面向对象设计与构造-第一单元作业总结
总结
第一单元作业的主要内容是多项式求导,虽然是一个比较常见的编写程序的例子,但是由于本人对于编写程序架构的认知为零,再加上三次作业的投入时间有限,导致在编写程序的时候遭遇了不少的问题,现在进行对这三次作业的不足之处进行反思。
主要的反思点可分为以下几个点,这些点也会从之后的作业剖析中体现出来。
-
代码的重写性问题
这里的重写包括两个方面:
一是不同作业之间的重构,由于本人在构思作业的时候都只考虑当前任务的实现方法,而从未对代码的拓展性进行过思考,导致每次新的作业发布时,都发现所需的架构与现有架构相去甚远,因此不得不推翻现有设计,重复编写代码,浪费了大量的时间。不过因为每次作业得任务内容未知,纵使耗费精力去思考也不一定使得代码的拓展性能满足下次作业得要求,因此能想到的想法也便只有以后提前从github上查看后面几次作业得要求,以遍提前做好准备。
二是已知大体架构编写代码的过程中,因为最早构思的时候并没有把细节想清楚,直到开始真正实现的时候发现可能要添加很多新的函数,或者写到后面发现已写的函数不能满足要求,于是要重新对前面的代码进行添加补足。这样的行为是很危险的,因为这样的作法相当于把一个函数在之前的基础上进行可能的分支添加,加上时间的因素可能会遗忘对要添加的函数的部分细节,容易导致添加新的bug,提高代码维护难度。即对方法的功能性未能提前做好充分的思考。
-
函数相关关系不清楚问题
一是函数所属类的认知错误。即将在不恰当的类去实现相应的函数,完全无视了“对象性”的编程模式,想着写一个能够满足功能的函数即可;亦或者是编写函数的时候思考范围超出了本身所属类的范围,比如编写时思考调用该函数所属的类的时候的情况并将其实现,也就是无视部分编写此函数默认的前提条件,这样子会增加编写难度,也会在编写时增加思考上不同函数之间的耦合性,并且容易出现bug。
二是函数间的调用习惯错误。函数的调用应当尽量采用单项调用的原则,即大函数调用小函数,尽量避免A调用B,而B也能调用A函数的的情况,不然会极度增加函数的圈复杂度。
三是函数间耦合性的认知错误。被调用函数应当无视可能被调用的情况,应当只用思考所需的条件已经假定成立,然后仅在已有条件的基础上进行编写。而调用函数应当为被调用函数提前创造必要的环境。这样便能降低在实现函数时,函数与其他因素的耦合性。
-
测试时对整个程序进行测验,而忽略了对单个函数的完备性测验
三次作业本人均是将代码写完后,最整个代码进行编写测试程序。但是对于整个程序来说,每一个函数都有一定可能性,多个函数可能性相乘,测试难度便会急剧增加,再加上自己构造的测试数据有限,因此有对整个程序进行测试的想法本身就是错误的。但是对于一个函数来说,在得知函数规定的已有前提条件的情况下,去对函数进行测试相对容易,而且比较容易实现完全集测试,这对于减少潜在的bug是非常有帮助的。
-
架构的建立过程的错误
本人在三次作业的编写过程中,都没有对架构建立的相应认识,尤其是第一次作业的编写,真的是看完题目直接上手就写,因此导致后面编写时多次进行对代码的重写。目前能想到的建立架构的方式如下:先
编写一个最简单的测试样例,进行一次对整个程序的模拟,以遍确定主要类与架构以及其之间的调用关系。然后再多次编写类型不同的测试用例,以确定主架构上的一些分支函数。这样就能够加速对代码架构的建立,也能减少直接上手发现架构错误的情况。
-
讨论活跃度问题
本人编写代码的过程中,基本上都是“闷声也不发财”,很少会与他人进行交流,包括与同学讨论不积极、讨论区看过的帖子屈指可数等等。但是像这种艰巨的任务,讨论与交流是很有价值的,思维上的碰撞有时能往往解决你苦思冥想好久的问题。这次因为交流的少,不仅丧失了修复bug的机会,丧失了学习他人架构的机会,甚至没有搭上使用自动评测机这样宝贵工具的班车。而且少的讨论未能带动编写的积极性,导致本人第三次作业周四白天写完,晚上以及周五和周六的白天都没再碰代码,周六下午一时心血来潮突然去对架构进行大刀阔斧的改革。结果也是可想而知的,最后到截止时间也未能修改完成,只能无可奈何的把这个能勉强通过中测的垃圾代码交了上去,强侧结果也不出人意料,非常令人不满意。
三次作业的具体分析
第一次
-
作业要求
第一次作业的内容较为简单,主要内容是实现简单多项式的导函数的求解
整个代码的实现过程可分为“表达式的读入”->"表达式的求导"->"合并同类项"->"表达式的输出"四个步骤。
因为只有幂函数这一种类型所以实现主要功能的类也比较简单,只需要幂函数类和能够装在幂函数的容器类即可。
读入过程只需要采用正则表达式的方法写出表达式的形式化描述。
实现的类与方法如下图:
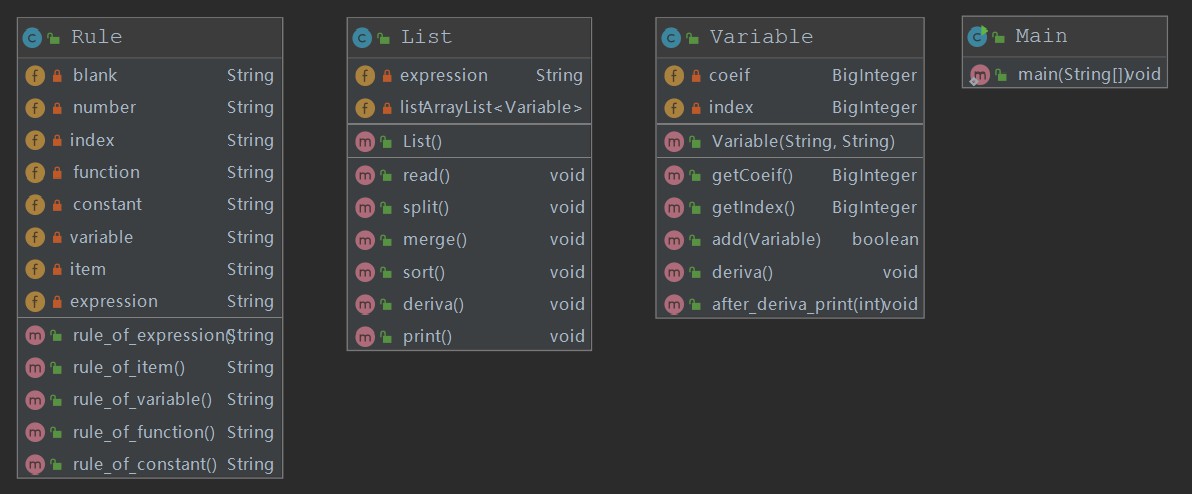
-
代码缺陷
本次代码的一大缺点就是犯了上述的“函数相关关系不清楚”问题。例如这次的输出函数,首先明白List是装载幂函数类变量的容器,在这个程序里就相当与一个表达式,存储了各个幂函数的信息,然而List的输出函数其实只是单纯的调用了幂函数类的after_deriva_print函数,相当于把输出的全责交给了幂函数类。然而这样的实现在逻辑上其实是行不通的,因为在结构上,表达式中幂函数之间应当用什么样的符号相连,理应不是幂函数应该考虑的事情,应当是表达式,即List类应该考虑的事情。然而这次作业的书写情况,其实就增加了函数在思考上之间的耦合性,身为Variable类的函数,竟然要考虑储存它的类————List类的情况,这样无疑增加了代码的书写难度。也许你会认为这样的小毛病看起来无可厚非,但是这样的思想在我第二、第三次作业应用到别的场景的时候,就会给人一种异样别扭的感觉,尤其是写一个类里的某些函数的时候感觉无从下手————主要是要考虑的事情太多,导致编写困难的情况屡屡发生。
-
代码度量
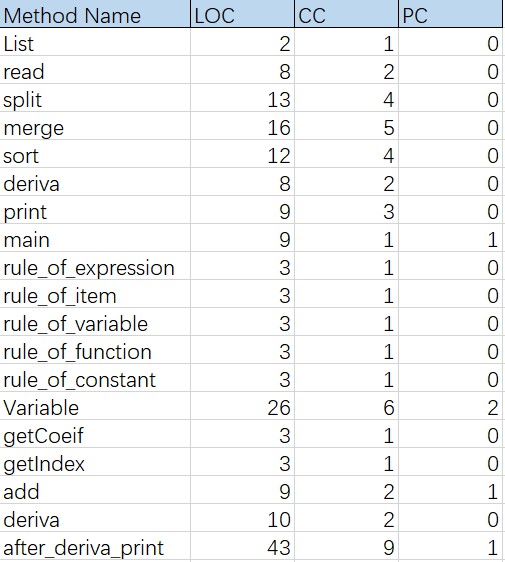
可以看出,除了Variable(也就是幂函数类)的圈复杂度(CC)值较高外,其余的还好。
这也在一方面应证了上述的代码缺陷,即犯了“函数相关关系不清楚”问题,导致函数的复杂度变高,难度增加。
第二次
-
作业要求
第二次作业引入了因子和项的概念,同时引入了三角函数这个基本的因子。因此结构的复杂性较第一次作业有了明显的提升。
首先要明白的是这是一个“表达式”->"项"->“因子”层层嵌套的关系,表达式中的项是“和”关系,项中的因子是“乘”关系。
整体过程较第一次作业并无太大改变,不过增添了很多内部的函数。整体过程依然为“表达式的读入”->"表达式的求导"->"合并同类项"->"表达式的输出"(其实三次作业整体过程都是这样)
表达式的读入方面,可以通过预处理来大大简化读入过程,比如将sin(x)转换为sine,从而避免了三角函数与幂函数读取的冲突问题;可以将隐式的幂次,如x转换为显示的x**1,这样也会少了一些判断。
求导过程多了函数乘积的求导,应当注意的是基本类求导后类型的转换,比如x**2是一个幂函数类,求导之后会变成项类。
代码结构如下:

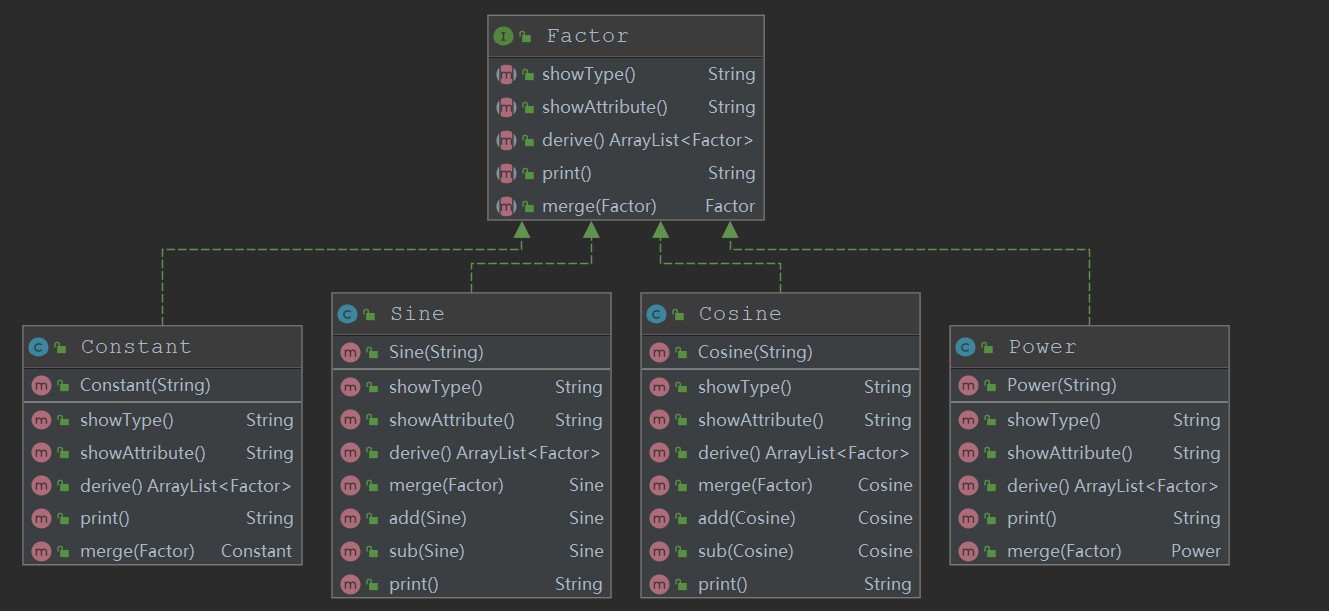
-
问题剖析
这次直接先量DesigniteJava结果把,后面慢慢剖析
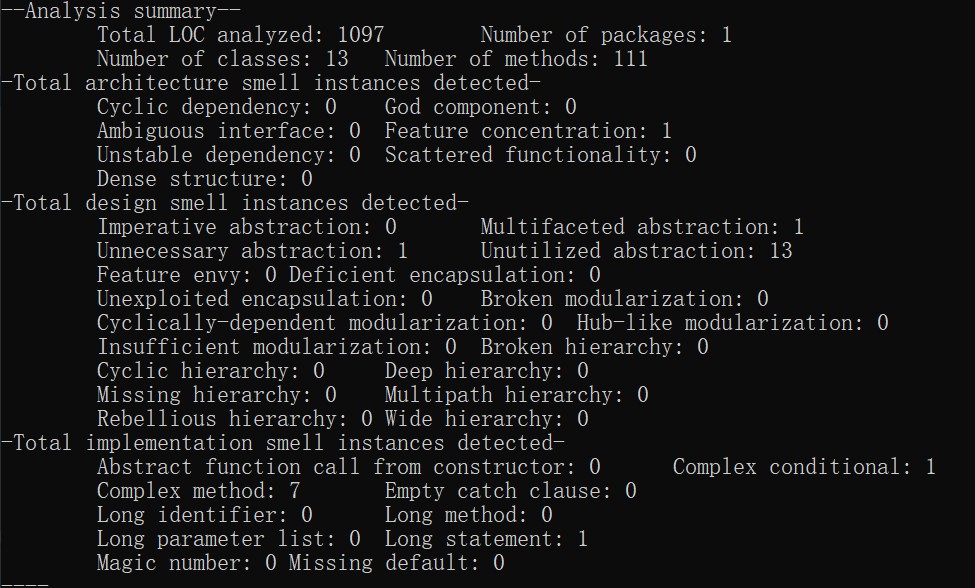
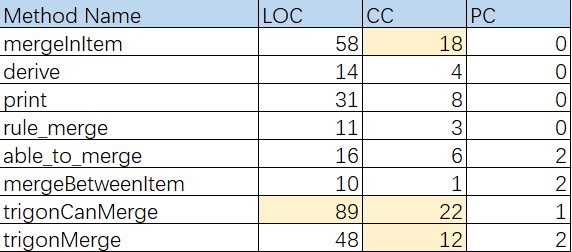
+ 第一个问题比较特殊,不属于上述问题之一。那就是浅拷贝问题。问题的发现来源于一次debug,就是Item(项类)里的trigoncanMerge函数,该函数的作用是判断两个项是否能够满足优化合并的条件,返回一个布尔值,然而在debug的过程中,发现运行完这个函数后,表达式里的项会被莫名其妙的修改,并且这个函数中开头便是对所用的两个项进行复制,然后再通过一些操作去进行判断,本来逻辑上看这段代码是没有问题的,先拷贝,再操作,不会影响传入的参数。然而,由于我的Item类本身就是一个容器,再加之我判断的方法很混乱,会对拷贝后的容器里的因子进行修改,于是就出现了两个不同的对象却管理了相同的因子的情况,这时候一个容器对象里的元素会被另一个容器对象进行修改————这种行为是非常危险并且难以察觉到的。
因此,解决这个问题的方法应当为:为每个管理数据的类增添一个clone方法,比如以这个程序模型为例,Expression.clone能够调用Item.clone,后者能够调用里面的元素Constant.clone、sine.clone等等,这样便能从最基本的类型进行克隆,从而避免了管理元素的冲突性问题。不过这是不是牺牲时间来换取安全性的一种做法?可能会降低程序性能。
+ 第二个所犯的问题是“架构构思”的错误。因为编写架构的时候未能注意到Item容器里元素的排布特征,我所选的排布方式仅仅为常数最前,然而常数后面的幂函数、三角函数的排布方式确实非常混乱的,这也导致了我在实现部分功能,如项之间的MergeInExpression合并的时候,进行了许多对于因子可能在项内位置的判断,甚至在项内合并MergeInItem也出现了这样复杂的判断,导致我的某些函数块显得十分臃肿,因为它需要考虑项内元素在项内的各个位置的情况。其实这次作业完全可以通过某种约束使得项内不同类型的因子的位置得到确定,比如大家都在用的四元组方法我这样的架构虽然整体上功能划分明确且功能块较少,但是实际操作起来的时候,能够明显的发现某些功能不应该在原本预定好的功能块里,应当抽象出来,这样不仅使每一个函数块的编写难度降低,而且整体的逻辑会更加清晰一些。
+ 第三个所犯的问题也便是我最常犯的“函数位置放置错误”的问题。这个问题也可以由DesigniteJava的“long stetement”反映出,这个问题关键是会混淆不同类的“对象”特性,一个方法应当写入与该方法实现的功能最密切的类里,然而为了急忙实现额外的、特殊的功能,不假思索把新添的函数放置到一个最利于当前自己写的位置,与面向过程的思维方式又有什么区别。例如这次作业中的trigonCanMerge函数,当时想的是因为三角函数可能与别的因子组成项,所以放在项里去实现三角函数得合并是不是更方便一些,于是Item类(项 类)便负责了相应的全部功能,然而项出去系数后三角函数得合并是不是可以由三角函数类去完成,返一个项在与其它的因子组合?也许这样会稍显麻烦一些,但是由三角函数类自身去实现三角函数合并的功能会显得更加自然一些,即实现了方法与类的逻辑上的联系性。
+ 第四个所犯的问题便是上述的“函数调用关系非单项”造成的。这个问题可以由DesigniteJava的“Complex method”反映出,标黄的便是圈复杂度过高的重灾区。因为未能理清确定的调用过程,有的时候竟然会写出部分循环调用的步骤,导致调用关系更加复杂,应该尽量由上级函数调用下级函数,避免下级或下级的平级有时能出现调用上级的情况。
第三次
-
前言
这次作业完成的是最失败的一次,究其原因就是对作业的态度不端正。原本周三周四草草写完的代码,应该耗费更大的精力去对代码进行大量的测试,然而当时觉得去构造能涵盖大部分情况的样例会很麻烦,这就是上述所说的“程序检验”的错误问题,代码量过于庞大,情况过于复杂,又想要通过无视代码特性的,仅从整体功能角度入手的“黑箱测试”去测试大部分情况,这样的难度是非常大的,很容易将人劝退。于是我周四晚上以及周五,周六白天都没有碰过这次编写的代码。周六下午突然觉得自己之前编写的架构很奇怪,于是又决定将某些大的功能块去进行修改,不过当时时间有限,心里很浮躁,又加上下午写代码效率低下,导致本人连续写了6个小时都没有将架构完全修改完,甚至最后交上去了一个半成品,并且几乎未对代码进行过什么测试,很是失败。
今后要争取花费更多的精力在代码的测试上,多多询问同学们的测试经验,以避免像这次这么糟糕的事情再度发生。
-
作业要求
这次作业相比于第二次作业而言,最大的不同便是可支持嵌套结构,即表达式因子的出现,以及三角函数的内部因子可以为表达式因子。无疑大量的增加了结构的复杂程度。
这次带来的问题很多。
一是如何去对输入进行读入。现有两种方法,一个是使用字符自动机类型的方式去进行读入,然而这种方式的编写难度极高,即需要自己去清楚添加一个字符后所可能产生的所有情况,很容易写漏或者有思考错误的地方,而且也不利与代码bug的检测与代码的修改。第二个方法也是我才用的方法,仍然延续了上两次作业读入方法————正则表达式,可是正则表达式无法构建出含有递归的规则,于是受人点播,要用魔法打败魔法!要用递归去处理递归。关键的递归因素是表达式内有项,项内为因子,而因子却可以为表达式。那么只需将表达式里的第一层表达式因子进行修改,修改为一个常数符号,那么整个表达式就可以看作内部递归项为常量的表达式了,便可以进行处理,随后再处理内部的递归项即可。
二是如何将嵌套结构进行简化,这也是本次作业最关键的地方。由于本人的架构不佳,可能出现一个项的情况为:项->表达式->项->表达式......->项,其实这个项是等价于内部嵌套的最后一个项的,但是其本身的形式限制了许多操作,比如合并同类项等,关键是这还是一个递归的嵌套,仅仅通过一两次非递归的处理是不可能得到其原本的类型的。因此在设计上要想办法用递归的方法去消除这种递归的嵌套。
剩下的处理方式与第二次作业很像,无需多言。
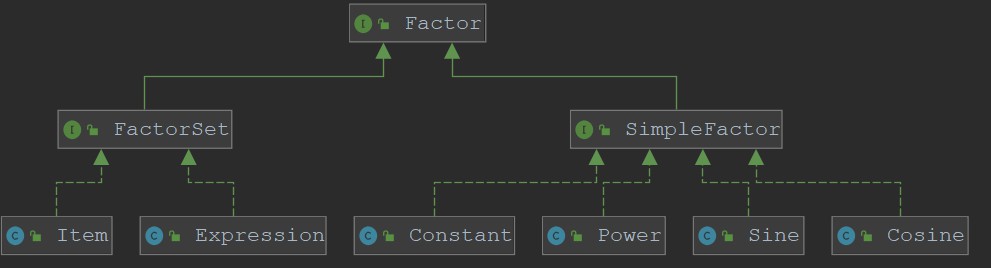
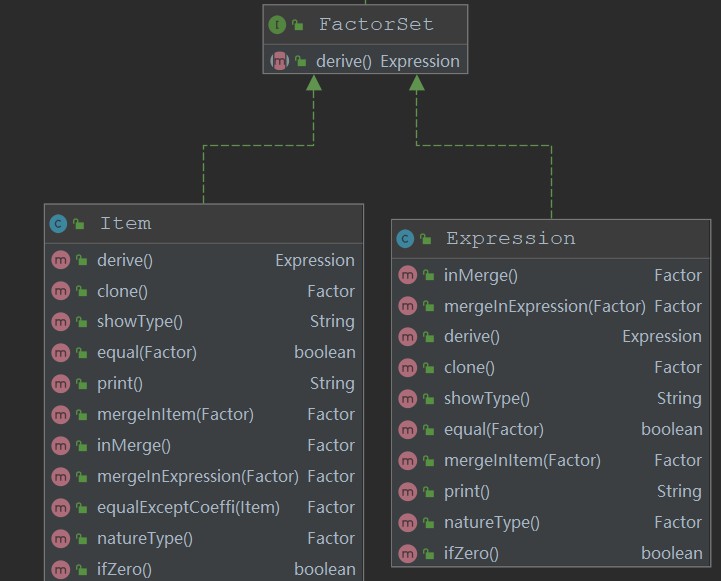
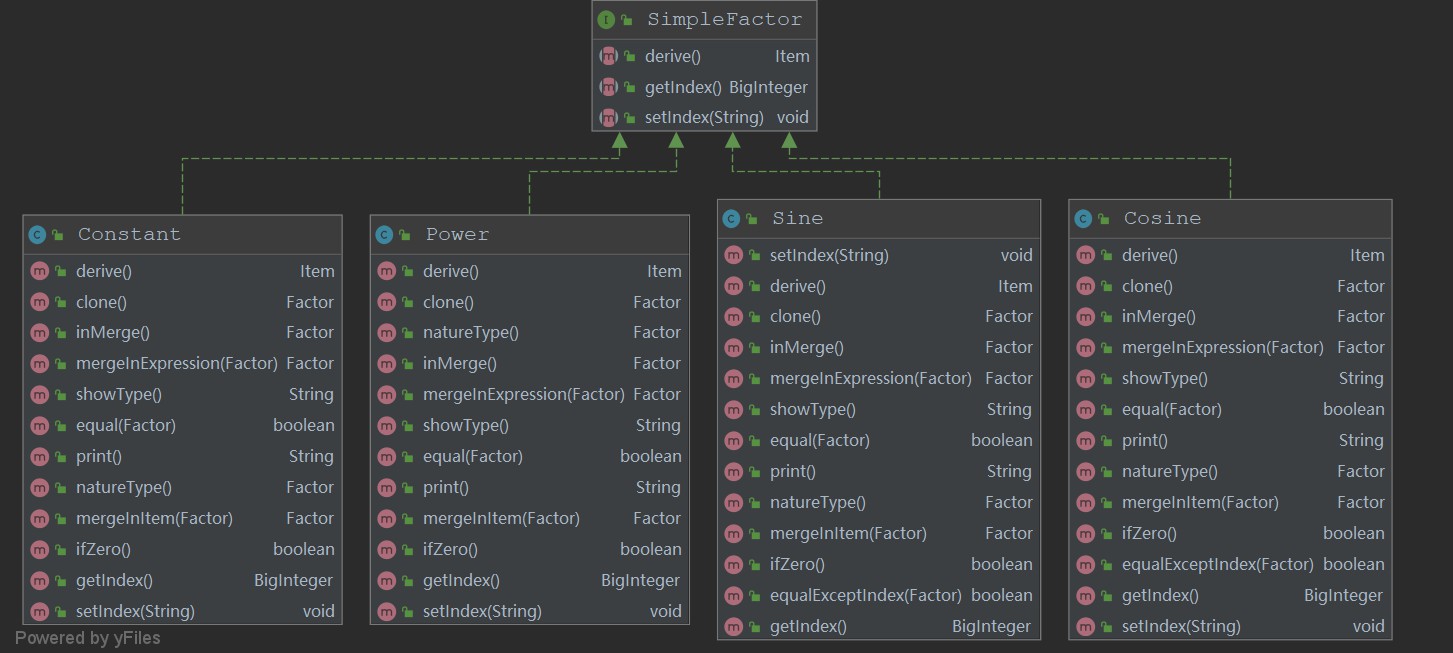
由于这次提交的作业质量很糟糕,所以下面展示的结构为修改后并非提交的程序:
-
问题剖析
话不多说,先亮DesigniteJava运行结果,后面对该运行结果进行分析
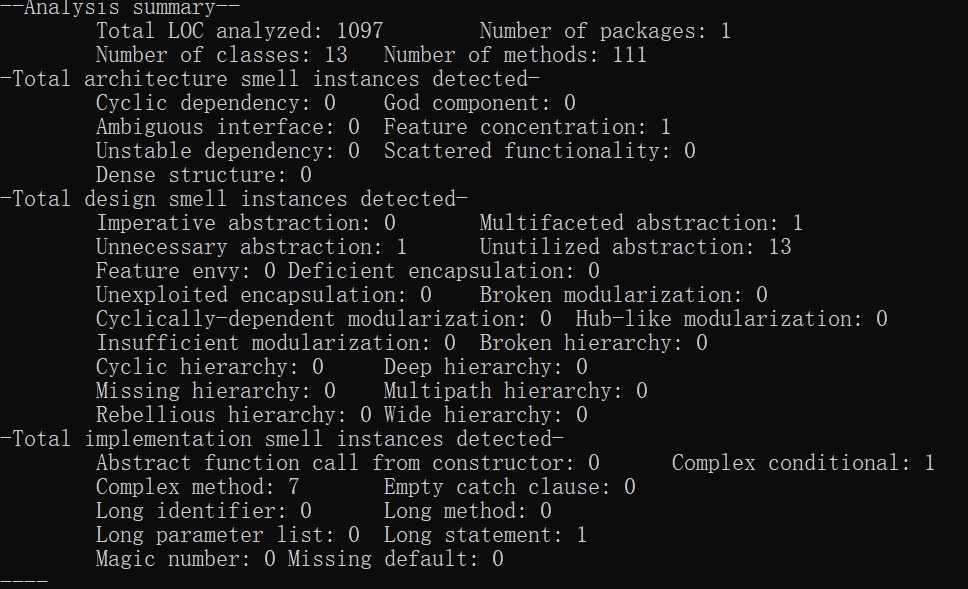
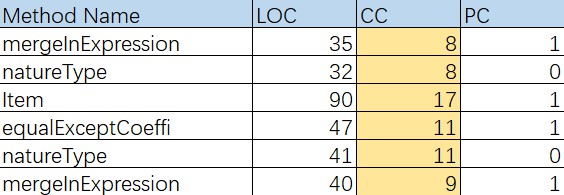
首先这次结果较上次而言稍微有些改观,虽然仍然有很多方法块的“Method Complex”很高,但是仅有一个Item的构造方法的复杂度为17,其他都相对均匀的分布在10左右。不像上次作业的trigonMerge方法复杂度飙到了22,以及MergeInItem复杂度为18等等。虽然这次“long statement”也有,不过也就一个Item的构造方法比较长,但是其功能相对来说也比较单一,对比上次方法功能的混乱,也稍微有些改观。
但是这次作业的问题仍然有很多,其中较多部分问题与第二次作业重复,这一部分就暂且不提,来看看在第三次作业中暴露的最明显的问题,就是“架构建立关系错误”的问题:
首先明确facter接口实现的是与因子相关的操作;factorset接口实现的是装在因子的容器,也就是项类和表达式类应该实现的接口;simpleFactor实现的是非容器性因子,如常数因子、幂函数因子、三角函数因子的一些方法。
三者内部定义的方法如下:
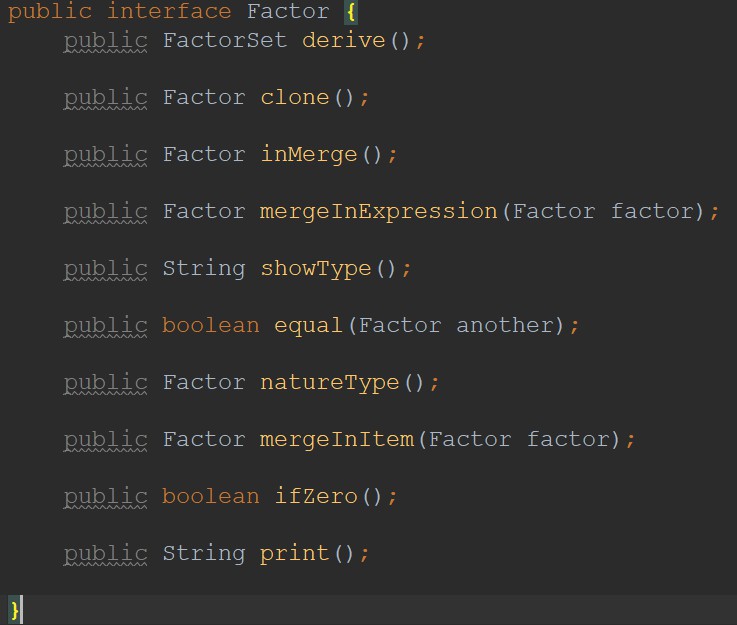

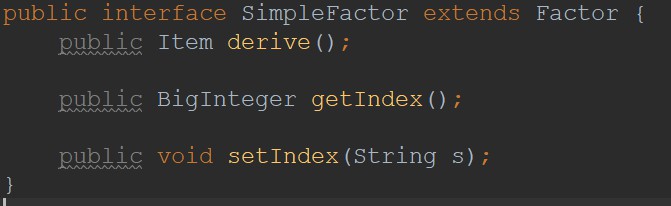
现在看来,这三个接口内部定义的方法非常不好。比如Factor类内的inMerge(内部合并)方法按照逻辑上来说应当放入factorSet接口内,因为只有容器类的因子才能实现内部的同类相合并,当时只是一时为了后面的判断能够更加简便一些也许并不简便,而索性将该方法写入了Factor接口类,现在想起来都有点违和。以及derive其实没必要在factorSet类和SimpleFactor类内再次重写一遍,其实只需要后面实现时向下转型的操作即可。
剩下的问题较第二次有较多重复,这里就暂且不提了。
程序Bug分析
- 第二次作业:该作业的bug是互测时检测出来的,即在判断三角函数合并部分的时候少了一个特殊的判断,导致两个项提取公因式以后,某些特定情况下,公因式不同也会对三角函数进行计算合并。
- 第三次作业:该作业互测检测出的bug极多,原因在上面也说了清除。不过之前所说的后来自己修改架构的代码均能通过,但是现在依然都没对后面的代码进行测试,bug目前还未知。
发现别人程序bug所采用的策略
这几次对别人程序的bug寻找都不积极。
主要采用的方法是漫无目的的黑箱测试,即仅通过已知的标准功能去构造一些测试数据,但是这样的构造显然效率是很低下的。
另一些方法包括与同学交流,(实际上是伸手党)将讨论的的测试数据用于对别人的代码进行测试,(效果拔群)。也有利用别人用自动评测跑出来的某些结果进行测试。(我已经是个废人了)
应用对象创建模式
- 尽量使用接口,应当明确方法定义时所属的接口类型
- 对于浅拷贝问题,要为每个管理基本数据的类实现clone方法
对比与心得体会
其实心得体会与反思在文章的开头就已经差不多说完了,这里再重新描述一下:
- 构思架构时采用提前手动模拟的方式去决定主要框架,然后再使用不同的测试样例去确定一些分支函数。
- 函数定义时应当满足:功能尽量具体单一、功能理应与函数所属的类有密切联系、尽量在不超出已有的条件的范围思考、尽量使用单项调用原则。
- 代码测试应当尽量对功能块进行测试,而不是对整个程序进行测试。
- 以后作业要积极与同学讨论,多参考
(伸手)大佬们的想法,多进行思维的碰撞
