

1、什么是感知机(Perception)
感知机是生物神经细胞的简单抽象。神经细胞结构大致可分为:树突、突触、细胞体及轴突。单个神经细胞可被视为一种只有两种状态的机器——激动时为‘是’(+1,表示),而未激动时为‘否’(-1表示)。神经细胞的状态取决于从其它的神经细胞收到的输入信号量(变量X),及突触的强度(抑制或加强,参数W)(函数F(X))。当信号量总和超过了某个阈值时,细胞体就会激动,产生电脉冲。电脉冲沿着轴突并通过突触传递到其它神经元。为了模拟神经细胞行为,与之对应的感知机基础概念被提出,如权量(突触)、偏置(阈值)及激活函数(细胞体)。
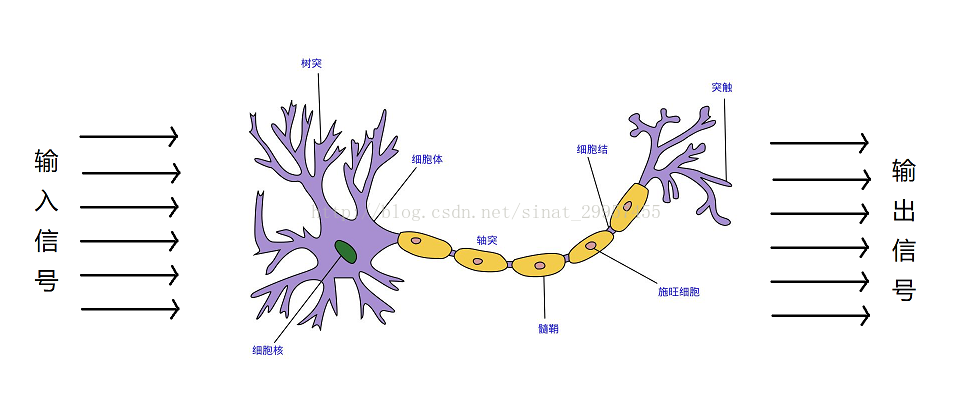
整个过程可以用下图抽象
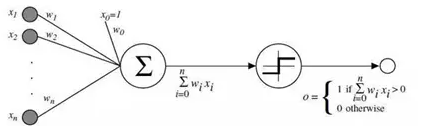
由于感知机有两个状态:激动状态(+1)或者不激动状态(-1),因此感知机可以用于二分类。
感知机是一个相当简单的模型,是支持向量机(通过简单地修改一下损失函数)、神经网络(通过简单的叠加)的基础。
2、感知机的数学模型
线性可分:对于一个数据集 (xi为输入,yi为标签),如果存在一个超平面Π,能够将D中正负样本(对于某个样本(xi,yi),若 yi =1 则称其为正样本,若 yi =-1 则称其为负样本,且标签 yi 只能取正负 1 这两个值)分开,那么就称 D 是线性可分的。否则,就称是线性不可分的。
(xi为输入,yi为标签),如果存在一个超平面Π,能够将D中正负样本(对于某个样本(xi,yi),若 yi =1 则称其为正样本,若 yi =-1 则称其为负样本,且标签 yi 只能取正负 1 这两个值)分开,那么就称 D 是线性可分的。否则,就称是线性不可分的。
如果数据集线性可分,那么感知机一定能够将数据集的每个数据区分开。
感知机模型:
f(X)=sign(w*X+b),其中sign是符号函数。
感知机模型,对应着一个超平面w*X+b=0,这个超平面的参数是(w,b),w是超平面的法向量,b是超平面的截距。
目标就是找到一个(w,b),能够将线性可分的数据集T中的所有的样本点正确地分成两类。
如果有某个点(Xi, yi),使得yi(w*Xi)<0,则称超平面w*X对该点分类失败。采用所有误分类的点到超平面的距离来衡量分类失败的程度。
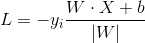
W为常数,所以
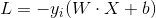
所以寻找(w,b)问题转化为最小化损失函数,即转化为一个最优化问题。(损失函数越小,说明误分类的样本点“越少”---或者说分类失败的程度越低)
3、计算推导
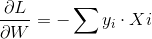
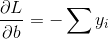
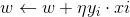
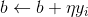
4 感知机的对偶形式
w,b都取零,那么迭代多次后,有
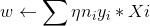
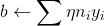
其中 ni 是指某个样品{ Xi,yi}被使用了 ni 次,若设 ai=ηni,那么
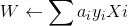
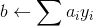
那么更新 w.b 就相当于更新 ai<--η(ni+1)
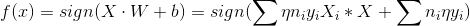
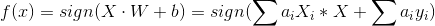
这里涉及计算: Xi*Xj 可通过实现计算好的 gram 矩阵直接调用 Gij
1 #coding:utf-8 2 3 ''' 4 author@令狐葱 5 date:08/17/2018 6 ''' 7 8 import numpy as np 9 #感知机原始形式进行编程,求解李航<统计机器学习实例> 10 11 class Perception_primitive: 12 def __init__(self,X,y,eta=1,iternum=1000):###初始化,输入X,y,以及迭代次数 13 self.X=np.array(X) ##转化为 Numpy 阵列 14 self.y=np.array(y) ##转化为 Numpy 阵列 15 self.b=0 ##偏置为零 16 self.eta=eta ##学习率,默认为1 17 col=self.X.shape[1] 18 self.W=np.zeros((col))###权重,默认为0 19 self.iternum=iternum ###最大迭代次数 20 ####初始化结果 21 print("#####START######") 22 print("X=",self.X,"\ny=",self.y,"\nW=",self.W,"\nb=",self.b) 23 print("###############") 24 def update(self,Xi,yi): ###迭代更新, w,b 25 self.W=self.W+yi*Xi*self.eta 26 self.b=self.b+yi*self.eta 27 28 29 def fit(self): ##拟合 30 length=len(self.X) 31 print("iter", "X ","y ","W ","b ") 32 iter_num=0 33 for j in range(self.iternum): 34 count=0##判断每次更新参数后,记录分类错误的次数 35 36 37 for i in range(length): 38 temp=self.predictive(self.X[i],self.y[i])###计算损失函数 39 40 if temp < 0: ##分类错误时,更新参数 41 count+=1 42 self.update(self.X[i],self.y[i]) 43 iter_num+=1 44 print(iter_num ,self.X[i], self.y[i], self.W,self.b) 45 if count==0: ###在新参数下,所有的分类都是正确的 46 print("$$$$$$END$$$$$$$$$") 47 return self.W,self.b 48 break 49 def predictive(self,Xi,yi): 50 temp=yi*(np.dot(Xi,self.W)+self.b) 51 if temp <=0: return -1 52 if temp >0: return 1 53 54 55 if __name__=="__main__": 56 X=np.array([[3,3],[4,3],[1,1]]) 57 y=np.array([1,1,-1]) 58 p=Perception_primitive(X,y) 59 p.fit() 60 print("W=",p.W,"\nb=",p.b)
测试结果
#####开始###### X= [[3 3] [4 3] [1 1]] y= [ 1 1 -1] W= [0. 0.] b= 0 ############### iter X y W b 1 [3 3] 1 [3. 3.] 1 2 [1 1] -1 [2. 2.] 0 3 [1 1] -1 [1. 1.] -1 4 [1 1] -1 [0. 0.] -2 5 [3 3] 1 [3. 3.] -1 6 [1 1] -1 [2. 2.] -2 7 [1 1] -1 [1. 1.] -3 $$$$$$$$$$$$$$$$$$$$$ W= [1. 1.] b= -3

1 #coding:utf-8 2 import numpy as np 3 class Perception_Dual: 4 def __init__(self,X,y,eta=1,iter_loop=1000):##初始化 W,b,eta,alfa,Gram 5 self.X=X ###样品数据 6 self.y=y###样品分类 7 self.eta=eta ##学习效率 8 self.b_final=self.b=0##参数 b 9 self.Xnum=self.X.shape[0]###样品数量 10 self.iter_loop=iter_loop###迭代最大次数 11 self.alfa=np.zeros(self.Xnum)### alfa 参数数量和样品数量一样 12 self.Gram=np.zeros([self.Xnum,self.Xnum])###初始化 Gram 矩阵为零 13 self.cal_Gram()##根据 X 值计算 Gram 14 self.W_final=self.W=np.zeros(self.X.shape[1])###存储寻找到的 W,b 15 16 def fit(self): 17 iter_num=0 18 print("######迭代#######") 19 for j in range(0,self.iter_loop):###迭代 iter_loop 次 20 count=0 ##记录分类错误的次数 21 for i in range(0,self.Xnum):##对所有的样品的分类 22 Loss_Fun=self.cal_classify(i) 23 if Loss_Fun <=0: 24 self.update(i) 25 iter_num+=1 26 print("第%d次"%iter_num) 27 print("X=",self.X[i]) 28 print("alfa=",self.alfa) 29 print("W=",self.W) 30 print('b=',self.b) 31 print("=====================") 32 count+=1 33 break 34 if count==0: 35 self.W_final=self.W 36 self.b_final=self.b 37 print("######迭代结束######") 38 break 39 40 def cal_Gram(self):###计算 Gram 41 for i in range(0,self.Xnum): 42 for j in range(0,self.Xnum): 43 self.Gram[i,j]=np.dot(self.X[i],self.X[j]) 44 45 def update(self,k): ###更新 alfa,W,b 46 self.alfa[k]=self.alfa[k]+self.eta 47 self.b=self.b+self.y[k] 48 self.W=np.zeros(self.X.shape[1]) 49 self.b=0 50 for i in range(0,len(self.X)): 51 self.W+=self.alfa[i]*self.y[i]*self.X[i] 52 self.b+=self.alfa[i]*self.y[i] 53 54 55 def cal_classify(self,k):###计算损失函数 56 temp=0 57 for i in range(0,self.Xnum): 58 temp+=self.alfa[i]* self.y[i]*self.Gram[i,k] 59 temp=temp+self.b 60 temp=y[k]*temp 61 62 if temp > 0: 63 return 1 64 if temp <= 0: 65 return -1 66 67 def predict(self,X):###使用寻找到 W,b ,预测新样品 68 temp=np.dot(self.W_final,X)+self.b_final 69 if temp >0 : 70 return 1 71 if temp <=0: 72 return -1 73 74 def print_Wb(self): 75 print("Final_W=") 76 print(self.W_final) 77 print("Final_b=") 78 print(self.b_final) 79 def print_alfa(self): 80 print("^^^^^^^^^^^^^^^^^^^^^^^^") 81 print("alfa=") 82 print(self.alfa) 83 print("@@@@@@@@@@@@@@@@@@@@@@@@") 84 85 86 87 if __name__=="__main__": 88 X=np.array([[3,3],[4,3],[1,1]]) 89 y=np.array([1,1,-1]) 90 p=Perception_Dual(X,y) 91 print("alfa初始值") 92 print(p.alfa) 93 print("Gram=") 94 print(p.Gram) 95 p.fit() 96 p.print_Wb() 97 p.print_alfa() 98 xk=p.predict([5,-5]) 99 print(xk)
1 alfa初始值 2 [0. 0. 0.] 3 Gram= 4 [[18. 21. 6.] 5 [21. 25. 7.] 6 [ 6. 7. 2.]] 7 ######迭代####### 8 第1次 9 X= [3 3] 10 alfa= [1. 0. 0.] 11 W= [3. 3.] 12 b= 1.0 13 ===================== 14 第2次 15 X= [1 1] 16 alfa= [1. 0. 1.] 17 W= [2. 2.] 18 b= 0.0 19 ===================== 20 第3次 21 X= [1 1] 22 alfa= [1. 0. 2.] 23 W= [1. 1.] 24 b= -1.0 25 ===================== 26 第4次 27 X= [1 1] 28 alfa= [1. 0. 3.] 29 W= [0. 0.] 30 b= -2.0 31 ===================== 32 第5次 33 X= [3 3] 34 alfa= [2. 0. 3.] 35 W= [3. 3.] 36 b= -1.0 37 ===================== 38 第6次 39 X= [1 1] 40 alfa= [2. 0. 4.] 41 W= [2. 2.] 42 b= -2.0 43 ===================== 44 第7次 45 X= [1 1] 46 alfa= [2. 0. 5.] 47 W= [1. 1.] 48 b= -3.0 49 ===================== 50 ######迭代结束###### 51 Final_W= 52 [1. 1.] 53 Final_b= 54 -3.0 55 ^^^^^^^^^^^^^^^^^^^^^^^^ 56 alfa= 57 [2. 0. 5.] 58 @@@@@@@@@@@@@@@@@@@@@@@@ 59 -1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号