

python的encode()和decode()的用法及实例
1.encode函数的用法及实例
encode()的语法 :str.encode([encoding="utf-8"][,errors="strict"])

参数说明: str:表示需要编码的字符串,用引号引开。 encoding="utf-8":参数可选写,默认编写为"utf-8",常用的是utf-8,保存为中文形式可直接写为"gbk",简体中文为"gb2313"。 errors="strict":参数可选,默认为"strict",表示不兼容则报错。 指定错误处理方式,其可选择值可以是: strict:遇到非法字符就抛出异常。 ignore:忽略非法字符。 replace:用“?”替换非法字符。 xmlcharrefreplace:使用 xml 的字符引用。
用法:将目标字符串str编写为目标二进制数据bytes类型,即为编码过程。
实例:转为目标bytes类型
str = '我爱我的强大的国家——中国' a = str.encode() # 默认编码类型utf-8和报错方式为strict print(a,type(a))
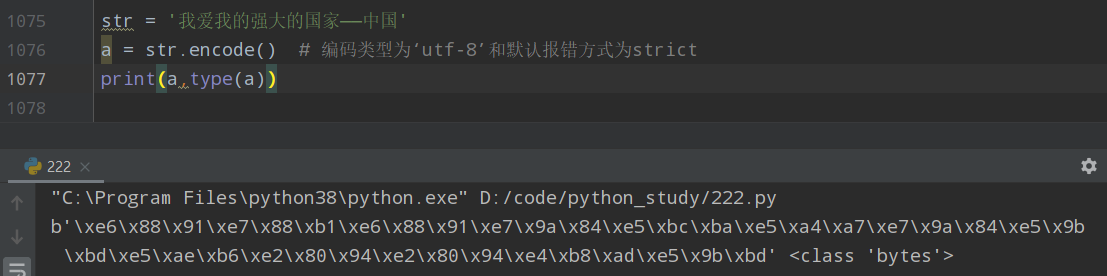
str = '我爱我的强大的国家——中国' a = str.encode(encoding='gbk') # 编码类型为‘gbk’和默认报错方式为strict print(a,type(a))
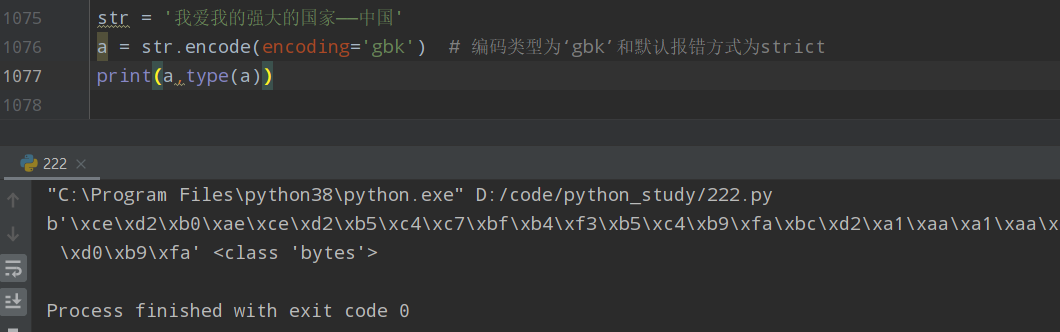
str = '我爱我的强大的国家——中国' a = str.encode(encoding='gb2312', errors='ignore') # 编码类型为‘gbk’和默认报错方式为ignore print(a,type(a))
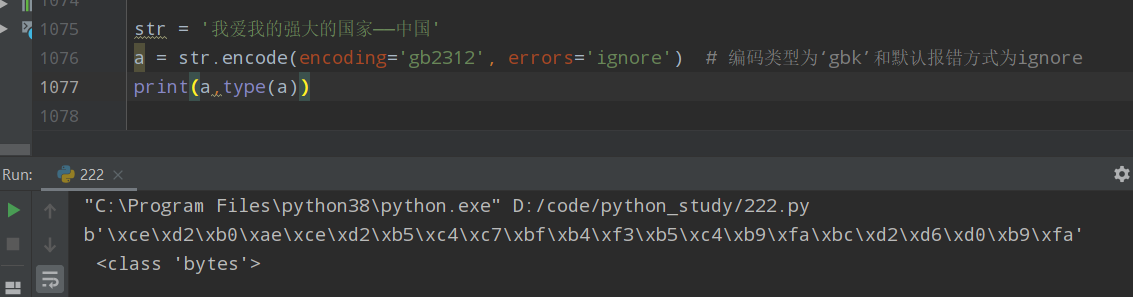
2.decode函数的用法及实例
1)decode()的语法: bytes.decode([encoding="utf-8"][,errors="strict")
参数说明: bytes:表示要进行转换的二进制数据。 encoding="utf-8":参数可选写,默认编写为"utf-8",常用的是utf-8,解码为中文形式可直接写为"gbk",简体中文为"gb2313"。 errors="strict":参数可选,默认为"strict",表示不兼容则报错。 指定错误处理方式,其可选择值可以是: strict:遇到非法字符就抛出异常。 ignore:忽略非法字符。 replace:用“?”替换非法字符。 xmlcharrefreplace:使用 xml 的字符引用。
用法:将目标二进制数据bytes转为目标字符串str类型,即为解码过程。
实例
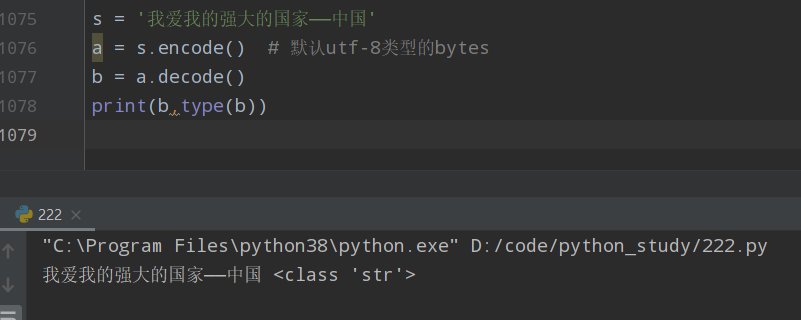
s = '我爱我的强大的国家——中国' a = s.encode() # 默认utf-8类型的bytes b = a.decode() print(b,type(b))
s = '我爱我的强大的国家——中国' a = s.encode(encoding='gb18030') # 解码为gb18030 b = a.decode(encoding='gb18030') print(b,type(b))
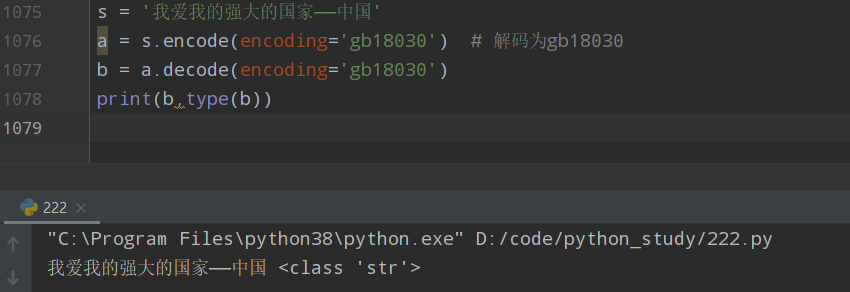
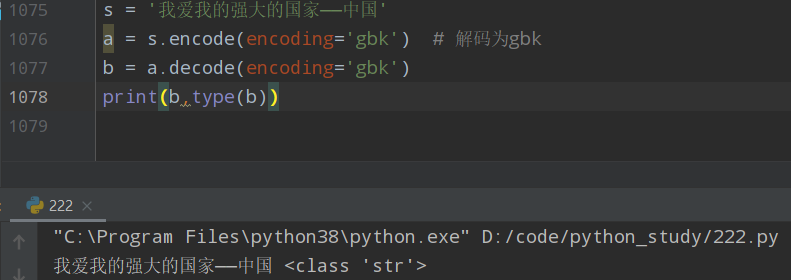
s = '我爱我的强大的国家——中国' a = s.encode(encoding='gbk') # 解码为gbk b = a.decode(encoding='gbk') print(b,type(b))
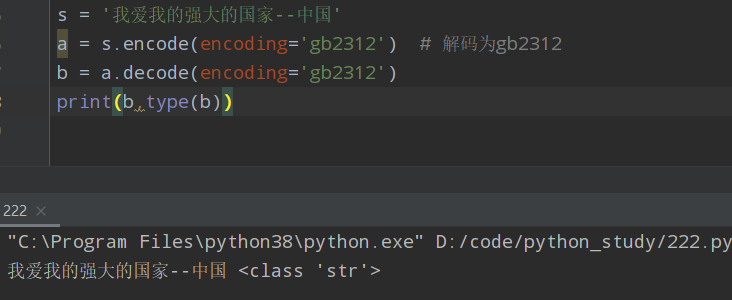
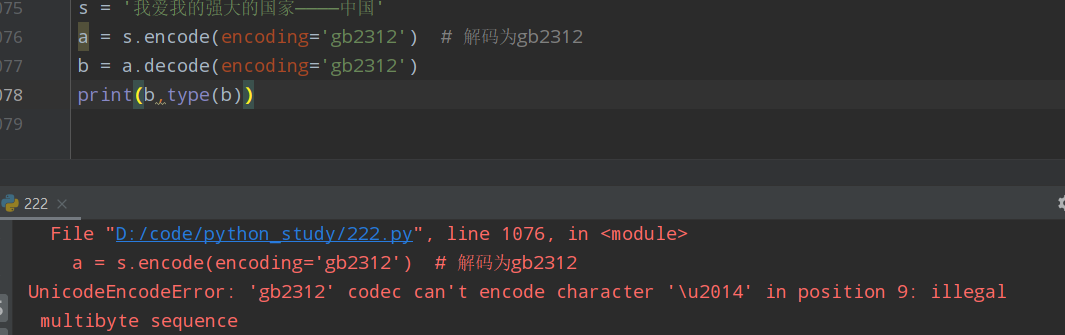
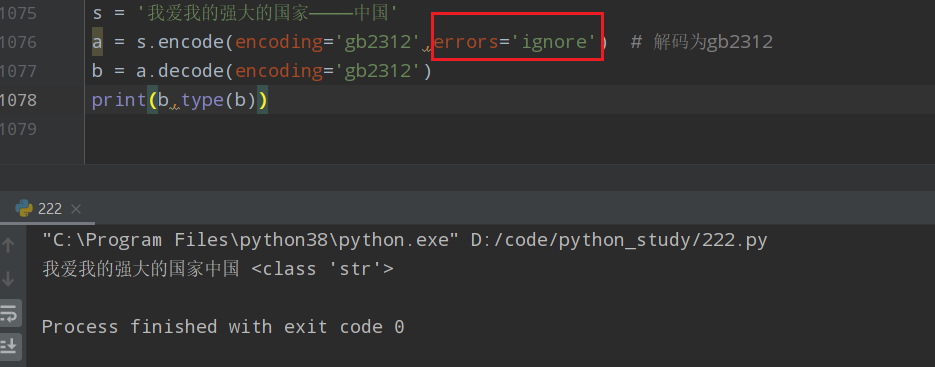
s = '我爱我的强大的国家--中国' a = s.encode(encoding='gb2312') # 解码为gb2312 b = a.decode(encoding='gb2312') print(b,type(b))
3.常见报错和解决方法
(1)UnicodeEncodeError:因特殊符号在某编码不存在/不兼容而报错
报错原因:一些特殊符号在编码的gb2312中不存在无法编码。图中不存在的是“——”,所以报错显示第9+1的位置存在不能编写为“gb2312”的字符,所以报错。
解决办法1:将 'gb2312'改成兼容更多的编码比如gbk或者gb18030。所以,此种情况,可以尝试用和当前编码(gb2312)兼容的但所包含字符更多的编码(gb18030)去解码。
兼容性:gb2312<gbk<gb18030
解决办法2:一种忽略错误的方法是将errors报错方式设置为“ignore”,但是一般不选择这个方法。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界