
增强学习笔记 第四章 动态规划
最优价值函数满足下列条件:

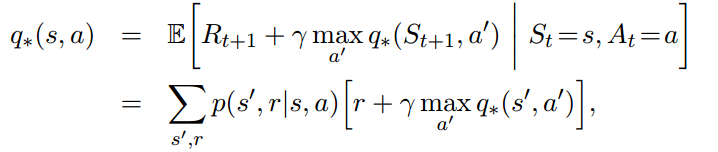
4.1 策略评估
策略评估通过反复迭代的方式来进行:
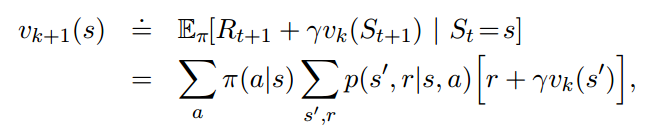

4.2 策略改进

4.3 策略迭代
综合4.1和4.2,得到策略迭代算法:

4.4 价值迭代
对4.3进行简化,两步合为一步:
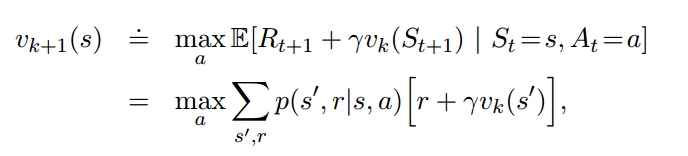

4.5 异步动态规划
通过安排迭代顺序,而不是每次都整个扫一遍,来更快地获得我们想要的状态的value
4.6 广义策略迭代
策略迭代分为两步:策略评估使得价值函数和当前策略一致,而策略改进根据当前价值函数来改进策略。
4.7 动态规划的效率
对于n状态k动作的问题,虽然总策略数有$k^n$种,但是算法可以在多项式时间内完成。百万个状态对DP并不是压力。对于更大的状态空间,异步DP或许是更好的方法。


