
python之struct详解
python之struct详解
用处
- 按照指定格式将Python数据转换为字符串,该字符串为字节流,如网络传输时,不能传输int,此时先将int转化为字节流,然后再发送;
- 按照指定格式将字节流转换为Python指定的数据类型;
- 处理二进制数据,如果用struct来处理文件的话,需要用’wb’,’rb’以二进制(字节流)写,读的方式来处理文件;
- 处理c语言中的结构体;
struct模块中的函数
| 函数 | return | explain |
|---|---|---|
| pack(fmt,v1,v2…) | string | 按照给定的格式(fmt),把数据转换成字符串(字节流),并将该字符串返回. |
| pack_into(fmt,buffer,offset,v1,v2…) | None | 按照给定的格式(fmt),将数据转换成字符串(字节流),并将字节流写入以offset开始的buffer中.(buffer为可写的缓冲区,可用array模块) |
| unpack(fmt,v1,v2…..) | tuple | 按照给定的格式(fmt)解析字节流,并返回解析结果 |
| pack_from(fmt,buffer,offset) | tuple | 按照给定的格式(fmt)解析以offset开始的缓冲区,并返回解析结果 |
| calcsize(fmt) | size of fmt | 计算给定的格式(fmt)占用多少字节的内存,注意对齐方式 |
格式化字符串
当打包或者解包的时,需要按照特定的方式来打包或者解包.该方式就是格式化字符串,它指定了数据类型,除此之外,还有用于控制字节顺序、大小和对齐方式的特殊字符.
对齐方式
为了同c中的结构体交换数据,还要考虑c或c++编译器使用了字节对齐,通常是以4个字节为单位的32位系统,故而struct根据本地机器字节顺序转换.可以用格式中的第一个字符来改变对齐方式.定义如下
| Character | Byte order | Size | Alignment |
|---|---|---|---|
| @(默认) | 本机 | 本机 | 本机,凑够4字节 |
| = | 本机 | 标准 | none,按原字节数 |
| < | 小端 | 标准 | none,按原字节数 |
| > | 大端 | 标准 | none,按原字节数 |
| ! | network(大端) | 标准 | none,按原字节数 |
如果不懂大小端,见大小端参考网址.
格式符
| 格式符 | C语言类型 | Python类型 | Standard size |
|---|---|---|---|
| x | pad byte(填充字节) | no value | |
| c | char | string of length 1 | 1 |
| b | signed char | integer | 1 |
| B | unsigned char | integer | 1 |
| ? | _Bool | bool | 1 |
| h | short | integer | 2 |
| H | unsigned short | integer | 2 |
| i | int | integer | 4 |
| I(大写的i) | unsigned int | integer | 4 |
| l(小写的L) | long | integer | 4 |
| L | unsigned long | long | 4 |
| q | long long | long | 8 |
| Q | unsigned long long | long | 8 |
| f | float | float | 4 |
| d | double | float | 8 |
| s | char[] | string | |
| p | char[] | string | |
| P | void * | long |
注- -!
- _Bool在C99中定义,如果没有这个类型,则将这个类型视为char,一个字节;
- q和Q只适用于64位机器;
- 每个格式前可以有一个数字,表示这个类型的个数,如s格式表示一定长度的字符串,4s表示长度为4的字符串;4i表示四个int;
- P用来转换一个指针,其长度和计算机相关;
- f和d的长度和计算机相关;
进制转化:
# 获取用户输入十进制数
dec = int(input("输入数字:"))
print("十进制数为:", dec)
print("转换为二进制为:", bin(dec))
print("转换为八进制为:", oct(dec))
print("转换为十六进制为:", hex(dec))
- 16进制转10进制: int('0x10', 16) ==> 16
Python没有专门处理字节的数据类型。但由于b'str'可以表示字节,所以,字节数组=二进制str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
在Python中,比方说要把一个32位无符号整数变成字节,也就是4个长度的bytes,你得配合位运算符这么写:
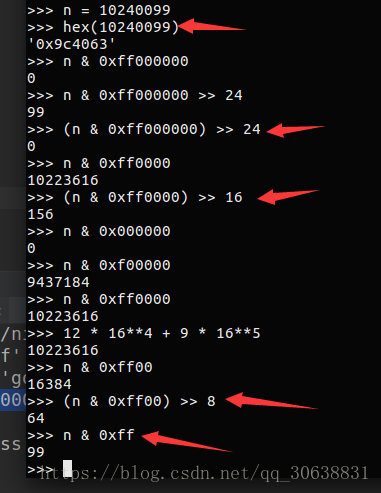
-
-
-
-
-
-
-
-
b'\x00\x9c@c'
非常麻烦。如果换成浮点数就无能为力了。
好在Python提供了一个struct模块来解决bytes和其他二进制数据类型的转换。
struct的pack函数把任意数据类型变成bytes:
-
-
-
b'\x00\x9c@c'
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。

struct
准确地讲,Python没有专门处理字节的数据类型。但由于b'str'可以表示字节,所以,字节数组=二进制str。而在C语言中,我们可以很方便地用struct、union来处理字节,以及字节和int,float的转换。
在Python中,比方说要把一个32位无符号整数变成字节,也就是4个长度的bytes,你得配合位运算符这么写:
-
-
-
-
-
-
-
-
b'\x00\x9c@c'
非常麻烦。如果换成浮点数就无能为力了。
好在Python提供了一个struct模块来解决bytes和其他二进制数据类型的转换。
struct的pack函数把任意数据类型变成bytes:
-
-
-
b'\x00\x9c@c'
pack的第一个参数是处理指令,'>I'的意思是:
>表示字节顺序是big-endian,也就是网络序,I表示4字节无符号整数。
后面的参数个数要和处理指令一致。
unpack把bytes变成相应的数据类型:
-
-
(4042322160, 32896)
根据>IH的说明,后面的bytes依次变为I:4字节无符号整数和H:2字节无符号整数。
所以,尽管Python不适合编写底层操作字节流的代码,但在对性能要求不高的地方,利用struct就方便多了。
struct模块定义的数据类型可以参考Python官方文档:
https://docs.python.org/3/library/struct.html#format-characters
Windows的位图文件(.bmp)是一种非常简单的文件格式,我们来用struct分析一下。
首先找一个bmp文件,没有的话用“画图”画一个。
读入前30个字节来分析:
>>> s = b'\x42\x4d\x38\x8c\x0a\x00\x00\x00\x00\x00\x36\x00\x00\x00\x28\x00\x00\x00\x80\x02\x00\x00\x68\x01\x00\x00\x01\x00\x18\x00'
BMP格式采用小端方式存储数据,文件头的结构按顺序如下:
两个字节:'BM'表示Windows位图,'BA'表示OS/2位图;一个4字节整数:表示位图大小;一个4字节整数:保留位,始终为0;一个4字节整数:实际图像的偏移量;一个4字节整数:Header的字节数;一个4字节整数:图像宽度;一个4字节整数:图像高度;一个2字节整数:始终为1;一个2字节整数:颜色数。
所以,组合起来用unpack读取:
-
-
(b'B', b'M', 691256, 0, 54, 40, 640, 360, 1, 24)
-
结果显示,b'B'、b'M'说明是Windows位图,位图大小为640x360,颜色数为24。
请编写一个bmpinfo.py,可以检查任意文件是否是位图文件,如果是,打印出图片大小和颜色数。
-
# -*- coding: utf-8 -*-
-
-
import base64,struct
-
-
bmp_data = base64.b64decode('Qk1oAgAAAAAAADYAAAAoAAAAHAAAAAoAAAABABAAAAAAADICAAASCwAAEgsAAAAAAAAAAAAA/3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9/AHwAfAB8AHwAfAB8AHwAfP9//3//fwB8AHwAfAB8/3//f/9/AHwAfAB8AHz/f/9//3//f/9//38AfAB8AHwAfAB8AHwAfAB8AHz/f/9//38AfAB8/3//f/9//3//fwB8AHz/f/9//3//f/9//3//f/9/AHwAfP9//3//f/9/AHwAfP9//3//fwB8AHz/f/9//3//f/9/AHwAfP9//3//f/9//3//f/9//38AfAB8AHwAfAB8AHwAfP9//3//f/9/AHwAfP9//3//f/9//38AfAB8/3//f/9//3//f/9//3//fwB8AHwAfAB8AHwAfAB8/3//f/9//38AfAB8/3//f/9//3//fwB8AHz/f/9//3//f/9//3//f/9/AHwAfP9//3//f/9/AHwAfP9//3//fwB8AHz/f/9/AHz/f/9/AHwAfP9//38AfP9//3//f/9/AHwAfAB8AHwAfAB8AHwAfAB8/3//f/9/AHwAfP9//38AfAB8AHwAfAB8AHwAfAB8/3//f/9//38AfAB8AHwAfAB8AHwAfAB8/3//f/9/AHwAfAB8AHz/fwB8AHwAfAB8AHwAfAB8AHz/f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//3//f/9//38AAA==')
-
-
-
def bmp_info(data):
-
-
str = struct.unpack('<ccIIIIIIHH',data[:30]) #bytes类也有切片方法
-
-
-
if str[0]==b'B' and str[1]==b'M':
-
-
print("这是位图文件")
-
-
return {
-
'width': str[-4],
-
'height': str[-3],
-
'color': str[-1]
-
}
-
-
else:
-
-
print("这不是位图文件")
-
-
-
if __name__ == '__main__':
-
bmp_info(bmp_data)
-
print('ok')
-
-
>>> from struct import *
>>> pack('hhl', 1, 2, 3)
b'\x00\x01\x00\x02\x00\x00\x00\x03'
>>> unpack('hhl', b'\x00\x01\x00\x02\x00\x00\x00\x03')
(1, 2, 3)
>>> calcsize('hhl')
8
Unpacked fields can be named by assigning them to variables or by wrapping the result in a named tuple:
>>> record = b'raymond \x32\x12\x08\x01\x08'
>>> name, serialnum, school, gradelevel = unpack('<10sHHb', record)
>>> from collections import namedtuple
>>> Student = namedtuple('Student', 'name serialnum school gradelevel')
>>> Student._make(unpack('<10sHHb', record))
Student(name=b'raymond ', serialnum=4658, school=264, gradelevel=8)
The ordering of format characters may have an impact on size since the padding needed to satisfy alignment requirements is different:
>>> pack('ci', b'*', 0x12131415)
b'*\x00\x00\x00\x12\x13\x14\x15'
>>> pack('ic', 0x12131415, b'*')
b'\x12\x13\x14\x15*'
>>> calcsize('ci')
8
>>> calcsize('ic')
5
The following format 'llh0l' specifies two pad bytes at the end, assuming longs are aligned on 4-byte boundaries:
>>> pack('llh0l', 1, 2, 3)
b'\x00\x00\x00\x01\x00\x00\x00\x02\x00\x03\x00\x00'
示例
现在我们有了格式字符串,也知道了封装函数,那现在先通过一两个例子看一看。
例一:比如有一个报文头部在C语言中是这样定义的
struct header
{
unsigned short usType;
char[4] acTag;
unsigned int uiVersion;
unsigned int uiLength;
};
在C语言对将该结构体封装到一块缓存中是很简单的,可以使用memcpy()实现。在Python中,使用struct就需要这样:
str = struct.pack('B4sII', 0x04, 'aaaa', 0x01, 0x0e)
'B4sII' ------ 有一个unsigned short、char[4], 2个unsigned int。其中s之前的数字说明了字符串的大小 。
type, tag, version, length = struct.unpack('B4sll', str)
class struct.Struct(format)
返回一个struct对象(结构体,参考C)。
该对象可以根据格式化字符串的格式来读写二进制数据。
第一个参数(格式化字符串)可以指定字节的顺序。
默认是根据系统来确定,也提供自定义的方式,只需要在前面加上特定字符即可:
struct.Struct('>I4sf')
特定字符对照表附件有。
常见方法和属性:
方法
pack(v1, v2, …)返回一个字节流对象。
按照fmt(格式化字符串)的格式来打包参数v1,v2,...。
通俗的说就是:
首先将不同类型的数据对象放在一个“组”中(比如元组(1,'good',1.22)),
然后打包(“组”转换为字节流对象),最后再解包(将字节流对象转换为“组”)。
pack_into(buffer, offset, v1, v2, …)
根据格式字符串fmt包装值v1,v2,...,并将打包的字节写入从位置偏移开始的可写缓冲buffer。 请注意,offset是必需的参数。
unpack_from(buffer, offset=0)
根据格式字符串fmt,从位置偏移开始从缓冲区解包。 结果是一个元组,即使它只包含一个项目。 缓冲区的大小(以字节为单位,减去偏移量)必须至少为格式所需的大小,如calcsize()所反映的。
属性
format
格式化字符串。
size
结构体的大小。
实例:
1.通常的打包和解包
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# -*- coding: utf-8 -*-"""打包和解包"""import structimport binasciivalues = (1, b'good', 1.22) #查看格式化对照表可知,字符串必须为字节流类型。s = struct.Struct('I4sf')packed_data = s.pack(*values)unpacked_data = s.unpack(packed_data) print('Original values:', values)print('Format string :', s.format)print('Uses :', s.size, 'bytes')print('Packed Value :', binascii.hexlify(packed_data))print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data) |
结果:
Original values: (1, b'good', 1.22) Format string : b'I4sf' Uses : 12 bytes Packed Value : b'01000000676f6f64f6289c3f' Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295) [Finished in 0.1s]
说明:
首先将数据对象放在了一个元组中,然后创建一个Struct对象,并使用pack()方法打包该元组;最后解包返回该元组。
这里使用到了binascii.hexlify(data)函数。
binascii.hexlify(data)
返回字节流的十六进制字节流。
|
1
2
3
4
5
6
7
|
>>> a = 'hello'>>> b = a.encode()>>> bb'hello'>>> c = binascii.hexlify(b)>>> cb'68656c6c6f' |
2.使用buffer来进行打包和解包
使用通常的方式来打包和解包会造成内存的浪费,所以python提供了buffer的方式:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# -*- coding: utf-8 -*-"""通过buffer方式打包和解包"""import structimport binasciiimport ctypesvalues = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。s = struct.Struct('I4sf')buff = ctypes.create_string_buffer(s.size)packed_data = s.pack_into(buff,0,*values)unpacked_data = s.unpack_from(buff,0) print('Original values:', values)print('Format string :', s.format)print('buff :', buff)print('Packed Value :', binascii.hexlify(buff))print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data) |
结果:

Original values1: (1, b'good', 1.22) Original values2: (b'hello', True) buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348> Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01' Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295) Unpacked Type : <class 'tuple'> Value: (b'hello', True) [Finished in 0.1s]
说明:
针对buff对象进行打包和解包,避免了内存的浪费。
这里使用到了函数
ctypes.create_string_buffer(init_or_size,size = None)
创建可变字符缓冲区。
返回的对象是c_char的ctypes数组。
init_or_size必须是一个整数,它指定数组的大小,或者用于初始化数组项的字节对象。
3.使用buffer方式来打包多个对象
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# -*- coding: utf-8 -*-"""buffer方式打包和解包多个对象"""import structimport binasciiimport ctypesvalues1 = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。values2 = (b'hello',True)s1 = struct.Struct('I4sf')s2 = struct.Struct('5s?')buff = ctypes.create_string_buffer(s1.size+s2.size)packed_data_s1 = s1.pack_into(buff,0,*values1)packed_data_s2 = s2.pack_into(buff,s1.size,*values2)unpacked_data_s1 = s1.unpack_from(buff,0)unpacked_data_s2 = s2.unpack_from(buff,s1.size) print('Original values1:', values1)print('Original values2:', values2)print('buff :', buff)print('Packed Value :', binascii.hexlify(buff))print('Unpacked Type :', type(unpacked_data_s1), ' Value:', unpacked_data_s1)print('Unpacked Type :', type(unpacked_data_s2), ' Value:', unpacked_data_s2) |
结果:
Original values2: (b'hello', True) buff : <ctypes.c_char_Array_18 object at 0x000000D5A5617348> Packed Value : b'01000000676f6f64f6289c3f68656c6c6f01' Unpacked Type : <class 'tuple'> Value: (1, b'good', 1.2200000286102295) Unpacked Type : <class 'tuple'> Value: (b'hello', True) [Finished in 0.1s]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号