字符集小结
最早的是ASCII字符集,它用一个字节的后7位来表示字母、数字、标点和其他常用字符,所以共有0-127个字符;后来又把第一位用上用来表示其他特殊的字符,这样就可以表示0-255个字符,这称为扩展ASCII(又称IOS-8859-1或latin1),latin1向下兼容ASCII。
后来由于其他国家使用的的文字个数远超过使用英语国家的这些256个字符,所以为了支持本国语言在计算机上显示,不同国家开发出了不同的字符集,比如中国大陆一开始使用GB2312,后来扩展成了GBK(完全兼容GB2312),后来又扩展成了GB18030(支持少数民族语言)。而香港、台湾地区使用BIG5,日本使用Shift_JIS字符集。
GBK编码使用1或2个字节来表示一个字符,比如使用1个字节来表示英文等ASCII字符,使用2个字节来表示一个汉字。对于双字节来说其第一个字节的取值范围是81–FE(129–254),因此如果用一个signed来保存其第一个字节的话,它会是一个负数。
ANSI表示各语言使用的标准化的字符集,比如英文的ANSI字符集是指ASCII,简体中文的ANSI字符集指GBK、日文是Shift_JIS。
而MBCS(multi-byte character set)是多字节字符集的意思,他也不是指某个具体的字符集,而是符合这种编码方式的字符集的统称。上面说过,许多非英文国家和地区发明并使用了不同的编码方式(GBK, BIG5, Shift_JIS等),这些本地字符编码就统称为MBCS。常见的有用一个字符来表示一个英文字符,用两个字节来表示一个本地字符的,如GBK,所以又延伸出了DBCS(double byte character set)也就是是双字节字符集这个统称。在VS中工程设置中可以看到有“使用多字节字符集”这个设置,对于我们来说这个就是使用GBK了。
由于不同国家使用不同的本地字符集,其互不兼容,所以后来就出现了UNICODE,它包含了全球不同国家都可以统一使用的字符集。UNICODE其实是一种统称,其具体实现方式又可以分为UTF-8、UTF-16、UTF-32等,而且一般情况下我们说unicode字符集的话默认指的是utf16。
UTF-8是一种变长字符编码,它使用1-6个字节来存储一个字符,比如使用1个字节来存储英文字符,使用2个字符来存储拉丁文,使用3个字符来存储大部分汉字。互联网上基本上都使用UTF-8字符集。
UTF-16在windows API中,UTF-16被仅以2个字节来存储,因为这两个字节可以表示大部分的字符,比如sizeof(wchar_t)的大小为2,而在linux上的UTF-16是以4个字节存储的,一个wchar_t占4个字节。不同系统对于UTF-16的字节存储顺序会有所不同,Mac会使用大端序(Big-Endian)而Windows和Linux使用小端序(Little-Endian),比如说在Windows下以UTF-16编码保存一个字符“乙”,在Mac OS环境下打开会显示成“奎”。
如果没有特别指出的话,我们说使用UNICODE字符集就是指使用UTF-16字符集,如VS设置中使用UNICODE字符集的话即表示使用UTF-16字符编码版本的方法,使用多字节字符集的话对于我们就是使用GBK。
在字符串中的"\u十六进制数"表示对应的UNICODE编码的字符,如汉字"一"的UNICODE编码是0x4E00,"\u4E00个人"就相当于是"一个人"。
计算机是怎么区分ASCII码和汉字的?如果使用的是UNICODE编码即UTF16编码的话因为所有字符都占用两个字节(Linux下为4个字节),所以通过字符的编码值即可分辨。如果是UTF-8编码的话,汉字字符的每个字节的第一位都是1,即为负数。
字符集:由一些指定的字符的所组成集合,如ASCII字符集由128个字符组成,其它的字符集还有GBK、UNICODE等。
字符编码:字符集中字符的编码,如ASCII字符集中,a的字符编码是97。对于相同的字符,不同的字符集使用的字符编码不尽相同。
经测试,对于VS下代码中的字符串常量,使用“文件-高级文件保存选项”将代码文件修改成UTF-8或GBK的话,字符串常量都是GBK编码的,而如果在字符串常量前添加u8的话字符串才是UTF-8编码的(不论设置了文件编码为GBK或UTF-8)。而对于Qt Creator下,使用"工具-选项-文件编码"改变文件编码为UTF8的话字符串常量就是UTF-8格式的,代码文件编码为GBK的话则字符串常量是GBK编码,如果在文件编码为GBK的情况下给字符串常量添加了u8前缀,这个字符串也是GBK编码的。
1、C中字符串、C++的string
下面为在VS下的命令行程序中的测试代码,由于std::string内部直接使用传入的字符串而不会进行任何编码转换,而中文操作系统默认使用的是GBK编码,所以对于GBK格式的字符串或string可以正常显示,对于UTF-8格式的字符串或string中文显示乱码。UNICODE格式的字符串需要使用对应的宽字符版本输出方法wprintf()或wstring、wcout来进行输出(我猜其也也是将unicode转换为GBK后再进行显示的):


int main() { //给printf()传入与系统字符编码相同的字符串,则中文可以正常显示 char* p = "abc测试"; //vs下代码文件使用的是gbk编码(与系统字符编码相同),其与项目属性设置的字符集无关, 所以这里的字符串是GBK格式 printf(p); //显示正常 //给printf()传入与系统字符编码不同的字符串,则中文不能正常显示 //char ary[] = { 97, 98, 99, -26, -75, -117, -24, -81, -107, 0 }; //utf-8编码格式的"abc测试" char* ary = u8"abc测试"; printf(ary); //中文会乱码 setlocale(LC_ALL, ""); //输出宽字符需要设置区域 wchar_t* wp = L"abc中文\n"; //使用UNICODE格式字符串 wprintf(wp); //显示正常 //给string传入与系统字符编码相同的字符串,则中文可以正常显示 string str("abc测试"); cout << str << endl; //正常显示 //给string传入与系统字符编码不同的字符串,则中文不能正常显示 //char ary2[] = { 97, 98, 99, -26, -75, -117, -24, -81, -107, 0 }; //utf-8编码格式的"abc测试" char* ary2 = u8"abc测试"; string str2(ary2); cout << str2 << endl; //中文显示乱码 wcout.imbue(std::locale("chs")); wstring wstr(L"abc中文"); //使用UNICODE格式字符串 wcout << wstr << endl; //正常显示 return 0; }
std::string str1 = "abc测试"; std::string str2 = u8"abc测试"; bool b = str1 == str2; //false
VS下可以通过“文件-高级保存选项”来查看和设置当前代码文件使用的字符编码(中文系统默认是GB2312)。
windows的CMD命令行默认使用的是系统编码GBK,可以在其标题栏右键属性查看,或者输入CHCP命令会输出936(表示GBK),可以输入CHCP 65001来设置使用UTF-8编码。
对于unicode宽字符的输出的话还需要使用setlocale()来设置区域,其第一个参数为地域设置的影响范围,第二个参数为设置的地域,如果想要获取当前设置的区域的话将第二个参数设置为NULL,setlocale()返回的就是当前设置的地域名称:
第一个参数:

第二个参数:

C++ 设置locale区域的方法有:
std::locale::global(std::locale("")); //设置全局locale
wcout.imbue(std::locale("chs")); //单独为wcout设置一个locale
2、MFC中的CString
对于MFC下的CString,当传入char*进行初始化的时候char*应是与系统编码相同的字符串,否则中文会出现乱码,即QString认为传入的char*字符串是与系统编码相同的:
//CDialogEx::OnPaint(); CPaintDC dc(this); RECT re = { 0, 0, 100, 20 }; /******项目属性字符集使用GBK的情况下******/ CString str("abc测试"); //VS下代码文件使用的是gbk编码(与系统字符编码相同),与项目属性设置的字符集无关,所以这里的字符串是GBK格式 char* p = str.GetBuffer(); //GetBuffer()返回类型为LPSTR auto len = str.GetLength(); // 7 dc.DrawText(str, &re, DT_CENTER); //中文显示正常 char ary[] = { 97, 98, 99, -26, -75, -117, -24, -81, -107, 0 }; //utf-8编码格式的"abc测试" CString str(ary); char* p = str.GetBuffer(); //GetBuffer()返回类型为LPSTR auto len = str.GetLength(); // 9 dc.DrawText(str, &re, DT_CENTER); //中文显示乱码 CString str(L"abc测试"); //使用UNICODE格式字符串 char* p = str.GetBuffer(); //GetBuffer()返回类型为LPSTR auto len = str.GetLength(); // 7 dc.DrawText(str, &re, DT_CENTER); //中文显示正常 /******项目属性字符集使UNICODE的情况下******/ CString str("abc测试"); //传入的是GBK字符串,这里会将GBK转换为UNICODE wchar_t* p = str.GetBuffer(); //GetBuffer()返回类型为LPWSTR auto len = str.GetLength(); // 5 dc.DrawText(str, &re, DT_CENTER); //中文显示正常 char ary[] = { 97, 98, 99, -26, -75, -117, -24, -81, -107, 0 }; //utf-8编码格式的"abc测试" CString str(ary); //传入的不是GBK字符串,但CString会认为是GBK,按照GBK转UNICODE,所以中文会乱码 wchar_t* p = str.GetBuffer(); //GetBuffer()返回类型为LWPSTR auto len = str.GetLength(); // 6 dc.DrawText(str, &re, DT_CENTER); //中文显示乱码 CString str(L"abc测试"); wchar_t* p = str.GetBuffer(); //GetBuffer()返回类型为LPWSTR auto len = str.GetLength(); // 5 dc.DrawText(str, &re, DT_CENTER); //中文显示正常
CString内部使用项目属性中设置的字符集(多字节字符集或UNICODE)来保存数据:
CString str1("abc测试"); //gbk CString str2(L"abc测试"); bool b = str1 == str2; //true
3、Qt中的QString
QString内部使用QChar类型(unicode编码),使用字符串或字节数组初始化QString的话,QString会根据QTextCodec::setCodecForCStrings设置的字符集来转化为QChar:
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GBK")); char p[] = {97, 98, 99, -78, -30, -54, -44, 0}; //GBK编码的"abc测试" QString str(p); //将GBK编码转换为UNICODE QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8")); char p[] = {97, 98, 99, -26, -75, -117, -24, -81, -107, 0}; //UTF-8编码的"abc测试" QString str(p); //将UTF-8编码转换为UNICODE QTextCodec::setCodecForCStrings(QTextCodec::codecForLocale()); QByteArray ary = process.readAll(); //process为QProcess类型 QString(ary); //将当前区域使用的编码转换为UNICODE
推荐使用String的fromXXX() 静态方法:
QString str = QString::fromStdWString(L"abc测试"); char ary[] = {97, 98, 99, -26, -75, -117, -24, -81, -107, 0}; //UTF-8编码的"abc测试" QString s = QString::fromUtf8(ary);
Qt Creator中可以在“工具-选项-文本编辑器-行为”里设置代码文件使用的字符编码。
4、juce中的String
juce中的String内部使用utf-8编码格式,是否有可以相关设置的地方?
5、java的String
java中的String内部使用char类型(unicode编码),当我们使用byte[]初始化String而不指定使用的字符编码的时候,byte[]里的字符串使用的编码应该与平台默认字符编码相同,在Eclipse下平台默认字符编码与Window-General-Workspace-Text file encoding设置的代码文件字符编码相同:
byte[] ary = {97, 98, 99, -26, -75, -117, -24, -81, -107, 0}; //UTF8格式的"abc测试" String str = new String(ary); //使用当前平台默认字符编码将ary转为unicode System.out.println(str); //当前平台默认字符编码应该也为utf-8,否则中文乱码 byte[] ary = {97, 98, 99, -78, -30, -54, -44, 0}; //GBK格式的"abc测试" String str = new String(ary); //使用当前平台默认字符编码将ary转为unicode System.out.println(str); //当前平台默认字符编码应该也为gbk,否则中文乱码
推荐使用带指定字符编码的构造方法来初始化String:
byte[] aryU = {97, 98, 99, -26, -75, -117, -24, -81, -107, 0}; //UTF-8编码的"abc测试" byte[] aryG = {97, 98, 99, -78, -30, -54, -44}; try { String strU = new String(aryU, "UTF-8"); System.out.println(strU); //显示正常 String strG = new String(aryG, "GBK"); System.out.println(strG); //显示正常 }catch(java.io.IOException ex){}
6、URL中的汉字编码
以下内容转载自互联网:
URL中如果有汉字的话必须进行编码转换,但是编码的方法RFC并没有进行规定。
①、网址路径中包含汉字
如下所示,在IE的地址栏中输入汉字的话,经抓包分析对应的http请求中的汉字“春节”被编码为了"%E6%98%A5%E8%8A%82",而"春"、"节"的UTF-8编码就是0xE698A5和0XE88A82,也就是IE将地址栏中汉字的编码方式为"% + 对应UTF-8编码的一个字节值"。

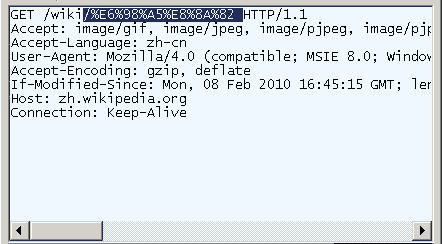
下面提供一个将带汉字的URL根据以上规则转换的方法:
std::string getHexString(unsigned char byte) { std::string strHex; unsigned char ary[2] = { byte >> 4/*byte的高四位*/, byte % 16/*byte的低四位*/ }; for (int i = 0; i < 2; ++i) { strHex += ary[i] > 9 ? ary[i] + 55 : ary[i] + 48; } return strHex; } std::string getURLWideCharHexString(const std::string& str) { std::string strHexValue; for (int i = 0; i < str.size(); ++i) { if (str[i] > 0) { strHexValue += str[i]; } else { strHexValue += "%"; strHexValue += getHexString(str[i]); } } return strHexValue; } int main() { std::string s = getURLWideCharHexString(u8"123春节abc"); // "123%E6%98%A5%E8%8A%82abc" return 0; }
②、查询字符串包含汉字
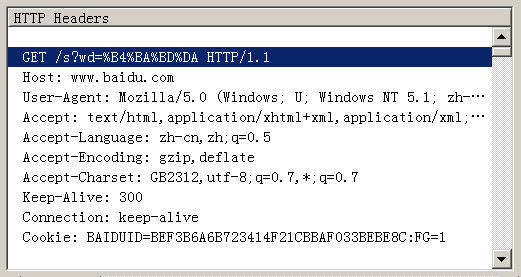
并非所有的URL中汉字都是像上面网址路径中那样进行编码转换的,比如在IE中输入网址“http://www.baidu.com/s?wd=春节 ”。注意,这里的“春节”这两个字此时属于查询字符串,不属于网址路径,不要与情况1混淆。查看HTTP请求的头信息,会发现IE将“春节”转化成了一个乱码,切换到十六进制方式可以看到“春节”被转换成了0xB4BA 0xBDDA,而这正是"春节"的GBK编码值,所以查询字符串中的汉字在IE中是以GBK编码格式保存的。

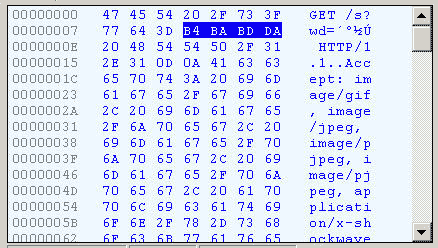
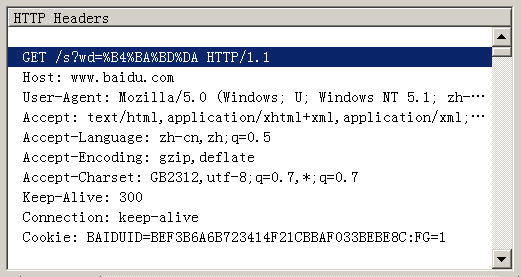
但是如果是Firefox中的查询字符串的话HTTP Head是“wd=%B4%BA%BD%DA”,也就是火狐中查询字符串中的汉字编码方法与上面网址路径中包含汉字的编码方法类似,但使用的是GBK。
③、Get/Post方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。根据台湾中兴大学吕瑞麟老师的试验 ,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。 <meta http-equiv="Content-Type" content="text/html;charset=xxxx">,如果这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
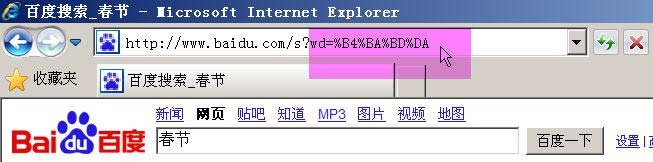
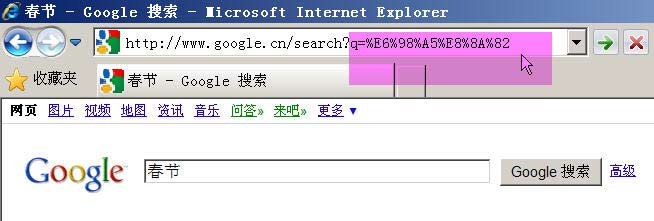
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词“春节”,生成的查询字符串是不一样的。百度生成的是%B4%BA%BD%DA,这是GB2312编码,Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。
④、