python内置模块之二
1.random随机数模块
impoprt random
1.random.random()
eg
print(random.random()) # 随机产生一个0-1之间小数
2.random.ranadint() # 随机产生一个区间之间的整数
eg
print(random.randint(1,6)) # 随机产生一个1-6之间的整数
3.random.uniform() # 随机产生一个区间之间的小数
eg
print(random.uniform(1,6)) # 随机产生一个1-6之间的小数
4.random.choice() # 随机抽取一个
eg
print(random.choice(['特等奖','一等奖','二等奖']))
5.random.sample() # 随机抽样 可以设置抽样数
eg
print(random.sample(['安徽省','江苏省','浙江省','山东省'],2))
6.random.shuffle() # 随机打乱容器类型中的元素
eg
l = [1, 2, 3, 4, 5, 6, 7]
print(random.shuffle(l))
2.os模块
该模块主要是与操作系统打交道的
import os
1.os.mkdir() # 创建单层目录
eg
os.mkdir('python学习课程')
2.os.makedirs() # 创建多层目录
eg
os.makedirs(r'python学习课程\第一天课程')
3.os.rmdir() # 删除空目录(文件夹)
eg
os.rmdir('python学习课程')
4.os.removedirs() # 删除多级空目录
eg
os.removedirs(r'python学习课程\第一天课程')
5.os.path.dirname(__file__) # 获取当前文件所在的路径(可以嵌套 则为上一层路径)
eg
BASE_DIR = os.path.dirname(__file__)
6.os.path.join() # 路径拼接 能够自动是被不同操作系统分隔符问题(/ or \)
eg
movie_dir = os.path.join(BASE_DIR,'python学习课程')
7.os.listdir() # 列举出指定路径下的文件名称(任意类型文件)
eg
data_movie_list = os.listdir('D:\py36\python学习课程')
8.os.remove() # 删除一个文件
eg
os.remove('a.txt')
9.os.rename('老文件名','新文件名') # 修改文件名称
eg
os.rename('python学习课程','老男孩python学习课程')
10.os.getcwd() # 获取当前工作路径
eg
print(os.getcwd())
11.os.chdir() # 切换路径
eg
os.chdir('D:/')
with open(r'a.txt','wb')as f:
pass
12.os.path.exists() # 判断路径是否存在 结果为布尔值
eg
print(os.path.exists('python学习课程'))
13.os.path.isfile() # 判断当前路径是否是文件 结果为布尔值
eg
print(os.path.isfile('python学习课程'))
14.os.path.isdir() # 判断当前路径是否是文件夹 结果为布尔值
eg
print(os.path.isdir('python学习课程'))
15.os.path.getsize() # 获取文件大小(字节数)
eg
print(os.path.getsize(r'a.txt'))
3.sys模块
该模块主要与python解释器打交道
import sys
1.sys.path # 获取指定模块搜索路径的字符串集合
2.sys.version # 获取python版本信息
3.sys.platform # 获取当前系统平台
4.sys.argv # 获取当前执行文件的绝对路径
4.序列化模块
json格式数据 跨语言传输
import json
1.json.dumps() # 将python中其他数据转成json格式字符串(序列化)
序列化就是将其他数据类型转成字符串的过程
eg
import json
d = {'username':'jason','pwd':123}
res = json.dumps(d)
print(res,type(res)) # {"username":"jason","pwd":123}
2.json.loads() # 将json格式字符串转成当前语言对应的某个数据类型(反序列化)
反序列化就是将字符串转换成其他数据类型
eg
import json
d = {'username':'jason','pwd':123}
res1 = json.loads(res)
print(res1,type(res1)) # {'username':'jason','pwd':123}<class 'dict'>
bytes_data = b'{"username": "jason", "pwd": 123}'
bytes_str = bytes_data.decode('utf8')
bytes_dict = json.loads(bytes_str)
print(bytes_dict,type(bytes_dict))
3.示例
将字典d写入文件
with open(r'a.txt','w',encoding='utf8') as f:
f.write(str(d))
将字典d取出来
with open(r'a.txt','r',encoding='utf8') as f:
data = f.read()
print(dict(data))
将字典d写入文件
with open(r'a.txt','w',encoding='utf8') as f:
res = json.dumps(d) # 序列化成json格式字符串
f.write(res)
将字典d取出来
with open(r'a.txt','r',encoding='utf8') as f:
data = f.read()
res1 = json.loads(data)
print(res1,type(res1))
d1 = {'username': 'tony', 'pwd': 123,'hobby':[11,22,33]}
with open(r'a.txt', 'w', encoding='utf8') as f:
json.dump(d1, f)
with open(r'a.txt','r',encoding='utf8') as f:
res = json.load(f)
print(res,type(res))
4.注意
并不是所有的数据类型偶读支持序列化
import json
json.JSONEncoder # 查看支持的数据类型
5.subprocess模块
1.作用
1.1可以基于网络连接上一台计算机(socket模块)
1.2让连接上的计算机执行我们需要执行的命令
1.3将命令的结果返回
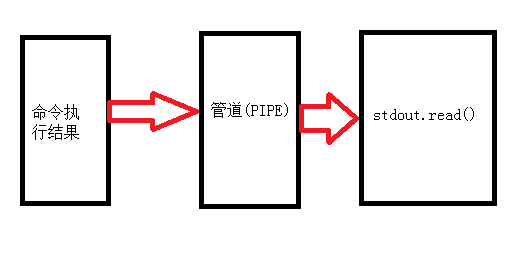
2.subprocess.Popen
eg
res = subprocess.Popen('tasklist',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print('stdout',res.stdout.read().decode('gbk')) # 获取正确命令执行之后的结果
print('stderr',res.stderr.read().decode('gbk')) # 获取错误命令执行之后的结果
ps:windows电脑内部编码默认为GBK
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号