
无监督学习之聚类2——DBSCAN
根据学生月上网时间数据运用DBSCAN算法计算:
#coding=utf-8
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as plt
mac2id = dict()
onlinetimes = []
f = open('F:\data\TestData.txt', encoding='utf-8')
for line in f:
mac = line.split(',')[2]#取得mac地址,例如第一行A417314EEA7B
onlinetime = int(line.split(',')[6])#上网时长
starttime = int(line.split(',')[4].split(' ')[1].split(':')[0])#开始时间只取第一个":"分割的:小时
#每一个onlinetimes有一个唯一的mac2id对应
if mac not in mac2id:
mac2id[mac] = len(onlinetimes)
onlinetimes.append((starttime, onlinetime))
else:
onlinetimes[mac2id[mac]] = [(starttime,onlinetime)]
#print(onlinetimes)
real_X = np.array(onlinetimes).reshape((-1, 2))#自行构造一个2列的矩阵,-1构造未知行数
#print(real_X)
X = real_X[:, 0:1]#只取上网开始时
#print(X)
#调用DBSCAN方法进行训练,labels为每个数据的簇标签
db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X)
#返回的数据的簇标签,噪声数据标签为-1
'''#上网时长聚类
X = np.log(1+real_X[:, 1:])
db = skc.DBSCAN(eps=0.04, min_samples=10).fit(X)
'''
labels = db.labels_
print('Labels:\n', labels)
#计算簇标签为-1的噪声数据比率
raito = len(labels[labels[:] == -1])/len(labels)
print('Noise raito: ', format(raito, '.2%'))
#计算簇个数
n_clusters_ = len(set(labels))-(1 if -1 in labels else 0)
print('Estimated numbe of clusters: %d' %n_clusters_)#簇个数
print('Silhouette Coefficient: %0.3f' %metrics.silhouette_score(X, labels))#聚类效果评价指标
#打印各簇标号和簇内数据
for i in range(n_clusters_):
print('Cluster', i, ':')
print(list(X[labels == i].flatten()))
#绘制直方图
plt.hist(X, 24)
plt.show()
运行结果:
Labels:
[ 0 -1 0 1 -1 1 0 1 2 -1 1 0 1 1 3 -1 -1 3 -1 1 1 -1 1 3 4
-1 1 1 2 0 2 2 -1 0 1 0 0 0 1 3 -1 0 1 1 0 0 2 -1 1 3
1 -1 3 -1 3 0 1 1 2 3 3 -1 -1 -1 0 1 2 1 -1 3 1 1 2 3 0
1 -1 2 0 0 3 2 0 1 -1 1 3 -1 4 2 -1 -1 0 -1 3 -1 0 2 1 -1
-1 2 1 1 2 0 2 1 1 3 3 0 1 2 0 1 0 -1 1 1 3 -1 2 1 3
1 1 1 2 -1 5 -1 1 3 -1 0 1 0 0 1 -1 -1 -1 2 2 0 1 1 3 0
0 0 1 4 4 -1 -1 -1 -1 4 -1 4 4 -1 4 -1 1 2 2 3 0 1 0 -1 1
0 0 1 -1 -1 0 2 1 0 2 -1 1 1 -1 -1 0 1 1 -1 3 1 1 -1 1 1
0 0 -1 0 -1 0 0 2 -1 1 -1 1 0 -1 2 1 3 1 1 -1 1 0 0 -1 0
0 3 2 0 0 5 -1 3 2 -1 5 4 4 4 -1 5 5 -1 4 0 4 4 4 5 4
4 5 5 0 5 4 -1 4 5 5 5 1 5 5 0 5 4 4 -1 4 4 5 4 0 5
4 -1 0 5 5 5 -1 4 5 5 5 5 4 4]
Noise raito: 22.15%
Estimated numbe of clusters: 6
Silhouette Coefficient: 0.710
Cluster 0 :
[22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22]
Cluster 1 :
[23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23]
Cluster 2 :
[20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20]
Cluster 3 :
[21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21]
Cluster 4 :
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8]
Cluster 5 :
[7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
根据上网开始时间分类直方图如下:
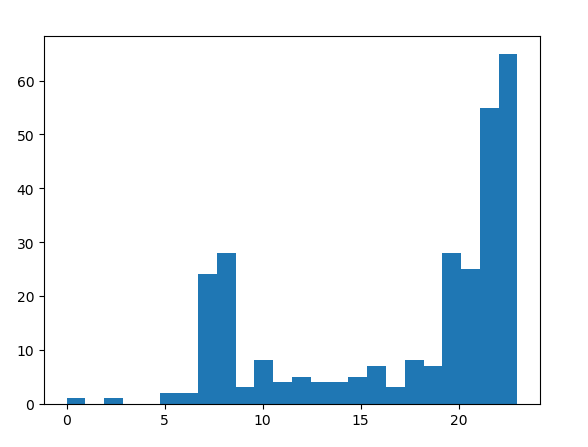
根据上网时间聚类直方图如下:

根据上网开始时间明显要好于上网时长聚类.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号