增强学习笔记 第十章 On-Policy控制的近似
10.1 片段性任务的半梯度控制

10.2 n步Sarsa控制

10.3 平均奖励:连续任务的新设定
定义一个策略的优劣函数:依照该策略执行的平均奖励
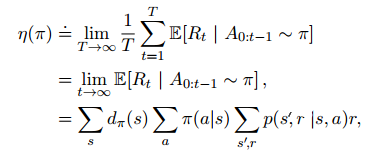
其中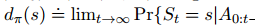 和起始状态无关,称为各态遍历性。早期任何决策的影响都是暂时性的,长期的平均收益仅仅取决于策略本身和环境的转移概率
和起始状态无关,称为各态遍历性。早期任何决策的影响都是暂时性的,长期的平均收益仅仅取决于策略本身和环境的转移概率
$\eta$函数用来评估一个策略的优劣已经足够。获得最大$\eta$函数的策略称为最优策略。
在平均奖励的设定下,回报被定义为奖励和平均奖励的差
![]()
Bellman方程也可以写为:
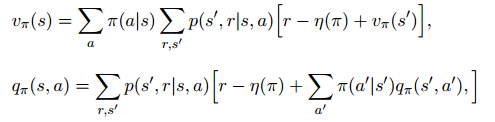
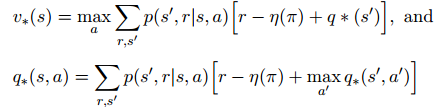
TD误差可以写为:
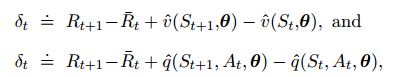
迭代式为:
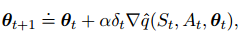

10.4 折扣设定的废弃
在折扣设定下,平均奖励为: 因此折扣设定已经没有必要
因此折扣设定已经没有必要
10.5 n步差分半梯度Sarsa
回报:
![]()
TD误差:
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号