oo第三单元总结——jml
P1 JML语言理论基础
JML详细基础教程:https://blog.csdn.net/weixin_41412192/article/details/89527142
-
原子表达式
\result:表示非void类型方法返回结果\old(expr):表示相应方法执行前expr的取值,换言之,直接引用expr均表示方法执行完后的值\not_assigned:变量在方法执行过程中是否被赋值\not_modified:类似于\not_assigned\notnullelemente(container):表示container对象内部不许有null元素 -
量化表达式
\forall:(\forall int i,j变量定义; 0 <= i && i < j && j < 10取值范围; a[i] < a[j]变量条件)\exists:(\exists int i变量定义; 0 <= i && i < 10取值范围; a[i] < 0变量条件)\sum:(\sum int i变量定义; 0 <= i && i < 5取值范围; i求和数)\product:(\product int i变量定义; 0 < i && i < 5取值范围; i连乘数)\max:(\max int i变量定义; 0 <= i && i < 5取值范围; i要比较并返回的表达式)\min:(\min int i变量定义; 0 <= i && i < 5取值范围; i要比较并返回的表达式)\num_of:(\num_of int x变量定义; 0<x && x<=20取值范围;x%2==0条件) -
操作符
<::E1<:E2,E1是E2子类型<==>:b_expr1<==>b_expr2 ,表示b_expr1==b_expr2<=!=>: b_expr1<=!=>b_expr2 ,表示b_expr1!=b_expr2==>:b_expr1==>b_expr2,表示b_expr1->b_expr2\nothing:空集\everthing:表示当前作用域能够访问到的所有变量 -
方法规格
requires P:调用者确保表达式P为真ensures P:方法实现者确保方法执行后P为真assignable (P1, P2,...):方法执行过程中P1,P2...不能被赋值modifiable(P1,P2...):方法执行过程中P1,P2...可被修改public /\*@ pure @\*/ int getStatus():表示getStatus为纯粹访问性方法public normal_behavior:表示接下来规格描述为方法的正常功能public exceptional_behavior:表示接下来规格描述为异常功能signals:signals (***Exception e异常类型) b_expr异常抛出条件; -
类型规格
invariant P:任意可见状态(可被理解为方法执行前与方法执行后)满足Pconstraint P:任意可见状态变化满足P
P2 应用工具链
openjml+solver
openjml的用途是用来检验所书写的规格是否满足规范,solver工具用来检验所书写的代码是否满足jml规格的要求,即正确性检验,因此使用好这两个工具可以完美的解决自身的程序检验问题。
但是由于本人能力有限,至今没有用好这两个工具,只好配一张运行的结果如下:
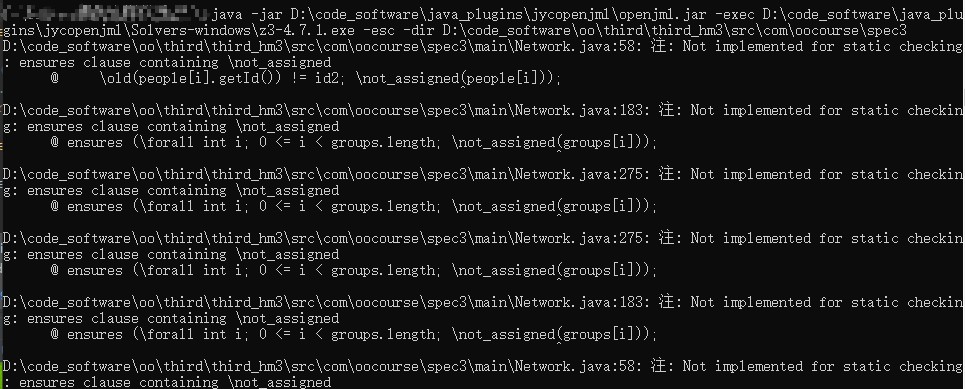
运行结果除了上面图片的not implememted for static checking外,后面还跟了大量的警告信息。
jmluniting
安装后jmluniiting后,文件目录如下:

test文件夹下:

其中Person做了些修改
输入下述命令:
java -jar jmlunitng.jar test/Group.java
javac -cp jmlunitng.jar test/*.java
java -jar openjml.jar -rac test/Group.java test/Person.java
java -cp jmlunitng.jar test.Group_JML_Test
然后结果如下:
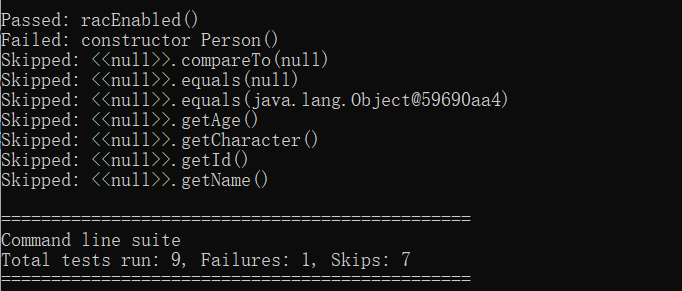
对于某些对象,只会添null进去,似乎不是特别好用。
P3 架构设计
三次作业的架构官方均已给定,基本上是NetWork类对其内部所存的person类和group类进行操作,后两者为前者提供相应的信息以及一定的方法;group对其内部所存的person类进行操作。
因此这次作业的重点放在了对某些特定函数的实现及优化上。
-
采用ArraryList和HashMap双重储存
用HashMap进行储存以简化部分需要遍历查找的操作。如:
Person类:使用
HashMap<Integer/*PersonID*/, Person> acquaintance使得能够通过PersonID直接获取相应Person对象,从而简化了isLinked(判断对方与自己是否有联系)、queryValue(查询目标与自己关系的权重值)。Group类:使用
HashMap<Integer/*PersonID*/, Person> people通过PersonID直接获取Person对象。简化hasPerson(判断当前组是否有某人)。Network类还有许多,就不一一例举了。
用ArrayList来进行遍历操作,从而弥补了HashMap遍历操作性能的不足。如:
MyNetwork类:使用
ArrayList<Group> groupArray来进行queryNameRank(判断名字大小顺序)、queryAgeSum(判断年龄位于[l,r]之间的人个数)等。 -
采用缓存设计,简化查询操作
Group类:
relationsum(用于getRelationSum):向组内添加新人时,查找其与组内其他人有联系的个数relationsum,则结果是
relationsum += 2 * temprelationsum + 1;添加新的关系时,relationsum加2即可。从组内删人同理valuesum(用于getValueSum):基本上同relationsum,不过添加权重而已。
conflictSum(用于getConflictSum):组内添加新人时,异或新人的数据,删人同理(由数学保证)
等等
MyNetwork类:
HashMap<Integer/*PersonID*/, Integer/*SetID*/> quickFind,用于isCircle查询两人是否联通的并查集算法,以及简化queryblocksum操作。Network添加新人时,将其设置为单独的一组,添加新联系时,遍历所有人,将Set值为后者的更改为前者(相当于把另一个Set的人全部加入要合并的Set)。这样好处是查询时不需要做搜索操作。之后有了解了一个简化移动的版本,可以将所有的集合设一个根节点,合并时只用移动根节点即可,这样简化了移动,但也加重了查询负担。 -
queryMinPath该函数用于求最短路径,本人用的是无修的dijstra算法,所以性能上会有部分损失。这里了解到了别人使用的是堆优化后的dijstra算法,即在更新最短距离的时候,将这些距离加入小顶堆结构,这样便能用小顶堆的插入的O(logn)复杂度代替之后选出最短距离的O(n)复杂度
-
queryStrongLinked
用于求一点到另一点是否存在不相交(除了首尾)的两条路。本人用的是dfs*dfs算法,所以炸了。后面才知道可以先用dfs找出一条路,然后用删除割点的方法,将路上的点以此删除,判断两个点是否联通,这样可以大大简化复杂度。
P4 作业bug
第一次作业没有bug,便得意忘形,后面两次作业都炸了。
第二次作业由于未自己检测isCircle算法的正确性,再加上相信弱侧的强度,结果没想到是温水煮青蛙,强侧直接将自己炸了个遍。事后课下才知道自己isCircle基本上一测就炸。于是第二次作业败在了正确性检验上。
第三次作业开始有所提防,但是此时本单元的重点早就不在正确性上了(正确性是基础),纵使自己写完代码后认真的再对照了一边jml,并且与某个好友的代码比对了一番,确认了正确性后,但是却忽略了性能方面,居然不曾想过自己的O(n^2)复杂度的qsl是一颗定时炸弹,于是强侧炸了几个点。而且这次不小心将课程组的代码交了上去,可以说是祸不单行,不过也无所谓了,只不过从差变道更差了而已。
现在稍微思考一下,觉得这两周在oo上的时间确实很短,第三次作业甚至是最后一天才写(主要还是os太难了主要还是自己效率太低了)。从后应该提高对oo的重视程度,在其上应当花费更多的时间。并且应当把任务重心放在正确性和性能的测试上。
P5 心得和体会
我现在对jml的理解就是,他将我们之前对整个程序功能实现的视野拉到了对某个单元块的实现上,以便我们能够更加重视单元块的正确程度。jml使得我们在编写某个单元块时不用在乎其它单元块对其的影响,专心应对当前所要实现的部分。再加上jml无二义性的描述,更加简化了我们对实现部分的思考与编写方式。
可以说,jml更加适合于模式化的程序编写,使得代码的编写过程更加漂亮与优雅。
但是我也明显感受到了jml的不足之处。一是它其实并没有提升我们的设计能力,纵使让我们自己去编写jml也不会达到相应的效果。因为在对大程序的分解设计的时候,其实并不需要用到jml,因为jml本身局限于某个函数块,就算是不用jml,主要我们有相应意识的时候,自然就能将一个大型程序去进行分解。二是jml过度专注于其本身的无二义性,却没有尝试过化简其自己的表达方式。例如在描述一个ArrayList的add方法的过程的时候,需要:添之前的元素的位置与现有元素位置不变、现有容器长度为原先容器长度+1、现有容器存在要添加的元素,并且这些描述很多要用到量化表达式,其实书写起来是很费时费力的。三是往往需要检验jml编写的对不对,就跟我们检验自己程序写的对不对一样,这样层层套娃反而觉得有些繁琐(主要还是jml编写的复杂度太高)。由于我们自己没有编写jml,所以暂时可能感觉不到,但是相信助教们在写jml的时候一定是非常痛苦的
jml或许今后我不会再用,但是其将一个函数的功能与实现分隔开的思想还是很值得我们学习的。
