
数据结构与STL容器
一、
1、线性表
线性表包括顺序存储结构(用一段连续地址存储)和链式存储结构(数据域+指针域)。顺序存储结构的代表是C/C++中的数组,其读时间复杂度为O(1),插入/删除为O(n),因为从插入/删除位置到最后一个元素都要向前/后移动一个位置。链式存储结构包括单链表(普通链表)、循环链表、双向链表等,单链表的读取为O(n),插入/删除O(n)——不清楚第i个元素指针位置时,但是已知时为O(1),代表为list容器。
2、栈
属于特殊的线性表,它一种先进后出的数据结构,代表为STL的stack。
3、队列
属于特殊的线性表,它一种先进先出的数据结构,代表为queue。
4、树
分为二叉树和多叉树(N叉树),map和set内部使用红黑树结构,在最坏的情况下查找、插入和删除仅消耗对数时间log(n)。
5、哈希表
STL中的unorder_map和unorder_set使用的就是hash table结构,查找、插入和删除消耗为常数级别O(1)。
二、
1、静态数组
静态数组就是大小固定不能扩展的数组,如C中普通数组、C++11中array。
2、动态数组
动态数组的空间大小在需要的时候可以进行再分配,其代表为vector。由于数组的特点,在位置0插入需要将整个数组后移一个位置来腾出空间,删除位置0的元素则需要将剩余元素前移一个位置,这两种最坏的情况为O(n)。所以vector只适合在末尾添加或删除元素,使用[]或迭代器随机访问是快速的。
deque可以可以看作是vector的增强版,它增加了在头部快速插入和删除元素。
3、链表
链表由一系列不必在内存中相连的结点组成,每个结点包含了结点元素和到后继结点的链。链表避免了插入和删除的线性开销,但随机访问效率很低。使用链表结构的代表是list容器,而且list是基于双向链表实现的。下图是普通链表与双向链表的示意图:

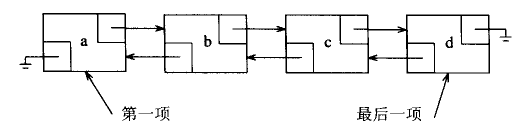
4、栈
栈的特点是后进先出,位于栈顶的元素是唯一可见的元素。栈可以使用链表来实现,通过在链表顶端插入元素来实现push,通过删除链表顶端元素来实现pop,top操作返回顶端元素。c++中栈数据结构的实现是容器适配器stack,stack其所关联的基础容器可以为vector、list、deque,默认为deque。

5、队列
队列的特点是先进先出,队列也可以使用链表来实现,enqueue(入队)是在链表的末端插入一个元素,dequeue(出队)是删除并返回链表开头的元素。c++中队列数据结构的实现是容器适配器queue,其所关联的基础容器可以为list或deque,默认为deque。
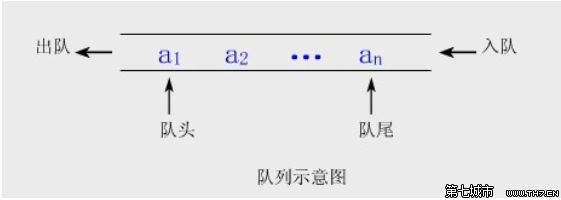
6、链表的创建和操作


typedef struct node { int iIndex; struct node* pNext; }Node, *NodePtr; //创建链表 NodePtr CreateList(unsigned iLen) { NodePtr pHeadNode = NULL, pLastNode = NULL; for (unsigned i = 0; i < iLen; i++) { NodePtr pNode = new Node; pNode->iIndex = i; if (pLastNode) pLastNode->pNext = pNode; else pHeadNode = pNode; pLastNode = pNode; } pLastNode->pNext = NULL; return pHeadNode; } //输出链表 void PrintList(NodePtr pHeadNode) { NodePtr pNode = pHeadNode; do { cout << pNode->iIndex << ", "; pNode = pNode->pNext; } while (pNode); cout << endl; } //链表排序:利用选择排序法思想 void SelectSortList(NodePtr pHeadNode) { NodePtr pNode = pHeadNode; while (pNode->pNext) { NodePtr pNodeMin = pNode; NodePtr pNodeNext = pNode->pNext; while (pNodeNext) { if (pNodeNext->iIndex < pNodeMin->iIndex) pNodeMin = pNodeNext; pNodeNext = pNodeNext->pNext; } if (pNodeMin != pNode) swap(&pNode->iIndex, &pNodeMin->iIndex); pNode = pNode->pNext; } } //合并两个有序链表为一个 NodePtr UnionList(NodePtr pHeadNode1, NodePtr pHeadNode2) { NodePtr pHeadNode = new Node;//新的链表添加一个头结点 NodePtr pNode1 = pHeadNode1, pNode2 = pHeadNode2, pNode = pHeadNode; while (pNode1 && pNode2) { if (pNode1->iIndex <= pNode2->iIndex) { pNode->pNext = pNode1; pNode = pNode->pNext; pNode1 = pNode1->pNext; } else { pNode->pNext = pNode2; pNode = pNode->pNext; pNode2 = pNode2->pNext; } } pNode->pNext = pNode1 ? pNode1 : pNode2;//插入剩余段 NodePtr pReturnNode = pHeadNode->pNext; delete pHeadNode;//删除新链表的头结点 return pReturnNode; } //链表逆序:定义三个节点指针分别指向前三个节点,第二个节点的pNext重新指向第一个节点,三个节点指针再往后移动,如此往复 NodePtr TurnList(NodePtr pHeadNode) { if (pHeadNode->pNext) { NodePtr pLastNode = pHeadNode; NodePtr pNode = pLastNode->pNext; NodePtr pNextNode = pNode->pNext; while (pNextNode) { pNode->pNext = pLastNode; pLastNode = pNode; pNode = pNextNode; pNextNode = pNextNode->pNext; } pNode->pNext = pLastNode; pHeadNode->pNext = NULL; return pNode; } else return pHeadNode; }
三、
1、顺序容器:
vector为向量容器,支持使用下标来快速随机访问(所以提供了[]和at()访问元素的方法,迭代器支持++、--、+=、-=算数操作),支持在尾部快速插入、删除元素(使用push_back()、pop_back()方法),不支持在头部或中间快速插入数据(虽然也提供了insert()方法但头部或中间来插入元素,但这样做会导致容器将插入位置之后的所有元素重新定位,或者导致重新分配整个内存)。
list为链表容器,支持在容器头、尾、内部快速插入、删除元素(insert()方法可以在任何地方之前插入元素,插入或删除不会重新分配内存),不支持快速随机访问(不提供[]或at()来访问元素,也不提供迭代器的+=、-=操作,仅提供迭代器的++、--操作,使用find()查找元素会很慢)。
虽然list的迭代器不提供+、-、+=、-=操作,但其实可以通过advance(list的advance() 函数底层实际上是通过重复执行 n 个 ++ 或者 --)、next/prev方法来实现这些操作,但是通过这些方法获得的list的迭代器进行distance操作的话会出错,所以如果想要对list进行advance、next等操作的话应该想一想使用的容器是不是改成vector更合适:
std::list<int> myList = {1, 2, 3, 4, 5}; auto it = myList.begin(); std::advance(it, 4); //advance移动当前迭代器 int n = *it; //5 auto it2 = std::next(myList.begin(), 1); //next/prev获得迭代器之后/之前的迭代器,不改变当前迭代器 n = *it2; //2 n = std::distance(myList.begin(), myList.end()); //5,distance获得迭代器之间的距离 n = std::distance(it, it2); //error
queue队列,适合队尾插入元素,队头删除元素的情况,它是容器适配器,其所关联的基础容器可以为list或deque,默认为deque。
deque为双端队列,它可以看作是queue的增强版,其支持在头部和尾部快速插入和删除元素。
priority_queue为优先级队列,允许设置元素的优先级,将新的元素放置在比它优先级低的元素前面,要求提供随机访问的功能,所以其所关联的基础容器可以为vector、deque,默认基础容器为vector
stack栈,适合后进先出的情况,它是容器适配器,其所关联的基础容器可以为vector、list、deque,默认为deque
2、关联容器
map、unordered_map、multimap为映射容器,支持通过键来快速查找和读取元素,其元素为键-值对的形式,键相当于元素的索引,值为元素所存储的数据。当使用下标[]来引用映射容器内元素的时候如果当前容器内没有该键则会自动创建该键值对。map元素是排序的,multimap支持同一个键多次出现。
set、multiset、unordered_set、bitset为集合容器,其元素仅包含一个键,有效的支持某个键是否存在的查询。set中元素是排序的,multiset支持同一个键多次出现。
bitset类似unordered_set,使用一个数组来保存数据,但因为bitset的元素只有数值类型(元素值只能是一位的0(可表示不存在或失败)或1(可表示存在或成功)),所以bitset不需要进行哈希运算,可以直接通过索引来获得元素。bitmap适合大量的数据的存储,并且我们需要判断某个元素是否存在于这个bitmap,或者我们需要不重复的保存大量数据。比如需要在40亿个不重复的unsigned int类型的随机整数中找出某个数是否存在其中,如果我们使用set存储这40亿个整数的话,这个set所占的内存就得十几G,我们可以这样,将这40亿个数保存存在文件里,而在保存每个数的时候,可以使用一个2^32-1大小(unsigned int最大表示的数)的bitmap来保存unsigned int所能表示所有数的状态, 比如第一个数是8,那么我们就将bitmap[7]设为1, 第二个数是10,将bitmap[9]设为1,第三个数是988,将bitmap[987]设为1...,而如果要判断8888这个数是否在这40亿个数的话,只需要判断bitmap[8887]是否为1就行,而这个bitmap有2^32-1个比特位,即只占用512M内存。
std::bitset<10> bitset1; // 长度为10, 每一位为0 std::bitset<8> bitset2(12); // 00001100 std::bitset<8> bitset3("1101"); //00001101 auto b = bitset1[0]; //0,不会进行下标检查,速度快,不安全 bitset1[1] = 1; size_t s = bitset1.size(); //10, biset的大小 size_t cnt = bitset2.count(); //2, bitset中1的个数 bool br = bitset2.test(2); // 第二位是否为1,会进行下标检查,速度慢,超出bitmap大小的话抛出异常 bitset2.set(); //全部位置为1 bitset2.set(2); //第二位置为1 bitset2.set(2, 0); //第二位置为0 bool ba = bitset3.any(); //是否存在1 bool bn = bitset3.none(); //是否全是0 bool bb = bitset3.all(); //是否全是1
3、vector等容器对于元素的要求是可复制和可赋值的,因为C++类都包含默认的复制构造方法(只是对类的数据成员进行简单的复制)和默认的operator=(只是对类的数据成员进行简单的赋值),所以vector的成员类型也可以是自定义类型的对象,对于包含char*这种指针成员的自定义类型,我们可能还需要重载其复制构造函数和operator=。map容器的key还需要支持<比较操作,所以如果把自定义类型作为map的key的话还需要重载operator<,或者指定map的第三个泛型类型(具体可以参考CSDN中文章:C++函数对象 中std::sort()的相关内容)。
std::find()中对于vector等容器中元素的要求是支持==,所以容器中元素如果是自定义类型的话还需要重载operator==。那么如果map中的key是自定义类型的话,自定义类型是不是除了要重载operator<外,还得重载operator==呢?答案是否定的,因为map可以根据operator<就能判断两个元素是否相等,比如 !c.less_comp()(x, y) && !c.less_comp()(y, x) 为true的话就表示x、y二者相等。
4、排序
如果我们需要容器是有序的话,可以使用std::sort()对vector进行排序,使用list.sort()对list进行排序(list不提供随机访问,所以应该使用其成员方法list::sort()来进行排序),map/set的话是自动排序的。
因为list和map不支持随机访问,所以在某些情况下只能使用vector。
使用vector然后对其进行sor()排序与使用自动排序的map/set那个更快呢?因为std::sort()默认使用快速排序,所以如果元素内存占用比较小的话,使用std::sort()会比使用基于红黑树的map/set(堆排序)要快,但是如果元素内存占用比较大的话,因为std::sort()需要大量地拷贝元素,而基于红黑树的map/set在排序的过程中则避免了元素的拷贝,所以这种情况下的话map/set排序的速度将比vector+std::sort()快。
基于以上原因,我们需要对vector进行排序的话,vector元素类型最好是指针类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号