搜索与图论
DFS
dfs,即深度优先搜索,主要运用递归的思想。会将一种可能性搜索完的情况下再开始搜索下一种可能性。
[蓝桥杯 2016 国 AC] 路径之谜
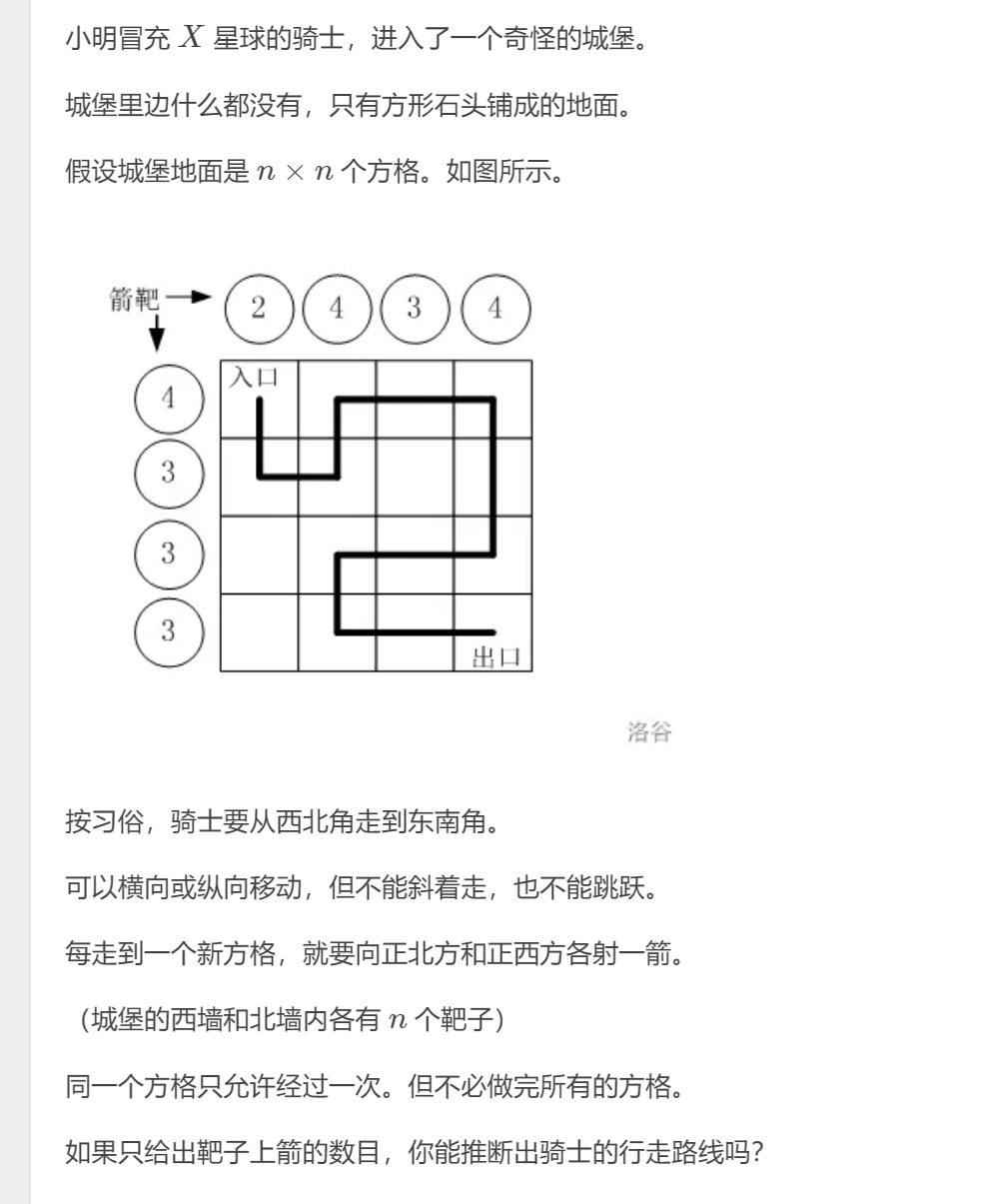

我一开始想的是先把可能方案的格子选出来然后进行dfs判断是否能走成,但dfs套dfs太麻烦了
事实上直接爆搜就能解决
爆搜时对于每个点都减去对应行列的数组值,如果小于0则回溯,需要注意回溯时必须把行列数组也回溯
然后如果到达终点就判断一下所有的行列数组是否为0,如果不是0就回溯
还有就是(1,1)点是固定的所以一开始要将第一行和第一列的数组值减一,另外vis也要标记为1,我查了挺久原因就是vis[1,1]没初始化为1导致错一个点
#include<bits/stdc++.h>
using namespace std;
const int maxn=25;
int a[maxn],b[maxn],vis[maxn][maxn];
int hang[maxn],lie[maxn];
int ans[1000];
int n,flag=0;
int xx[5]={0,1,-1,0,0};
int yy[5]={0,0,0,-1,1};
bool check()
{
for(int i=1;i<=n;i++) if(hang[i]||lie[i]) return false;
return true;
}
void dfs(int x,int y,int step)
{
if(x>n||x<1||y>n||y<1) return;
if(flag) return;
if(x==n&&y==n)
{
if(check())
{
for(int i=1;i<step;i++) printf("%d ",ans[i]),flag=1;
}
return;
}
for(int i=1;i<=4;i++)
{
int dy=y+yy[i],dx=x+xx[i];
if(vis[dy][dx]) continue;
if(hang[dy]&&lie[dx])
{
vis[dy][dx]=1;
hang[dy]--;
lie[dx]--;
ans[step]=n*(dy-1)+dx-1;
dfs(dx,dy,step+1);
vis[dy][dx]=0;
hang[dy]++;
lie[dx]++;
}
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
lie[i]=a[i];
}
a[1]-=1;lie[1]-=1;
for(int i=1;i<=n;i++)
{
scanf("%d",&b[i]);
hang[i]=b[i];
}
b[1]-=1;hang[1]-=1;
vis[1][1]=1;
ans[1]=0;
dfs(1,1,2);
return 0;
}
acwing 1355母亲的牛奶
给你三个不同大小的桶,一开始只有c桶装满牛奶,三个桶来回倒,求问在a桶空着的情况下c桶可能有多少牛奶,答案升序输出
数据很小,我们考虑每种情况而并非考虑每个桶,开一个三维数组记录是否出现过相同情况,相同则return
并且由于我们的vis数组考虑的是单独情况而非是否选某个点,因此不需要回溯(这样说有点歧义,总之就是不用讲vis数组变为0)
#include<bits/stdc++.h>
using namespace std;
int A,B,C;
struct node
{
int a;
int b;
int c;
};
int vis[30][30][30];
int avis[30];
int ans[30],cnt=0;
void dfs(int a,int b,int c)
{
if(vis[a][b][c]) return;
vis[a][b][c]=1;
if(!avis[c]&&a==0) avis[c]=1,ans[++cnt]=c;
dfs(a-min(a,B-b),min(a+b,B),c);
dfs(a-min(a,C-c),b, min(a+c,C));
dfs(min(a+b,A),b-min(b,A-a),c);
dfs(a,b-min(b,C-c),min(c+b,C));
dfs(min(a+c,A),b,c-min(c,A-a));
dfs(a,min(b+c,B),c-min(c,B-b));
}
int main()
{
cin>>A>>B>>C;
dfs(0,0,C);
sort(ans+1,ans+cnt+1);
for(int i=1;i<=cnt;i++)
printf("%d ",ans[i]);
return 0;
}
洛谷P1219 八皇后
给你一个n* n的棋盘与n个棋子,问怎样拜访能使得每个棋子的行列对角线均不同,输出前三种结果和结果个数
相当经典的dfs,我们用四个数组分别储存是否到达过某行某列或者某对角线。那么不难想到一种搜索方法:对每个格子进行搜索,并对该格子判断是否符合要求。这样我们每次都令j+1,到达最右端时将j归为1,i+1即可。
但与此同时,我们不难想到,既然每行每列都不能重复,那么假如我们在第一行第一列放了一个棋子,第一行的剩下的所有的都不用考虑了,我们只需要考虑第二行放在哪即可。
因此我们dfs可以传入一个参数u表示当前是第几行,每次枚举这一行的所有列进行搜索,在u=n+1时更新结果,代码如下。
#include<bits/stdc++.h>
using namespace std;
int n;
bool lie[20],dui1[20],dui2[20];//dui1 i+j-1 ;dui2 i+(m-j)
int ans[20],cnt=0,sum=0;
void dfs(int u)//第u行
{
if(u==n+1)
{
sum++;
if(++cnt>3) return;
for(int i=1;i<=n;i++)
{
printf("%d ",ans[i]);
}
printf("\n");
return;
}
for(int i=1;i<=n;i++)
{
if(lie[i]||dui1[u+i]||dui2[u+n-i+1]) continue;
lie[i]=dui1[u+i]=dui2[u+n-i+1]=1;
ans[u]=i;
dfs(u+1);
lie[i]=dui1[u+i]=dui2[u+n-i+1]=0;
}
}
int main()
{
cin>>n;
dfs(1);
printf("%d",sum);
return 0;
}
ACwing167 木棒

由于我们不知道木棒一开始有多少根,因此没法用当前是第几根木棍作为结束搜索的条件。继续思考,需要确定的点有几个:1.最后拼成几根木棍 2.每根木棍有多长 这两者其实是一个问题,因为两者相乘便是木棍总长度,因此我们选择枚举每根木棍的长度并判断该长度是否可行。由于我们要输出可能最小长度,因此我们从小到大枚举长度len,在dfs中传入两个参数,分别记录当前是第几根木棍和当前木棍已经多长,当当前木棍长度和len相同时则处理下一根木棍。
但是只有这样是会tle的,因此我们需要剪枝优化。
如何剪枝?有一点是很容易想到的:1.当且仅当木棍长度是总长度的约数时,才有可能成功,因此我们对每个len进行判断,如果不符合直接跳过。
2.假如答案中将编号为1,2,3的木棍组成一根,那么显然在搜的时候会出现(1,2,3)(1,3,2)(2,3,1)等情况,但他们的总和是相等的,因此是冗余的计算。因此我们需要把重复的排列减去。提供的方法时在搜索时令每根长木棍中的段木棍编号升序排列。
3.我们枚举每一根木棍,当我们已经知道这根木棍不能用时,那么显然后面的木棍也不能使用,因为每根木棍都要用到。那么我们如何找到第一根用不上的木棍呢?如果假设一个木棍是第一根用不上的,那么它一定是它原本要形成的长木棍里的第一根。因为它前面的木棍全都可以被使用,所以当我们找到一根木棍作为一根长木棍的开头并且无法成立时,我们就不必要再继续循环了。
4.当一根木棍作为一根长木棍的最后一根木棍无解时,结束循环。试想,若有解,则是用后面的多根木棍和该木棍交换。但事实上,两根木棍可以合起来也可以拆开,所以两根或者多根木棍可以做到单根所有的功能,单根却不能做到多根的功能。因此,原来多根无解的情况,现在换成单根也必然无解。
事实上最主要的剪枝是1,其次是2,acwing实测3和4不加也能过,而且3和4太难想了
#include<bits/stdc++.h>
using namespace std;
int n;
int a[100],vis[65];
int len,sum=0;
bool dfs(int u,int now,int strat)//现在是第几根长木棍,并且目前有多长
{
if(u*len==sum) return true;
if(now==len) return dfs(u+1,0,1);
if(u>n||strat>n||now>len) return false;
for(int i=strat;i<=n;i++)
{
if(vis[i]) continue;
if(now+a[i]<=len)
{
vis[i]=1;
if(dfs(u,now+a[i],i+1)) return true;
vis[i]=0;
}
if(!now||now+a[i]==len) return false;
int j=i+1;
while(a[i]==a[j]) j++;
i=j-1;
}
return false;
}
bool cmp(int a,int b)
{
return a>b;
}
int main()
{
while(cin>>n&&n!=0)
{
sum=0;
memset(vis,0,sizeof vis);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
sum+=a[i];
}
sort(a+1,a+n+1,cmp);
len=a[1];
while(1)
{
if(sum%len!=0)
{
len++;
continue;
}
if(dfs(1,0,1))
{
printf("%d\n",len);
break;
}
len++;
}
}
return 0;
}
BFS
又称广度优先搜索,和bfs思想上的区别主要在于bfs是对于每种情况,会将它后续可能的下一步情况一一进行处理。而dfs则是选中下一步情况的某一个一直搜直到搜出结果再进行另一种情况。(也就是bfs每次都能获得每种情况的每一步结果,而dfs要先得到一种情况的结果再进行下一种情况)。这样的特性使得bfs适合做最短路。因为所有情况都是同步进行的,那么先达到目标点的情况就是最短的情况。
而在实现方法上,bfs采用队列的实现方法,每次发现新的可行方案时将该情况放到队尾,也就是说对于一种情况,它的所有下一步情况都会被依次放进队列,这样就能保证他们能依次被处理。
acwing 1355母亲的牛奶
没错,还是这题,写了bfs版本的
#include<bits/stdc++.h>
using namespace std;
struct node
{
int a;
int b;
int c;
};
queue<node> q;
int A,B,C;
bool vis[25][25][25];
int vans[25];
int ans[50],cnt=0;
void inst(int a,int b,int c)
{
if(!vis[a][b][c])
{
q.push({a,b,c});
vis[a][b][c]=true;
}
if(!vans[c]&&a==0)
{
ans[++cnt]=c;
vans[c]=1;
}
}
void bfs()
{
q.push({0,0,C});
vis[0][0][C]=1;
while(!q.empty())
{
node h=q.front();
q.pop();
int a=h.a,b=h.b,c=h.c;
inst(a-min(a,B-b),min(a+b,B),c);
inst(a-min(a,C-c),b, min(a+c,C));
inst(min(a+b,A),b-min(b,A-a),c);
inst(a,b-min(b,C-c),min(c+b,C));
inst(min(a+c,A),b,c-min(c,A-a));
inst(a,min(b+c,B),c-min(c,B-b));
}
}
int main()
{
cin>>A>>B>>C;
bfs();
sort(ans+1,ans+cnt+1);
for(int i=1;i<=cnt;i++)
printf("%d ",ans[i]);
return 0;
}
最短路
单源最短路
无负权边
dijkstra
dij分为两种,一种是朴素版本的,时间复杂度是On方,,一种是堆优化版本的是O(mlogn)。一般我们比较经常用的是堆优化版本的。但在对于边数很多但点数很少的稠密图当中朴素版本的方法还是有用武之地的。
朴素版本dij
我用一张图来演示下它的主要思想
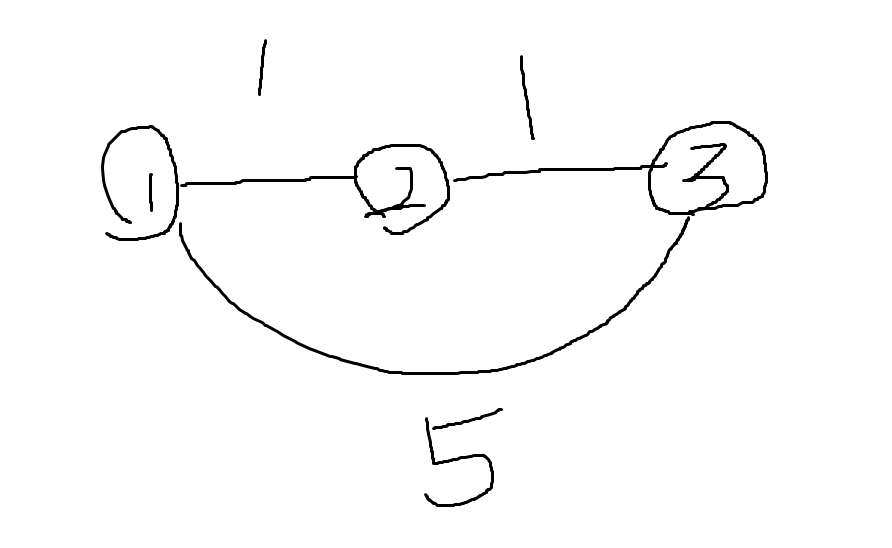
在这张图上,通过2再到达3显然要比从1直接到3要短,我们的目标就是通过这样的方式更新出所有的最短路。那么怎么保证更新的正确性?从起点开始,我们首先找一个距离最近的点(第一轮是起点),然后用这个点作为中继点更新其他的所有点。每轮找完之后我们将这个中继点标记成用过的,第二轮找一个距离出发点最近的没标记过的点进行同样的操作,重复n次即可。
//以s点为起点寻找到每个点的最短路,若不存在则输出int最大值
#include<bits/stdc++.h>
using namespace std;
int n,m,s;
const int maxn=1050;
int e[maxn][maxn];
int dist[maxn];//1到i的最短距离
int vis[maxn];//是否用该点更新过答案,同时也代表该点是否已经确定最短路
void dij()
{
memset(dist,0x3f,sizeof dist);
dist[s]=0;
for(int i=1;i<=n;i++)
{
int t=-1;//用它来表示本次以哪个点为中继点
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1||dist[j]<dist[t]))//若该点没使用过并且该点是剩下点距离最短的
{
t=j;
}
}
vis[t]=1;
for(int j=1;j<=n;j++)
{
dist[j]=min(dist[j],dist[t]+e[t][j]);
}
}
for(int i=1;i<=n;i++)
if(dist[i]==0x3f3f3f3f) printf("2147483647 ");
else printf("%d ",dist[i]);
}
int main()
{
cin>>n>>m>>s;
memset(e,0x3f,sizeof e);
for(int i=1;i<=n;i++)
e[i][i]=0;
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
e[x][y]=min(e[x][y],z);//若有重边取最短的边使用
}
dij();
return 0;
}
堆优化dij
上面的代码是n方的,具体来说是每次找到距离原点最近的点是n次,内循环每次更新最短路也是n次,其中每次寻找最近的点有很多计算冗余。如果我们想尽快的找到最近的点该如何?此时我们能够想到一种数据结构:堆。
堆的原理是按照自定义的顺序建立一个完全二叉树,如果定义的顺序是升序,那么每个节点的父节点都要小于当前节点,也就是说根节点必然是最小的节点。这样我们每次查询最小值就可以改进成O(1),而插入则是logn
由于优先队列内部是用堆实现的并且代码相对好写,因此我们一般用优先队列来实现堆优化dij
实现代码具体如下
来自之后的提示:普通dij外层循环只用循环n次,但这里必须要判断优先队列为空才行,因为一旦出现多次更新同一个点就会多次入队,如果恰巧这个点在前n次循环出现多次就会导致错误
以及在刚弹出队顶元素时必须判断vis[now]是否为0,即使在之后加入队列时判断了,这里没判断也不行。因为会出现这种情况:一个点在它还没有被放入过队列时被更新了多次,然后就依然会push多次,只有当它第一次出队时vis数组才会被标记。因此要在每次出队时都判断vis数组,否则会多相当多的冗余计算。
struct node
{
int dis;
int pos;
bool operator <(const node &a)const
{
return a.dis<dis;
}
};
priority_queue<node> q;
由于我们要确定距离原点最近的点,因此需要放入的信息有两个:点的编号以及和原点的距离。重载运算符则是自定义排序顺序为按dis从小到大。
关于存图
由于n数量较大,因此我们不可能再用二维数组来储存边,我用的方法是链式前向星,通俗来讲就是用链表存图
我们给每个边都编号,例如我们建一条从1到2的边,则该边编号为1,我们就将编号为1的边放在点1后面
假如我建立以下几条边
(1,2)(2,3)(1,3)
则在链式前向星中看起来是这样的
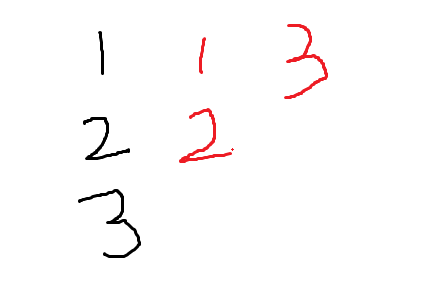
我们用额外的数组来储存每条边指向的点以及边的权值,具体实现如下

first数组是为了记录每个点连着的第一条边(实际上是最后一条加入的边),只有获取这条边的信息我们才能遍历其他边
完整代码如下
#include<bits/stdc++.h>
using namespace std;
int n,m,s;
const int maxn=1e6+10;
int dist[maxn];//1到i的最短距离
int vis[maxn];//是否用该点更新过答案
struct edge
{
int to;
int next;
int w;
}e[maxn];
int first[maxn],tot=0;
void add(int x,int y,int z)
{
tot++;
e[tot].w=z;
e[tot].to=y;
e[tot].next=first[x];
first[x]=tot;
}
struct node
{
int dis;
int pos;
bool operator <(const node &a)const
{
return a.dis<dis;
}
};
priority_queue<node> q;
void dij()
{
memset(dist,0x3f,sizeof(dist));;
dist[s]=0;
q.push({0,s});
while(!q.empty())
{
node now=q.top();
q.pop();
int d=now.dis,p=now.pos;
if(vis[p]) continue;
vis[p]=1;
for(int i=first[p];i;i=e[i].next)
{
int y=e[i].to;
if(dist[y]>dist[p]+e[i].w)
{
dist[y]=dist[p]+e[i].w;
q.push({dist[y],y});
}
}
}
for(int i=1;i<=n;i++)
if(dist[i]==0x3f3f3f3f) printf("2147483647 ");
else printf("%d ",dist[i]);
}
int main()
{
cin>>n>>m>>s;
memset(e,0x3f,sizeof e);
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
add(x,y,z);
}
dij();
return 0;
}
存在负权边
众所周知,dij是无法处理负权边的,因为dij理论得以实现的基础是每次都能找到离原点最近的点。在没有负权边的图上,可以保证所有没有被搜到的点都比已经搜到的路径要长。但若存在负边则会出现没有搜到的点距离原点的距离更短的情况。
bellman-ford算法
这种算法是时间复杂度是m* n,在绝大多数情况下要劣于下一个要讲的算法spfa,但当处理一种情况时需要用到它:在限定只能经过k条边时求原点到某一点的最短路。
acwing 853

这个算法是要遍历所有边的,因此存边比较简单粗暴,直接开一个结构体一股脑权存进去就行
然后外层i循环k次,内层j循环m次不断松弛。
比较值得注意的点是对于同一个i的每个j它们的松弛操作是相互独立的,不能互相干扰,但后面的j难免被已经更新过的前面的j影响,因此我们额外开一个数组记录每个i时候的答案状况。将数组a全部复制到b上的操作是memcpy(b,a,sizeof a);比循环赋值要快一些
完整代码如下
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+10;
const int inf =0x3f3f3f3f;
int n,m,k;
int dist[maxn],backup[maxn];
struct edge
{
int a;
int b;
int w;
}e[maxn];
int bellman()
{
memset(dist,0x3f,sizeof dist);
dist[1]=0;
for(int i=1;i<=k;i++)
{
memcpy(backup,dist,sizeof dist);
for(int j=1;j<=m;j++)
{
int x=e[j].a,y=e[j].b,c=e[j].w;
dist[y]=min(dist[y],backup[x]+c);
}
}
if(dist[n]>=inf/2) return -inf;
else return dist[n];
}
signed main()
{
cin>>n>>m>>k;
for(int i=1;i<=m;i++)
{
int x,y,z;
scanf("%d%d%d",&x,&y,&z);
e[i].a=x;
e[i].b=y;
e[i].w=z;
}
int ans=bellman();
if(ans==-inf) cout<<"impossible"<<endl;
else printf("%d",dist[n]);
return 0;
}
spfa
spfa可以说是bellman的优化版本,他优化就优化在将待更新的边放入一哥队列中,给队列中的数打上标记,避免队列中同时出现多个相同点,很大程度上减少了重复运算.每个点入队时标记上,出队时取消标记即可
代码如下
#include<bits/stdc++.h>
using namespace std;
const int maxn=5e5+10;
int vis[maxn],dist[maxn],first[maxn],tot=0;
int n,m,s;
struct edge
{
int to;
int nxt;
int w;
}e[maxn];
void add(int x,int y,int z)
{
tot++;
e[tot].to=y;
e[tot].w=z;
e[tot].nxt=first[x];
first[x]=tot;
}
queue<int> q;
void spfa()
{
memset(dist,0x3f,sizeof dist);
dist[s]=0;
q.push(s);
vis[s]=1;
while(!q.empty())
{
int x=q.front();
q.pop();
vis[x]=0;
for(int i=first[x];i;i=e[i].nxt)
{
int y=e[i].to,w=e[i].w;
if(dist[y]>dist[x]+w)
{
if(!vis[y]) q.push(y);
vis[y]=1;
dist[y]=dist[x]+w;
}
}
}
for(int i=1;i<=n;i++)
{
if(dist[i]==0x3f3f3f3f) printf("2147483647 ");
else printf("%d ",dist[i]);
}
}
int main()
{
cin>>n>>m>>s;
for(int i=1;i<=m;i++)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
spfa();
return 0;
}
spfa判断负环
我们知道,如果存在负环,那么在寻找最短路时就会不断经过这个环。spfa可以判断负环的原理在于它由于是枚举边,因此可以记录目前走过的边的数量。如果有负环那么会经过这个环无穷大次,我们设立一个cnt数组记录到达某个点时的点的数量,如果我们用一条x到y的边更新y点的答案,那么就令cnt[y]=cnt[x]+1。当cnt中的某个数超过n时说明存在负环。
如果我们判断整个图存不存在负环,则需要在一开始将所有点都加入队列。因为可能出现起始点s无法到达负环的情况。并且此时我们不需要初始化dist数组,因为每个点都要进入一遍,那么负环上的某个连接负数边的点也肯定会进入,然后在遍历到负边时一定会更新答案,并且一定存在以某个点为起点可以遍历负环。
如果判断以s为起点能到达的负环,则需要初始化操作,在正常的spfa代码上加一步即可
下面题目是要求如果整个图中出现负环则输出-1,其他情况输出最短距离。我们需要把spfa跑两边,第一遍跑负环,然后初始化数组后再跑最短距离,否则vis数组会弄混、
#include<bits/stdc++.h>
const int maxn=1e5+20;
using namespace std;
int first[maxn],tot=0,vis[maxn],dist[maxn],cnt[maxn];
int n,m,s;
struct edge
{
int to;
int nxt;
int w;
}e[maxn];
void add(int a,int b,int c)
{
tot++;
e[tot].nxt=first[a];
e[tot].to=b;
e[tot].w=c;
first[a]=tot;
}
queue<int> q;
int spfa()
{
while(!q.empty())
{
int x=q.front();
q.pop();
vis[x]=0;
if(cnt[x]>n) return -1;
for(int i=first[x];i;i=e[i].nxt)
{
int y=e[i].to,w=e[i].w;
if(dist[y]>dist[x]+w)
{
if(!vis[y]) q.push(y),vis[y]=1;
dist[y]=dist[x]+w;
cnt[y]=cnt[x]+1;
}
}
}
return 1;
}
int main()
{
cin>>n>>m>>s;
for(int i=1;i<=m;i++)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
}
for(int i=1;i<=n;i++)
{
q.push(i);
vis[i]=1;
}
if(spfa()==-1)
{
printf("-1");
return 0;
}
memset(vis,0,sizeof vis);
memset(dist,0x3f,sizeof dist);
dist[s]=0;
vis[s]=1;
q.push(s);
spfa();
for(int i=1;i<=n;i++)
{
if(dist[i]==0x3f3f3f3f) printf("NoPath\n");
// else if(i==s) printf("0\n");
else printf("%d\n",dist[i]);
}
return 0;
}
多源最短路
最小生成树
prim
prim算法和地接特斯拉特别像,众所周知dij是每次都找到一个中继点来更新其他点,而中继点是选择距离原点最近的点。而prim算法是维护一个联通的点集,每次选择距离点集最近的一个点加入点集,直到所有点都加入点集为止。
我们需要不断维护每个点到点集的距离,不过由于我们每次都只将一个点加入点集,因此只需要用这个点更新其他没加入的点的距离即可
稠密图适用,稠密图用邻接矩阵储存,储存时取最小值。
由于每个点都要加入集合,因此我们一开始任意选一个点加入,然后先通过它把跟它相连的点距离更新一遍,再循环n-1次,每次找一个距离最近的点更新其他点
#include<bits/stdc++.h>
const int maxn=4e5+20;
using namespace std;
int n,m;
int e[5005][5005],dist[maxn];
int vis[maxn],res=0;//表示一个点是否在集合中
int prim()
{
memset(dist,0x3f,sizeof dist);
dist[1]=0;
vis[1]=1;
for(int i=1;i<=n;i++) dist[i]=min(dist[i],e[1][i]);
for(int i=2;i<=n;i++)
{
int t=0,minn=0x3f3f3f3f;
for(int j=1;j<=n;j++)//找出要更新的点
{
if(vis[j]) continue;
if(dist[j]<minn) minn=dist[j],t=j;
// cout<<dist[j]<<endl;
}
if(minn==0x3f3f3f3f) return -1;
res+=minn;
vis[t]=1;
dist[t]=0;
for(int j=1;j<=n;j++)
{
dist[j]=min(dist[j],dist[t]+e[t][j]);
}
}
return res;
}
int main()
{
cin>>n>>m;
memset(e,0x3f,sizeof e);
for(int i=1;i<=m;i++)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
e[a][b]=min(e[a][b],c);
e[b][a]=min(e[b][a],c);
}
if(prim()==-1) printf("orz");
else printf("%d",res);
return 0;
}
kruskal
思想非常简洁,将所有边从小到大排序,维护一个并查集,对于每个边如果某个点没加入并查集就合并并加上边长,直到所有点都加入
#include<bits/stdc++.h>
const int maxn=4e5+20;
using namespace std;
int n,m;
int tot=0;
struct edge
{
int from;
int to;
int w;
}e[maxn];
void add(int a,int b,int c)
{
tot++;
e[tot].from=a;
e[tot].to=b;
e[tot].w=c;
}
bool cmp(edge a,edge b)
{
return a.w<b.w;
}
int bin[maxn];
int baba(int x)
{
while(x!=bin[x]) x=bin[x]=bin[bin[x]];
return bin[x];
}
void badd(int x,int y)
{
bin[baba(x)]=baba(y);
}
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
bin[i]=i;
for(int i=1;i<=m;i++)
{
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
add(a,b,c);
add(b,a,c);
}
sort(e+1,e+tot+1,cmp);
int res=0,sum=1;
for(int i=1;i<=tot;i++)
{
int x=e[i].from,y=e[i].to;
if(baba(x)!=baba(y))
{
badd(x,y);
res+=e[i].w;
sum++;
}
}
if(sum<n) printf("orz");
else cout<<res;
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人