export ZOOKEEPER_HOME=/home/fwzt/kafka/local/zookeeper-3.5.6
#kafka
export KAFKA_HOME=/home/fwzt/kafka/local/kafka_2.12-2.4.0
export PATH=$PATH:${KAFKA_HOME}/bin:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
6.执行 source /etc/profile使文件生效
7.其他集群服务器使用相同配置,只需改动 broker.id 和 listeners
8.常规启动:nohup bin/kafka-server-start.sh config/server.properties &
进程守护模式启动:
nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
查看是否启动:ps -ef | grep kafka
关闭:bin/kafka-server-stop.sh
创建主题:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2182 --replication-factor 1 --partitions 1 --topic test
查看所有topic:
.\bin\windows\kafka-topics.bat --list --zookeeper localhost:2182
查看具体topic:
.\bin\windows\kafka-topics.bat --describe --zookeeper localhost:2182 --topic Test
创建生产者:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
创建消费者:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
集群:
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 3 --partitions 3 --topic my-test
bin\windows\kafka-topics.bat --zookeeper localhost:2181,localhost:2182,localhost:2183 --describe --topic my-test
bin\windows\kafka-console-producer.bat --broker-list 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094 --topic test1
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test1 --from-beginning
查询是否有未消费的消息:
kafka的bin目录下,执行命令:
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group group1
可以看到当前的消费进度(CURRENT-OFFSET)、消息进度(LOG-END-OFFSET)、落后量(LAG):

application.properties配置文件版本:
#====================================== kafka 生产者 ==============================================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094
# 写入失败时,重试次数
spring.kafka.producer.retries=3
#指定创建信息nio-buffer缓冲区大小约1M
spring.kafka.producer.buffer-memory=1024000
#累计约1M条就发发送,必须小于缓冲区大小,否则报错无法分配内存(减少IO次数,过大则延时高,瞬间IO大)
spring.kafka.producer.batch-size=1024000
#默认0ms立即发送,不修改则上两条规则相当于无效(这个属性时个map列表,producer的其它配置也配置在这里,详细↑官网,这些配置会注入给KafkaProperties这个配置bean中,供#spring自动配置kafkaTemplate这个对象时使用)
#spring.kafka.producer.properties.linger.ms=1000
#acks=0 把消息发送到kafka就认为发送成功
#acks=1 把消息发送到kafka leader分区,并且写入磁盘就认为发送成功
# acks=all 把消息发送到kafka leader分区,并且leader分区的副本follower对消息进行了同步就任务发送成功spring.kafka.producer.acks=1
#由于网络传输过来的是byte[],生产者端key/value需要序列化(可转为String和Byte数组两种选择)
#spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#====================================== kafka 消费者 ==============================================
#spring.kafka.bootstrap-servers=127.0.0.1:9092 本项目在生产者处已配置kafka的ip
#指定默认的消费组组名
spring.kafka.consumer.group-id: group-test
#自动偏移量: 1.earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# 2.latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# 3.none :topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
spring.kafka.consumer.auto-offset-reset: earliest
# 设置自动提交offset
spring.kafka.consumer.enable-auto-commit=true
#如果设置自动提交offset,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
spring.kafka.consumer.auto-commit-interval=100
#由于网络传输过来的是byte[],消费者端key/value需要反序列化(可转为String和Byte数组两种选择)
#spring.kafka.consumer.key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
消费者手动确认机制:
#禁止自动提交
spring.kafka.consumer.enable-auto-commit=false
spring.kafka.consumer.auto-offset-reset=earliest
#手动确认消息
spring.kafka.listener.ack-mode=manual_immediate
# 批量一次最大拉取数据量
max-poll-records: 3
# 自动提交时间间隔,这种直接拉到数据就提交 容易丢数据
auto-commit-interval: 2000
# 批量拉取间隔,要大于批量拉取数据的处理时间,时间间隔太小会有重复消费
max.poll.interval.ms: 5000
