


MySQL Cluster与Replication
1、综述
MySql架构可以分为两种形式,一个是MySQL Cluster,一个是MySQL Replication,Cluster即集群模式,Replication即主从复制(读写分离)模式。
MySQL Cluster基于NDB存储引擎,其优点是高可用(即节点出现故障时自动切换到备用节点)和高可伸缩性(可以添加或删除节点以提高系统扩展性),并且实时性能高(数据存储在内存中,并可通过多个节点来分布查询),缺点是配置复杂,而且数据需要存储在内存中,需要许可费用(MySQL Cluster是商业产品),所以其成本较高。
MySQL Replication基于InnoDB存储引擎,它是一种简单的主服务器和多个从服务器的架构,可以在主服务器上写入数据,并在从服务器上进行读取操作,通过添加更多的从服务器来提高系统的扩展性。Replication在故障切换方面比较弱,并不能提供完全的自动故障转移机制,如果主服务器负载过大,可能会影响读写性能,而且Slaves的数据同步的延迟也可能比较大。
2、主从复制
MySQL主从复制原理:当Master主库进行写入命令时,会按将其写入到binlog中,然后由Binlog Dump 线程将变化内容推送给所有slave节点,slave节点收到推送后会根据内容对数据库做对应的修改(为了减小延迟,从节点会通过 I/O 线程将主服务器的二进制日志文件中的写操作复制到一个叫 Relay Log 的中继日志文件,然后通过另一个 SQL 线程将 Relay Log 中继日志文件中的写操作依次在本地执行)。当salve从库连接到master主库后会向其发送当前收到的修改内容的偏移量,master主库收到后会对比自己的binlog修改偏移量,如果不同的话会向salve从库进行主从复制。默认是基于语句的复制,即把命令在从服务器上执行一遍,无法精确执行语句复制的时候会自动选择基于行的复制,即把改变的内容复制过去。
可以通过mysql配置文件来对MySQL服务进行Master和Slave配置,然后在代码中只对master进行写入数据,slave负责读取数据。在SpringBoot项目中实现读写分离模式的话可以参考这两篇文章:MySQL主从复制读写分离,看这篇就够了,SpringBoot 项目优雅实现读写分离。
3、链式复制和双向复制
除了一个Master多个Slave的常规复制架构外,还有链式复制和双向复制,因为Slave可以同时作为Master,从而形成链式复制和双向复制。
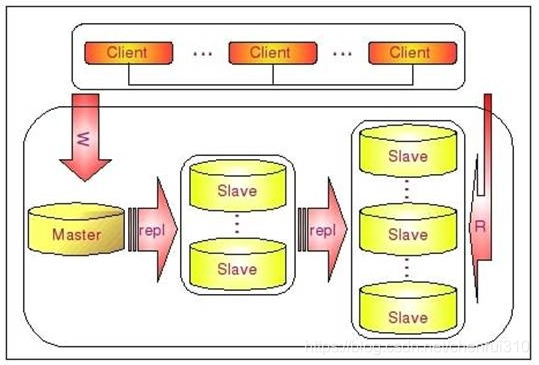
当读压力特别的大,一个Master可能需要上10台甚至更多的Slave才能够支撑住读的压力,这时候写入的话Master就会比较吃力了,因为仅仅连上来的SlaveIO线程就比较多了,容易造成复制延时,这个时候就可以使用链式复制。如下所示,先通过少数几台Slave从Master进行复制(第一级Slave集群),然后其他的Slave再从第一级Slave集群来进行复制(第二级Slave集群)。这样可以解决Master端因为附属Slave太多而成为瓶颈的风险。
在Master端需要进行一些特别的维护操作的时候,可能需要停MySQL的服务,为了尽可能减少应用系统写服务的停机时间,可以使用双向复制架构:两个MySQL服务互相将对方作为自己的Master,即将自己配置为对方的Slave,这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。因为任何一端都记录了自己当前复制到对方的什么位置了,当服务起来之后,就会自动开始从之前的位置开始复制,而不需要人为去进行任何干预,大大节省了维护成本。双向复制架构和一些第三方的HA(High Available高可用)管理软件结合,可以在我们当前正在使用的Master出现异常无法提供服务之后,非常迅速的自动切换另外一端来提供相应的服务,并且完全不需要人工干预。官方文档中并不提倡使用双向复制架构,因为容易产生冲突。

4、高可用方案

MySQL的整体架构可以如上所示,对于常规主从复制模式的话,可以使用drbd来保证两个master库(一个主Master,一个备份Master)的数据一致性,利用heartbeat来完成其中一台mater发生故障后的自动切换,如下所示。如果是双向复制模式,各自作为对方的从机接受对方发来的数据,可以自动做到数据的同步备份,然后可以使用MMM(MySQL Master-Master Replication Manager)来保证其中一台服务器故障,自动切换到另外的一个master上。其它的HA组件还有mha、orchestrator、replication-manager等,也可以使用server内置插件如MGR、PXC、MariaDB Galera Cluster等。

5、MyCat
也可以使用MyCat来实现MySQL集群,MyCat相当于是一个分布式数据库系统,其实现了MySQL协议,可以将其看做一个数据库代理,其核心功能是分表分库,即将一个大表分割成N个小表,存储在后端的一个或多个MySQL服务中。MyCat后端不仅可以用MySQL原生协议与MySQL服务通信,也可以使用JDBC协议与其它主流数据库服务通信,所以其后端也可以支持SQL Server、Oracle、DB2等。而在前端用户看来,无论使用哪种存储服务,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据操作。
6、MySQL++
C++中可以使用MySQL++这个库来简化MySQL操作,它可以将查询结果转存到STL容器中——顺序的或关联的,同时支持连接池。使用示例如下:
mysqlpp::Connection conn(false); conn.connect(DATEBASE_NAME, DATEBASE_IP, DATEBASE_USERNAME, DATEBASE_PWD); mysqlpp::Query query = conn.query(); query << "select * from cc;"; mysqlpp::StoreQueryResult ares = query.store(); for (size_t i = 0; i < ares.num_rows(); i++) { cout << "id: " << ares[i]["id"] << "," << "Name: " << ares[i]["name"] << "," << "Status: " << ares[i]["status"] << endl; }
mysqlpp::Query query = conn.query("SELECT * FROM student"); if (mysqlpp::StoreQueryResult res = query.store()) { mysqlpp::StoreQueryResult::const_iterator it; for (it = res.begin(); it != res.end(); ++it) { mysqlpp::Row row = *it; cout << row[0] << ',' << row[1] << ',' << row[2] << endl; } }
vector<mysqlpp::Row> v; query << "SELECT * FROM stock"; query.storein(v); for (vector<mysqlpp::Row>::iterator it = v.begin(); it != v.end(); ++it) { cout << "Price: " << it->at("price") << endl; }
vector<Stock> v; query << "SELECT * FROM stock"; query.storein(v); for (vector<Stock>::iterator it = v.begin(); it != v.end(); ++it) { cout << "Price: " << it->price << endl; }
使用连接池的话,可以从mysqlpp::ConnectionPool继承出一个连接池类,然后从这个连接池对象中获得一个连接来直接使用,具体可以参考MySQL++ Documentation中User Manual中的Using MySQL++ in a Multithreaded Program部分。
关于MySQL++的安装可以参考Linux环境下Mysql++安装及操作深入详解、C++ 操作mySQL、mysql++安装、使用详解。

