复习:基础数据结构
先占个坑,把前面的更完了就来更这个
栈
单调栈
单调栈是一种很神奇的数据结构,假如我们令其单调递增,那么对于一段序列中的每个ai,我们都能知道左边第一个比他小的数aj,如果我们反着跑一遍就能知道右边第一个比它小的数。同样的,也可以求第一个比它大的。
原理其实很简单,我们维护栈中的单调性,例如我们维护栈内升序,那么当栈顶大于等于当前ai时,令栈顶不断弹出直至小于等于即可。
acwing131 直方图中最大的矩形

对于这道题,我一开始想的是模拟每个点为区间左端点和右端点,然后用这个点的值乘上区间长度更新答案。并且我也是这么写的。后果就是wa了好几发,然后看数据我才意识到答案值并不一定是端点值乘上区间长度。原因在于会漏情况。比如一个序列为2 1 2,答案值是1* 3=3,但1作为端点时并不能更新答案。也就是说最优解不一定出在端点值为最低点的情况
正确做法是枚举每个点作为最低点更新答案。然后找到左边和右边第一个小于它的数,计算区间长度然后相乘。在一个点为最低点的时候最优解一定是乘上这个区间,因此可以能保证答案正确性。
写程序过程中踩的坑:
1.栈中值是放下标因此不能直接比较要用a[s.top()]
2.在更新r数组的时候因为是直接把l数组那句话粘贴过去改了一下没改全,当右边不存在小于ai的数时r更新为n+1
3.while(!s1.empty()&&a[s1.top()]>=a[i])这句话中判断是否为空必须放前面先进行判断,否则为空的时候会无法正常运行
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int maxn=1e5+10;
stack <int> s1;
stack <int> s2;
int a[maxn],l[maxn],r[maxn];
signed main()
{
int n;
while(scanf("%lld",&n)&&n!=0)
{
int ans=-1;
for(int i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
while(!s1.empty()&&a[s1.top()]>=a[i]) s1.pop();
l[i]=s1.empty()?0:s1.top();
// cout<<s1.size()<<endl;
//printf("%lld %lld\n",s1.top(),a[i]);
s1.push(i);
}
for(int i=n;i>=1;i--)
{
while(!s2.empty()&&a[s2.top()]>=a[i]) s2.pop();
r[i]=s2.empty()?n+1:s2.top();
s2.push(i);
}
for(int i=1;i<=n;i++)
{
ans=max(ans,(r[i]-l[i]-1)*a[i]);
}
printf("%ld\n",ans);
while(!s1.empty()) s1.pop();
while(!s2.empty()) s2.pop();
}
return 0;
}
acwing1413 矩形牛棚

也是求最大面积,相当于上道题的进化版本。首先读题,要求最大矩形,比较容易想到的做法是先前缀和被破坏的土地数量,然后枚举左上和右下端点看是否可行。这样的复杂度是四次方的,然而本题数据3k,需要降低到平方才能过。
然后我们想到这道题和上道题其实是有诸多相似之处的,上一道题是O(n)的做法,然后我们来想想这两题的差别
最明显的差别就是上道题只给了一维数组,本题是二维数组。然后就不难想到把它拆成n个一维数组来做。也就是说我们每次选择一行作为下边界来寻找答案,一共寻找n行即可。
上一题对于每一列都有一个高度,本题也是有的,不过没那么显然。每个点的高度就是它能够向上延伸多少并且不碰到被破坏的方格。比如被破坏的方格高度是0,它下面的方格高度是1,再下面是2.....以此类推
然后建一个二维数组储存每个点的高度,然后我们就按上道题的做法一列列做即可。
不过这个二维数组的初始化我一开始写错了卡了好久。我用的是首先将被破坏的点以及它下面的点全部更新,但这样会出错,比如我更新(5,1)=0,然后我接下来会更新(5,2)=1,但如果(5,2)也是被破坏的点并且在后面的话,就会判断出错,需要多加一个判断条件。但这样写起来无比麻烦
比较简单的是在输入完后遍历二维数组,如果一个点是被破坏的就设置为0,否则为它上面的点+1.
这题卡stl,加了O2优化才过说是
#pragma GCC optimize(1)
#pragma GCC optimize(2)
#pragma GCC optimize(3,"Ofast","inline")
#include<bits/stdc++.h>
using namespace std;
int R,c,p;
int m[3005][3005];
int l[3005],r[3005];
int ans=-1;
void ser(int a)//第i行的的最大值
{
stack <int> s1,s2;
for(int i=1;i<=c;i++)
{
while(!s1.empty()&&m[a][s1.top()]>=m[a][i]) s1.pop();
l[i]=s1.empty()?0:s1.top();
s1.push(i);
}
for(int i=c;i>=1;i--)
{
while(!s2.empty()&&m[a][s2.top()]>=m[a][i]) s2.pop();
r[i]=s2.empty()?c+1:s2.top();
s2.push(i);
}
for(int i=1;i<=c;i++)
{
ans=max(ans,(r[i]-l[i]-1)*m[a][i]);
}
}
int main()
{
memset(m,0,sizeof m);
cin>>R>>c>>p;
for(int i=1;i<=p;i++)
{
int a,b;
cin>>a>>b;
m[a][b]=-1;
}
for(int i=1;i<=R;i++)
for(int j=1;j<=c;j++)
if(m[i][j]==-1) m[i][j]=0;
else m[i][j]=m[i-1][j]+1;
for(int i=1;i<=R;i++)
ser(i);
cout<<ans;
return 0;
}
链表
单调队列
单调队列我觉得和单调栈是有一定的相似之处的。他们都可以维护自己内部的数据有序。不同的是单调栈只能从栈顶出,而单调队列是可以从两边出。单调栈一般用于找某个数左边/右边第一个比它大/小的数字,而单调队列主要用于解决滑动窗口类问题,什么是滑动窗口?
洛谷p1886滑动窗口

简单来说就是求固定长度的区间最值问题。基本思想是维护一个单调队列,如果要求最小值就按照升序排列,因为如果一个数是区间内的最小值就肯定在队头,但如果一个数是最大值却不一定在队尾(因为可能会被后面的比它小的值挤下来,小的数加入时要挤出所有比它大的数)。同理维护最小值时是降序。我们保证了队列里的最大值和最小值,但还没有解决区间长度的问题。每次滑动时都可能会需要删除一个元素,我们只需要判断队头是否需要被删除即可。如果队头的下标经过计算正好是要挤出去的那个下标就挤出去,如果不是的话说明之前已经被小的数挤出去过了。这里使用stl的deque来维护队列,支持双端插入和挤出,缺点是常数比较大(但我真的不想手写)
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e6+10;
deque <int> s1,s2;//s1存最小s2存最大s1升序s2降序
int ans1[maxn],ans2[maxn],a[maxn];
int n,k;
int main()
{
cin>>n>>k;
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
if(s1.front()==i-k&&i!=k) s1.pop_front();
if(s2.front()==i-k&&i!=k) s2.pop_front();
while(!s1.empty()&&a[s1.back()]>=a[i]) s1.pop_back();
while(!s2.empty()&&a[s2.back()]<=a[i]) s2.pop_back();
s1.push_back(i);
s2.push_back(i);
if(i>=k)
{
ans1[i-k+1]=a[s1.front()];
ans2[i-k+1]=a[s2.front()];
}
}
for(int i=1;i<=n-k+1;i++)
printf("%d ",ans1[i]);
cout<<endl;
for(int i=1;i<=n-k+1;i++)
printf("%d ",ans2[i]);
return 0;
}
acwing4964 子矩阵

二维加强版的滑动窗口,让你求矩阵中固定长宽的矩形的最大值和最小值。不过这个比单调栈的二维化药麻烦一些,单调栈的只需要跑n遍就够了,但这个要横着跑一遍再竖着跑一遍,才能达到n方的复杂度。
不过优点是这个比二维单调栈那个好想一些。很容易就能想到对每行做一次单调队列求最值,但要求求整个矩形最小值,我本来想着求完最值竖着一个个遍历求,但仔细一想这样复杂度最坏有n三次方,遂作罢。然后想到再对横着跑出来的结果竖着跑一遍单调队列,那样就能求出整个面积的最小值
#include<bits/stdc++.h>
#define mod 998244353
#define int long long
using namespace std;
//用数组m1[i][j]来表示对于以第i行第j列为起点的k个数里的最大值 ,m2表示最小值
const int maxn=1e3+10;
int m1[maxn][maxn],m2[maxn][maxn];
int a[maxn][maxn];
int n,m,r,k,ans=0;
int maxx[maxn][maxn],minn[maxn][maxn];
//表示以ij为左上角端点的矩形的最大值和最小值
void work(int x)//处理第x行
{
deque <int> s1,s2;//s1升序存最小值,s2降序最大值
for(int i=1;i<=m;i++)
{
if(!s1.empty()&&s1.front()==i-k) s1.pop_front();
if(!s2.empty()&&s2.front()==i-k) s2.pop_front();
while(!s1.empty()&&a[x][i]<=a[x][s1.back()]) s1.pop_back();
while(!s2.empty()&&a[x][i]>=a[x][s2.back()]) s2.pop_back();
s1.push_back(i);
s2.push_back(i);
if(i>=k) m1[x][i-k+1]=a[x][s1.front()];
if(i>=k) m2[x][i-k+1]=a[x][s2.front()];
}
}
void work2(int x)//处理第x列
{
deque <int> s1,s2;//s1升序最小值,s2降序最大值
for(int i=1;i<=n;i++)
{
if(!s1.empty()&&s1.front()==i-r) s1.pop_front();
if(!s2.empty()&&s2.front()==i-r) s2.pop_front();
while(!s1.empty()&&m1[i][x]<=m1[s1.back()][x]) s1.pop_back();
while(!s2.empty()&&m2[i][x]>=m2[s2.back()][x]) s2.pop_back();
s1.push_back(i);
s2.push_back(i);
if(i>=r)
{
minn[i-r+1][x]=m1[s1.front()][x];
maxx[i-r+1][x]=m2[s2.front()][x];
}
}
}
signed main()
{
scanf("%lld%lld%lld%lld",&n,&m,&r,&k);
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
scanf("%lld",&a[i][j]);
}
}
for(int i=1;i<=n;i++)
{
work(i);
}
for(int i=1;i<=m;i++)
work2(i);
for(int i=1;i<=n-r+1;i++)
{
for(int j=1;j<=m-k+1;j++)
{
ans=(ans+maxx[i][j]%mod*minn[i][j]%mod)%mod;
}
}
printf("%ld",ans);
return 0;
}
字符串
KMP
我回来更kmp啦!
kmp是一种字符串算法,用于求在给定两个字符串a,b,求b在a中出现的次数(或位置等)
kmp的思想略有些抽象,不过它的想法解释起来倒也不是那么困难。
简单来说就是当我们匹配到某一位不同时,b字符串并不会推倒重来,而是利用之前匹配的信息继续和a串匹配
比如b串是ababb,a串是abababb,我们会发现前四位都一样,我们设i是a中匹配的字符,j是b中匹配的字符
当i和j都跳到5,我们发现不一样,而kmp的做法就是将
abababb
ababb
变为

简单来说,我们发现第五位a和b不同,但我们发现a中第三位和第四位的ab,与b中第一位第二位的ab相同,可以直接进行继承,然后从b的第三位开始比较。
那么这么神奇的操作是怎么实现的呢?
答案是通过一个nxt数组,用来记录当j处于b的每一位时应该怎么往前跳。比如ababb的nxt[4]就是2(首位字母下标为1),我们这里用b[j+1]表示正在比对的字符,若b[j+1]不同,则j跳到nxt[j],即nxt[4]=2,然后b[j+1]即b[3]继续和a进行比对。
我们该如何实现这个数组?
要解决这个问题,我们先来考虑一下为何能让它在跳跃的同时保证正确性。
还是abababb和ababb这个例子,我们之所以可以让ababb实现跳跃,是因为我们在匹配完abab以后,发现a中的目前匹配到的第二个ab和b中的第一个ab完全相同,我们因此可以直接替换掉,省去一个个比对的时间。
简单来说,在我们已经匹配成功的子串abab中,后缀ab与前缀ab完全相同。那有人要问了,欸我们不是在拿a串和b串进行比对吗为什么这里就是单独一个abab串了呢,答案是因为这部分是完全重合的公有部分,所以完全可以单独拎出来进行讨论。
言归正传,我们现在知道对于一个子串,它的一定长度的后缀和前缀完全相同那我们就可以实现跳跃,那么我们记录nxt[i]为从b1到bi形成的子串中最长的和后缀相同的前缀末尾的下标。比如abab中nxt[4]就是2,因为后缀ab和前缀ab相同,而nxt[3]是1,因为在子串aba中前缀a和后缀a相同,前缀末尾下标为1.
然后我们具体落实到代码怎么写呢
for(int i=2,j=0;i<=len2;i++)
{
while(j&&s2[j+1]!=s2[i]) j=nxt[j];
if(s2[j+1]==s2[i]) j++;
nxt[i]=j;
}
nxt[1]肯定是0,所以我们从nxt[2]开始找,len2是b串的长度。当当前i与j匹配时令前缀末尾j++,否则将j一直往前跳匹配直到匹配成功或是跳到0表示一个都配不上。此时若匹配成功,说明b的以j结尾的前缀和以i结尾的后缀完全相同。此时就可以更新nxt[i]=j,并且如果匹配不上,nxt[i]会=0
然后对b自身进行匹配后再和a进行匹配,思路基本一致,不过在j达到b的长度时说明匹配成功,需要输出结果。
完整代码如下
#include<bits/stdc++.h>
using namespace std;
string s1,s2;
const int maxn=1e6+5;
int nxt[maxn];
int len1,len2;
void pre()
{
for(int i=2,j=0;i<=len2;i++)
{
while(j&&s2[j+1]!=s2[i]) j=nxt[j];
if(s2[j+1]==s2[i]) j++;
nxt[i]=j;
}
}
int main()
{
cin>>s1>>s2;
len1=s1.size(),len2=s2.size();
s1=' '+s1,s2=' '+s2;
pre();
for(int i=1,j=0;i<=len1;i++)
{
while(j&&s2[j+1]!=s1[i]) j=nxt[j];
if(s2[j+1]==s1[i]) j++;
if(j==len2)
{
printf("%d\n",i-j+1);
}
}
for(int i=1;i<=len2;i++)
{
printf("%d ",nxt[i]);
}
return 0;
}
洛谷P4391 [BOI2009] Radio Transmission 无线传输

求一个字符串的最小循环节,保证至少重复两次。当这个字符串只有正好两个循环节时字符串的最长共同前后缀没有交集,答案就是共同前后缀的长度
而其他情况下最长的共同前后缀一定会存在交集
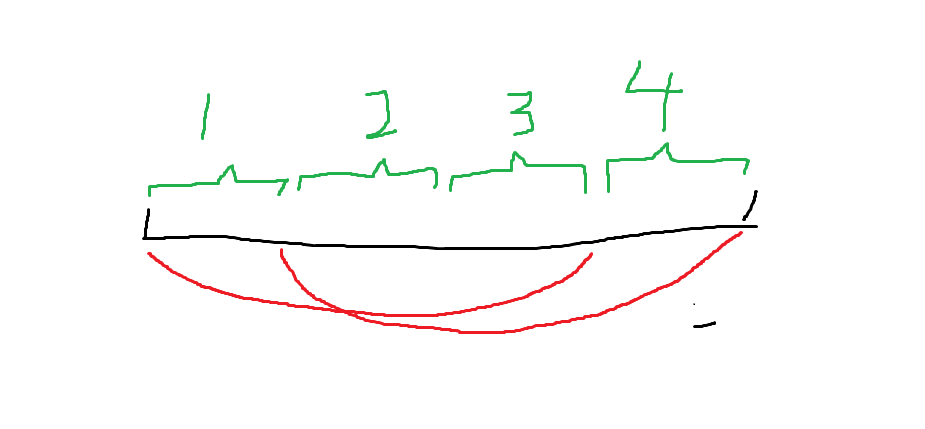
假如这是字符串,,123区域是最长公共前缀,234是后缀,则他们重合了23区域。由于123和234是完全相同的,所以1作为前缀的一开始的区域,和2作为后缀的一开始的区域是完全相同的。那么123的第二个区域2和234的第二个区域3也是相同的。同理3和4也是相同的,因此1== 2== 3==4,中间的循环节可以更长,也就是说循环节就是1这一部分,或者4这一部分,而这个长度就是字符串长度减去最长共同前后缀的长度。
代码如下
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e6+10;
int nxt[maxn];
int main()
{
int l;
cin>>l;
string s;
cin>>s;
int len=s.size();
s=" "+s;
for(int i=2,j=0;i<=len;i++)
{
while(j&&s[i]!=s[j+1]) j=nxt[j];
if(s[i]==s[j+1])
{
j++;
nxt[i]=j;
}
}
cout<<l-nxt[l];
return 0;
}
字典树
字符串哈希
哈希
并查集
并查集说简单点,就是合并同类项。当你想把一堆东西分类,此时不妨考虑并查集
并查集的主要思想是将同一类的数据都由这一类中的某一个来代表。比如我如果将1到10都归为了一类,那我可能用1来代表这个集合。我们可以将这样的节点叫做祖先节点。我们在判断两个节点是否属于统一集合时只需要判断他们的祖先节点是否相同即可。
并查集的实现主要依靠两个函数和一个数组,分别是合并函数(将两个集合合并),查找函数(查找一个节点的祖宗节点)以及父节点数组(记录一个节点的父节点)
我们规定bin[x]代表x的父节点,在初始情况下每个节点的父节点都是它本身。然后用find()函数表示某个节点的祖宗节点,add()函数表示合并
然后我们现在想要将两个节点或者区间合并,我们可以写如下代码
void add(int x,int y)
{ bin[find(x)]=find[y]; }
我们将两个节点的祖宗节点合并,由此实现整个区间合并。
然后是查找函数
int find(int x)
{
while(x!=bin[x]) x=bin[x]=bin[bin[x]];
return x;
}
这里需要注意的是这里使用了路径压缩的方法,如果直接x=bin[x]结束的话多次查找时复杂度有可能会高的吓人,因为每次都要遍历一遍。但如果在查找的同时赋值,最后就会将所有节点与祖宗节点直接连接,查找也会变成O(1)
洛谷P2078 朋友

比板子稍微难了一点,其实就是看两个集合元素数量的最小绝对值
不过比较值得一提的地方是由于女性的编号都是负数,所以在建立并查集时会自然而然的想到给把-1变成n+1,-2变成n+2,通过这样的思路我们可以无缝衔接至下一个题目的思想。
#include<bits/stdc++.h>
#define ll unsigned long long
using namespace std;
const int maxn=2e4+10;
int n,m,p,q,fa[maxn],size[maxn];
int zuzong(int x)
{
if(x!=fa[x]) fa[x]=zuzong(fa[x]);
return fa[x];
}
void add(int x,int y)
{
size[zuzong(y)]+=size[zuzong(x)];
fa[zuzong(x)]=zuzong(y);
}
int main()
{
cin>>n>>m>>p>>q;
for(int i=1;i<=n+m+1;i++) fa[i]=i,size[i]=1;
while(p--)
{
int x,y;
scanf("%d%d",&x,&y);
if(zuzong(x)==zuzong(y)) continue;
add(zuzong(x),zuzong(y));
}
while(q--)
{
int x,y;
scanf("%d%d",&x,&y);
x=abs(x)+n,y=abs(y)+n;
if(zuzong(x)==zuzong(y)) continue;
add(zuzong(x),zuzong(y));
}
printf("%d",min(size[zuzong(1)],size[zuzong(1+n)]));
return 0;
}
洛谷 P1892 [BOI2003] 团伙

和上一题不同的是,这次对于一个人而言分为朋友和敌人两种。解决方案是对于一个编号为i的人,如果一个人是他的朋友,则和i合并,若是敌人则和i+n合并。这样他的敌人都会被合并到一个集合。但我们看到敌人的敌人是朋友,说明如果a和b是敌人,那么a的敌人就是b的朋友,b的敌人就是a的朋友,所以我们要将b+n和a合并,另外一边同理。
#include<bits/stdc++.h>
#define ll unsigned long long
using namespace std;
const int maxn=2e4+10;
int n,m,p,q,fa[maxn];
bool flag[maxn];
int zuzong(int x)
{
if(x!=fa[x]) fa[x]=zuzong(fa[x]);
return fa[x];
}
void add(int x,int y)
{
fa[zuzong(x)]=zuzong(y);
}
int main()
{
cin>>n>>m;
for(int i=1;i<=n*2+1;i++) fa[i]=i;
while(m--)
{
int p,q;
char c[1];
scanf("%s%d%d",c,&p,&q);
if(c[0]=='F') add(p,q);
else
{
add(p,q+n);
add(p+n,q);
}
}
int ans=0;
for(int i=1;i<=n;i++)
{
if(!flag[zuzong(i)]) ans++,flag[zuzong(i)]=1;
}
cout<<ans;
return 0;
}
acwing 528. 奶酪


这个数据量我觉得也可以建图跑?把所有底部点标记为起点顶部点标记为终点,相交或相切就连一条边,然后跑
但确实有点多此一举了,毕竟建图也是n方
此题并查集解法,就是n方枚举点看是否联通,联通则放到一个集合。同时维护两个数组high和low表示集合的最高点和最低点。最后扫一遍看是否有集合的范围覆盖了整块奶酪即可
算距离的函数写的特别弱智是因为我一开始是用ull写的
然后调了半天发现find函数写错了
#include<bits/stdc++.h>
#define int long long
using namespace std;
int t;
const int maxn=1050;
int x[maxn],y[maxn],z[maxn],bin[maxn],high[maxn],low[maxn];
double dist(int a,int b)
{
int aa=max(x[a],x[b])-min(x[a],x[b]);
int bb=max(y[a],y[b])-min(y[a],y[b]);
int cc=max(z[a],z[b])-min(z[a],z[b]);
// printf("%lld %lld\n",a,b);
//printf("%lld %lld %lld %lf\n\n",aa,bb,cc,sqrt(double(aa*aa+bb*bb+cc*cc)));
return sqrt(double(aa*aa+bb*bb+cc*cc));
}
int baba(int x)
{
while(x!=bin[x]) x=bin[x]=baba(bin[x]);
return bin[x];
}
void add(int a,int b)
{
int c=baba(a),d=baba(b);
high[d]=max(high[d],high[c]);
low[d]=min(low[d],low[c]);
bin[c]=d;
}
signed main()
{
cin>>t;
while(t--)
{
int n,h,r;
cin>>n>>h>>r;
for(int i=1;i<=n;i++)
{
scanf("%lld%lld%lld",&x[i],&y[i],&z[i]);
bin[i]=i;
high[i]=z[i]+r;
low[i]=z[i]-r;
}
for(int i=1;i<=n;i++)
{
for(int j=i+1;j<=n;j++)
{
if(baba(i)==baba(j)) continue;
if(dist(i,j)<=2*r)
{
add(i,j);
// cout<<i<<' '<<j<<' '<<dist(i,j)<<endl;
}
}
}
//cout<<baba(1)<<' '<<baba(2)<<endl;
for(int i=1;i<=n;i++)
{
int now=baba(i);
if(high[now]>=h&&low[now]<=0)
{
printf("Yes\n");
break;
}
if(i==n) printf("No\n");
}
}
return 0;
}
