一致性哈希算法在分布缓存中的应用
一、简介
关于一致性哈希算法介绍有许多类似文章,需要把一些理论转为为自己的知识,所以有了这篇文章,本文部分实现也参照了原有的一些方法。
该算法在分布缓存的主机选择中很常用,详见 http://en.wikipedia.org/wiki/Consistent_hashing 。
二、算法诞生缘由
现在许多大型系统都离不开缓存(K/V)(由于高并发等因素照成的数据库压力(或磁盘IO等)超负荷,需要缓存缓解压力),为了获得良好的水平扩展性,
缓存主机互相不通信(如Mencached),通过客户端计算Key而得到数据存放的主机节点,最简单的方式是取模,假如:
----------------------------------------------------------------
现在有3台缓存主机,现在有一个key 为 cks 的数据需要存储:
key = "cks"
hash(key) = 10
10 % 3 = 1 ---> 则代表选择第一台主机存储这个key和对应的value。
缺陷:
假如有一台主机宕机或增加一台主机(必须考虑的情况),取模的算法将导致大量的缓存失效(计算到其他没有缓存该数据的主机),数据库等突然承受巨大负荷,很大可能导致DB服务不可用等。
----------------------------------------------------------------
三、一致性哈希算法原理
该算法需要解决取模方法当增加主机或者宕机时带来的大量缓存抖动问题,要在生产环境中使用,算法需具备以下几个特点:
1. 平衡性 : 指缓存数据尽量平衡分布到所有缓存主机上,有效利用每台主机的空间。
2.
3. 负载均衡 : 每台缓存主机尽量平衡分担压力,即Key的分配比例在这些主机中应趋于平衡。
假如我们把键hash为int类型(32字节),取值范围为 -2^31 到 (2^31-1) , 我们把这些值首尾相连形成一个圆环,如下图:
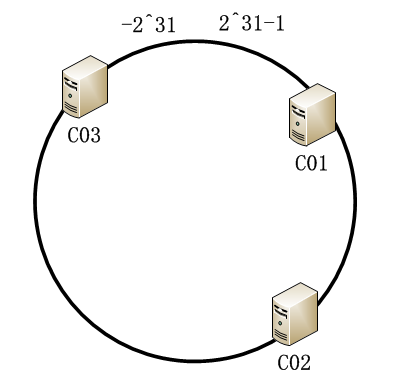
假设现在有3台缓存主机: C01、C02、C03 ,把它们放在环上(通过IP hash,后面实现会介绍),如下图:
假如现在有5个key需要缓存,它们分别为 A,B,C,D,E,假设它们经过hash后分布如下,顺时针找到它们最近的主机,并存储在上面:

假如当新加入节点C04的时候,数据分配如下:
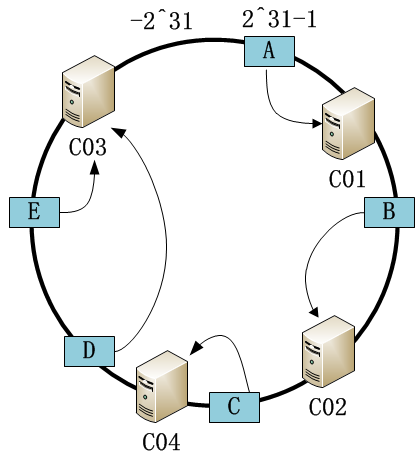
可以发现,只有少量缓存被重新分配的新主机,减少抖动带来的压力。
但同时出现一个问题,数据分布并不尽量均匀(当有大量缓存的时候可以看出来),这时候需要把真实的缓存节点虚拟为多个节点,分布在环上,
当顺时针找到虚拟节点的时候再映射到真实节点,则可以知道数据缓存在哪台主机。
四、算法实现(Java版本)
算法的实现有许多,下面例子仅供参考,实际仍需要考虑其他多个问题:
假设有4主机:
192.168.70.1-5
public class Node { private String ip;
// 代表主机中存放的K/V private ConcurrentMap<Object, Object> map = new ConcurrentHashMap<Object, Object>(); public Node(String ip) { this.ip = ip; } public String getIp() { return ip; } public ConcurrentMap<Object, Object> getMap() { return map; } @Override public String toString() { return ip; } }
下面是一个没有虚拟节点的情况实现方法:
public class ConsistentHash { // -2^31 - (2^31-1) 圆环, 用于存储节点 private final SortedMap<Integer, Node> circle = new TreeMap<Integer, Node>(); private IHash hashIf; public ConsistentHash(IHash hash) { this.hashIf = hash; } public void addNode(Node node) { circle.put(hashIf.hash(node.getIp()), node); } public void removeNode(Node node) { circle.remove(hashIf.hash(node.getIp())); } public Node getNode(Object key) { int hashCode = hashIf.hash(key); if (!circle.containsKey(hashCode)) { // 类似顺时针取得最近的存储节点 SortedMap<Integer, Node> tailMap = circle.tailMap(hashCode); hashCode = tailMap.isEmpty()? circle.firstKey() : tailMap.firstKey(); } return circle.get(hashCode); } }
其中IHash 为散列方法接口,可实现不同的散列方式,下面是一个基于MD5算法得到的int值(还有其他算法):
public interface IHash { int hash(Object key); }
public class MD5HashImpl implements IHash { MessageDigest digest; public MD5HashImpl() throws NoSuchAlgorithmException { digest = MessageDigest.getInstance("MD5"); } @Override public int hash(Object key) { if (key == null) return 0; int h = key.hashCode(); byte[] bytes = new byte[4]; for(int i=3; i>-1; i--) { bytes[i] = (byte)( h>>(i*8) ); } byte[] hashBytes ; synchronized (digest) { hashBytes = digest.digest(bytes); } int result = 0; for (int i=0; i<4; i++) { int idx = i*4; result += (hashBytes[idx + 3]&0xFF << 24) | (hashBytes[idx + 2]&0xFF << 16) | (hashBytes[idx + 1]&0xFF << 8) | (hashBytes[idx + 0]&0xFF); } return result; } }
测试方法如下:
public class ConsistentHashTest { public static void main(String[] args) throws Exception { ConsistentHash cHash = new ConsistentHash(new MD5HashImpl()); // Nodes List<Node> nodes = new ArrayList<Node>(); for (int i=1; i<5; i++) { Node node = new Node("192.168.70." + i); // Fake nodes.add(node); cHash.addNode(node); } Map<String, Set<Integer>> counter = new HashMap<String, Set<Integer>>(); for (Node n : nodes) { counter.put(n.getIp(), new HashSet<Integer>()); } // 随机KEY测试分布情况 Set<Integer> allKeys = new HashSet<Integer>();
Random random = new Random(); int testTimes = 1000000; for (int i=0; i<testTimes; i++) { int randomInt = random.nextInt(); Node node = cHash.getNode(randomInt); Set<Integer> count = counter.get(node.getIp()); count.add(randomInt);
allKeys.add(randomInt); } for (Map.Entry<String, Set<Integer>> entry : counter.entrySet()) { System.out.println(entry.getKey() + "\t" + entry.getValue().size() + "\t" + (entry.getValue().size()*100/(float)allKeys.size()) + "%"); } } }
测试结果(每次运行的实际结果不同):
IP Count Percent
--------------------------------------
192.168.70.1 216845 21.6845%
192.168.70.4 7207 0.7207%
192.168.70.2 749929 74.9929%
192.168.70.3 25891 2.5891%
-------------------------------------
这结果表示每个节点分配并不均匀,需要把每个节点虚拟为多个节点,ConsistentHash 算法更改如下:
public class ConsistentHash { // -2^31 - (2^31-1) 圆环, 用于存储节点 private final SortedMap<Integer, Node> circle = new TreeMap<Integer, Node>(); private IHash hashIf; private int virtualNum; // 把实际节点虚拟为多个节点 public ConsistentHash(IHash hash, int virtualNum) { this.hashIf = hash; this.virtualNum = virtualNum; } public void addNode(Node node) { for (int i=0; i<virtualNum; i++) { circle.put(hashIf.hash(i + node.getIp()), node); } } public void removeNode(Node node) { for (int i=0; i<virtualNum; i++) { circle.remove(hashIf.hash(i + node.getIp())); } } public Node getNode(Object key) { int hashCode = hashIf.hash(key); if (!circle.containsKey(hashCode)) { // 类似顺时针取得最近的存储节点 SortedMap<Integer, Node> tailMap = circle.tailMap(hashCode); hashCode = tailMap.isEmpty()? circle.firstKey() : tailMap.firstKey(); } return circle.get(hashCode); } }
只需要在测试函数里面修改:
// 这里每个节点虚拟为120个,根据实际情况考虑修改合理的值,虚拟数量少则导致部分不均匀,数量大则导致树的查找效率降低,两者需要权衡。
ConsistentHash cHash = new ConsistentHash(new MD5HashImpl(), 120);
--------------------------- 添加虚拟节点后的分布情况 ----------------------------------------
IP Count Percent
192.168.70.1 277916 27.7916%
192.168.70.4 251437 25.1437%
192.168.70.2 226645 22.6645%
192.168.70.3 243871 24.3871%
------------------------------------------------------------------------------------------------
下面再模拟宕机和新增主机情况下面的缓存失效率:
public class HitFailureTest { public static void main(String[] args) throws Exception { ConsistentHash cHash = new ConsistentHash(new MD5HashImpl(), 120); List<Node> nodes = new ArrayList<Node>(); for (int i=1; i<5; i++) { Node node = new Node("192.168.70." + i); // Fake nodes.add(node); cHash.addNode(node); } Set<Integer> allKeys = new HashSet<Integer>(); Random random = new Random(); int testTimes = 1000000; for (int i=0; i<testTimes; i++) { int randomInt = random.nextInt(); cHash.getNode(randomInt).getMap().put(randomInt, 0); allKeys.add(randomInt); } // 移除主机序号 int removeIdx = 1; cHash.removeNode(nodes.get(removeIdx)); int failureCount = 0; for (Integer key : allKeys) { if(!cHash.getNode(key).getMap().containsKey(key)) { failureCount ++; } } System.out.println("FailureCount \t Percent"); System.out.println(failureCount + "\t" + (failureCount*100/(float)allKeys.size()) + "%"); } }
结果如下:
FailureCount Percent
231669 23.16975%
结果说明具有比较低的缓存失效率,当主机越多则失效率越低。
五、总结
一致性哈希算法能比较好地保证分布缓存的可用性与扩展性,目前大多缓存客户端都基于这方式实现(考虑的因素比上面多很多,如性能问题等),
上面实现方式在宕机或新增机器时候小部分缓存丢失,但有些情况下缓存不允许丢失,则需要做缓存备份,有两种方式:
1. 修改客户端,保证数据被缓存到两台不同机器,任一一台宕机数据仍能找到。
2. 由缓存服务端实现备份,采用无固定主节点(当主节点失效时重新选举最老的机器作为主节点)模式,节点互备份。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号