结对编程-第一阶段
2021年软工 结对项目第一阶段总结
教学班级:2021春季软件工程(罗杰 任健)
结对人员(学号后四位): 3584 ,3622
一、对结对编程的感受
在个人阅读作业二中,我曾经对结对编程的效率提出过疑问,当时我认为实现代码是一个亟需沉思的过程,随时复审与交流会打断这一过程,造成编码效率的下降。但经过一整个单元结对作业的设计与编写,我初步体会到了结对编程的主要优势所在,即随时复审会使得低级错误的出现率大大降低。在较长时间的编码后,编码者往往会犯一些低级错误,如将 absolutePath 误写为 path ,将 && 误写为 || 等,这样的错误往往在测试前难以发现,且经过漫长的 debug 后发现低级错误也会极大增加挫败感。而两人共同面对同一份代码时同时犯低级错误的概率将远低于单人,节省了大量的测试时间。
同时我认为在结对编程过程中需要注意以下方面:
- 选择良好的环境。我认为首先便是需要一块(或多块)足够大的显示屏,使得复审者在看代码时有良好的体验,当然也可以使用一些类似
Code With Me的插件进行线上结对编程。 - 在具体编码前统一代码风格。虽然平时讨论大括号换不换行多是在玩梗,但当两人共同完成同一份代码时,统一的代码风格显得尤为重要,这里的代码风格不限于表面上的大括号是否换行等问题,还包括对数组遍历方式、
try catch结构的使用方式、单元测试的编写方式等更深层的风格的统一。 - 复审和交流的时间。虽然结对编程鼓励随时处于代码复审状态,但我认为这并不意味着复审者要在编写者每一个小语句写完后进行疑问或错误的提出,而是应该在一个方法(至少是方法的一个较大阶段)写完后再进行交流。这样做不仅有出于留给编写者更多沉思时间的考虑,也能减少很多由于二人编码习惯的不同而导致的在编码过程中出现的无效交流。

二、项目设计与实现思路
2.1 初步设计
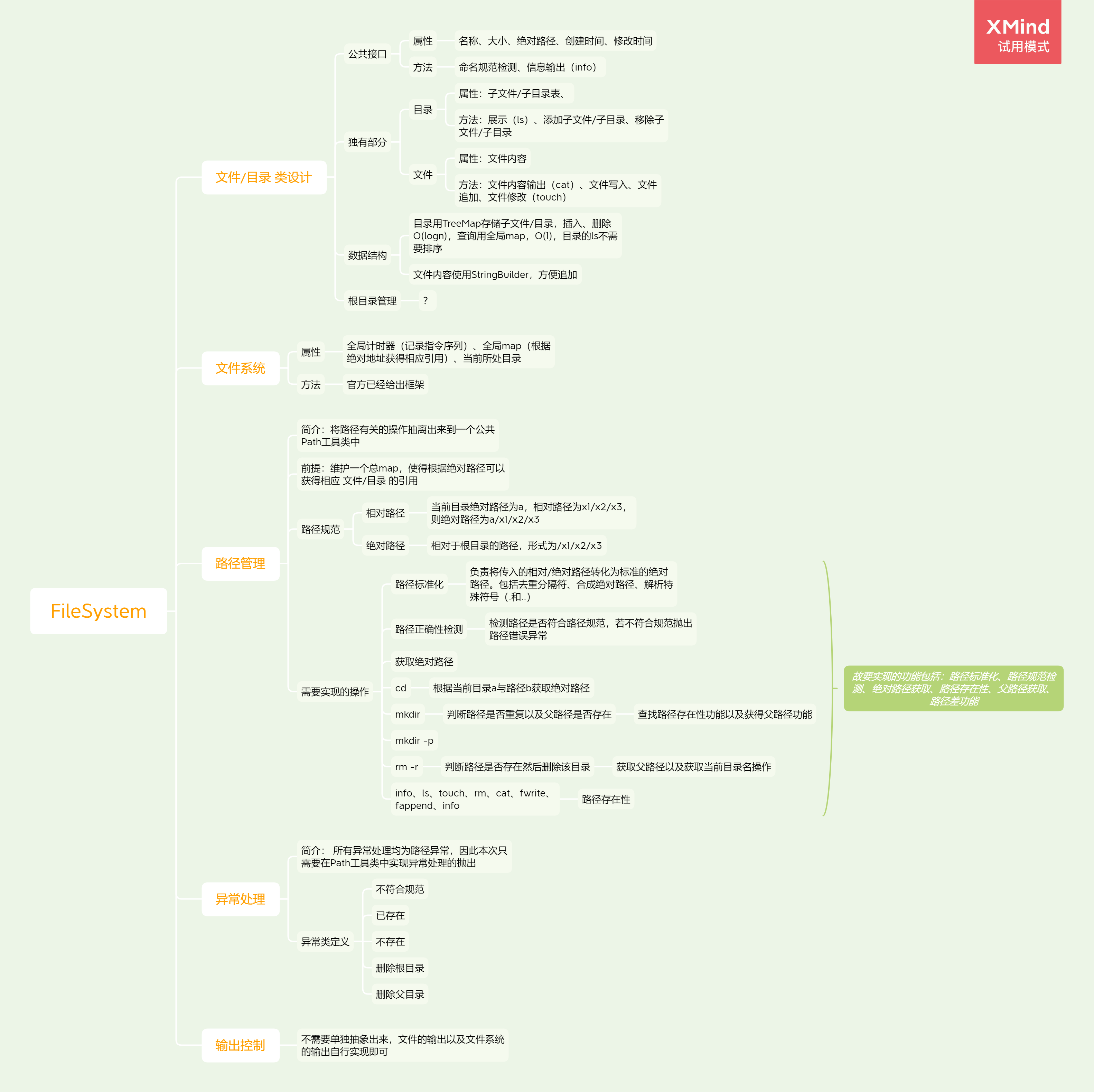
整体设计上,我们定义了目录 Directory 和文件 File 两类实体,并在此基础上建立了基于绝对路径的全局索引和每个目录自己维护的子目录/文件树状结构。当输入包给出任意路径(无论是绝对路径还是相对路径)时,都会由路径解析器进行解析,形成一个最短的绝对路径,根据此绝对路径便可在全局索引中查找目标目录或文件,并进行相关操作。
因此整个项目的设计主要分为以下这几个部分:数据结构设计、路径管理、文件系统操作部分与异常处理,接下来我们依次进行介绍。
2.2 数据结构设计
整个文件系统采用树结构的设计,即每一个结点除了保存自己的信息外,还应当保存下一层所有结点的索引。关于索引数据结构的选择,我们采用了TreeMap这个数据结构,建立了文件名到结点的索引。由于TreeMap的底层实现原理为红黑树,因此我们只需要$O(logn)$的时间复杂度实现跨一层的文件的查找插入与删除,并且它可以特定的针对list这个需求,不需要对子目录或者文件排序便可以输出某一目录的内容。
具体文件/目录类的设计如下:
public class Entity {
protected String name;
protected int size;
protected String absolutePath;
protected int creatTime;
protected int modifyTime;
...
}
public class Directory extends Entity {
TreeMap<String/**name**/, Entity> subEntities = new TreeMap<String, Entity>();
...
}
public class File extends Entity {
private StringBuilder content = new StringBuilder();
...
}
不过考虑到TreeMap在找子节点的时候需要用$logn$的时间复杂度,因此我们还在文件系统中建立了一个全局的,map索引,它可以根据标准化的绝对路径直接获取到对应的结点,不过代价就是需要用较大的空间存储绝对路径,相当于是在空间与时间两者的权衡,不过由于没有做具体的测试,现在还不知道哪种效果比较好。但是引入了全局的map后,我们可以把原本树中结点的移动操作交给路径解析器去解析,因此可以简化文件系统的操作部分的实现。
2.3 路径管理
我们实现了一个名为Path的工具类,让它来处理所有与路径有关的操作,包括但不限于路径命名规范检测、路径标准化处理、路径存在性检测、父路径获取等功能。
“路径命名规范检测”功能,它实现了对路径中文件或目录名的非法字符以及最大长度限制的检测,在检查到非法命名时会抛出InvalidPathException。
“路径标准化”功能,它首先判断所给路径是否为绝对路径,若为相对路径则会以当前文件系统所处的目录的绝对路径为前缀进行合并,从而获得未标准化的绝对路径;然后对该路径进行重复分隔符/的合并,并去除非根目录路径的结尾/符(确保路径最短);最后将名称为..与.的部分进行转义,从而获得了一条不含..与.的最短标准路径。
然后是”路径正确性检测“功能,它会确保所得到的标准路径的所有上层目录均存在,并且确保所有的上层目录均为目录,不然抛出路径错误异常。
此外,该模块还封装了一些简单的小工具,比如获得某一路径的父路径、获取某一路径对应文件的名称,获取路径的前后缀,检验路径存在性等功能。
3.3 异常处理
我们将所可能产生的异常划分为了以下几类:
ExistException:文件或目录已存在异常
NotExistException:文件或目录不存在异常
InvalidPathException:路径规范错误异常
DeleteRootException:删除根目录异常
DeleteSelfAndParentException:删除自己以及父目录异常
其实应当可以有更加细致的划分,比如按照每一个操作的异常进行分类
3.4 文件系统操作部分
首先我们在文件系统中存放一个全局计数器,用来指示当前指令是第几条,以及当前目录指示器和根目录指示器,用来协助文件系统操作的实现。
然后是文件系统操作的具体实现。对于普通的文件以及目录的增删改查操作,由于路径管理器已经做到了路径检测并返回标准绝对路径,并通过全局map可以直接获得到对应路径的结点,因此再做后续的操作就比较简单。而对于目录大小的更新机制,我们考虑了查询时更新以及修改时更新两种方法,经比较后发现前者需要通过向下搜索一个网状结构的方法来实现目录大小的更新,而后者仅仅需要沿着父目录进行线性更新,因此这里我们选择修改时更新机制。
三、PSP表格记录
| PSP2.1 | 阶段 | ||
|---|---|---|---|
| Planning | 计划 | 预估耗时(分钟) | 实际耗时(分钟) |
| Estimate | 估计完成所需时间 | 5 | 10 |
| Development | 开发 | ||
| Analysis | 需求分析 | 10 | 20 |
| Design Spec | 设计文档 | 60 | 90 |
| Design Review | 设计复审 | 30 | 20 |
| Coding Standard | 代码规范 | 30 | 5 |
| Design | 具体设计 | 20 | 40 |
| Coding | 具体编码 | 300 | 360 |
| Code Review | 代码复审 | 0 | 0 |
| Test | 测试 | 180 | 300 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 0 | 0 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan |
总结与提出改进计划 | 60 | 120 |
| 合计 | 690 | 975 |
注:代码复审与具体编码同时进行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号