PostgreSQL HA cluster java端实现数据库读写分离
前面文章构建了PostgreSQL HA集群,那问题来了:如何在Java程序端实现对数据库的读操作和写操作分离?
即:主库负责处理事务性的增删改操作,从库负责处理查询操作,从而实现读写分离的操作。通过读写分离,就可以降低单台数据库的访问压力, 提高访问效率,也可以避免单机故障。
在项目中,如何通过Java 代码来完成读写分离呢,如何在执行SELECT的时候查询从库,而在执行INSERT、UPDATE、DELETE的时候,操作主库呢?这个时候,我们就需要介绍一个新的组件: ShardingJDBC。
1.关于ShardingJDBC
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
Sharding-JDBC具有以下几个特点:
| 适用于任何基于JDBC的ORM框架 |
JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。 |
|
支持任何第三方的数据库连接池 |
DBCP, C3P0, BoneCP, Druid, HikariCP等。 |
|
支持任意实现JDBC规范的数据库 |
目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。 |
2、pom 依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
接下来我们就做一个小案例,首先我们要把我们MySQL主从复制配置,教程在开篇已经提供给各位了。
3、入门案例
首先我们要在项目pom 文件中引入依赖。


<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency>
然后在yml 文件中配置数据源。
# 配置服务器
server:
port: 8081 # 配置端口号
spring:
shardingsphere:
datasource:
names:
master,slave # 数据源的名称master,slave是可以随意定义的,不是固定的
# write主数据源:for save,update,delete
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://129.184.13.*:5000/postgres
username: postgres
password: postgres
# read从数据源:only for select
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://129.184.13.*:5001/postgres
username: postgres
password: postgres
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询 如果有多个从库,从库的负载均衡策略
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master #主库数据库名称
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave #从库数据库名称
props:
sql:
show: true #开启SQL显示,默认false
main:
allow-bean-definition-overriding: true # 允许如果当前项目中存在同名的bean,后定义的bean会覆盖先定义的
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
mybatis:
#config-location: classpath:mybatis/mybatis-config.xml #指定全局配置文件位置
mapper-locations: classpath:mapper/*.xml #指定sql映射文件位置
configuration:
map-underscore-to-camel-case: true #设置为列名允许映射驼峰命名法
4、测试
我们使用shardingjdbc来实现读写分离,直接通过上述简单的配置就可以了。
配置完毕之后,我们就可以重启服务,通过postman来访问controller的方法,来完成用户信息的增删改查,我们可以通过debug及日志的方式来查看每一次执行增删改查操作,使用的是哪个数据源,连接的是哪个数据库。
4.1 增加
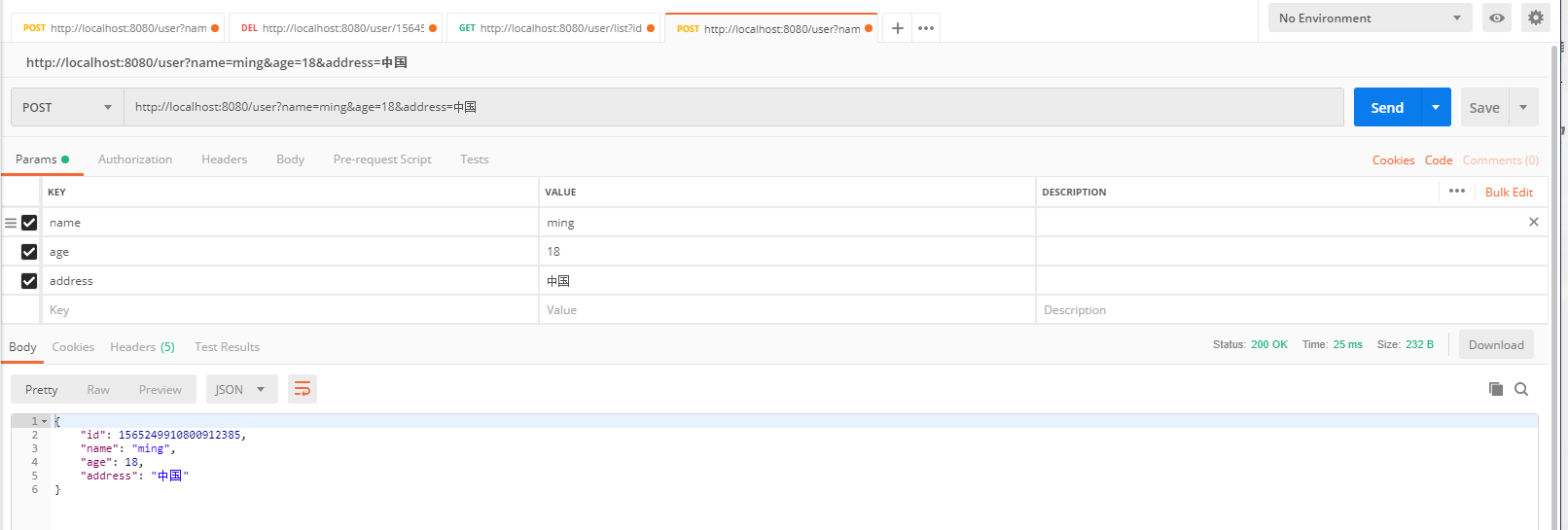
从控制台输入日志看,它确实做的是主库master

4.2 删除
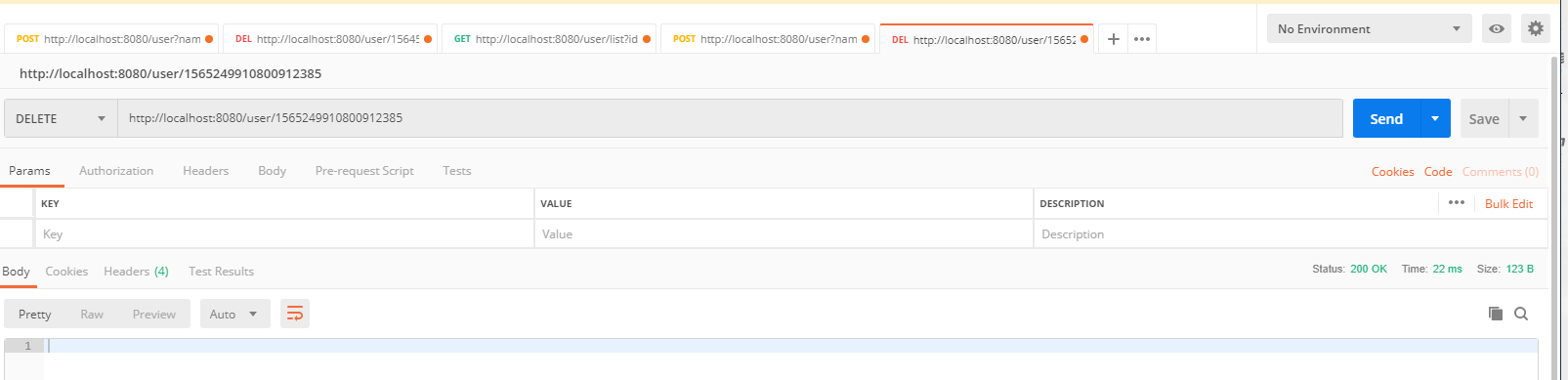
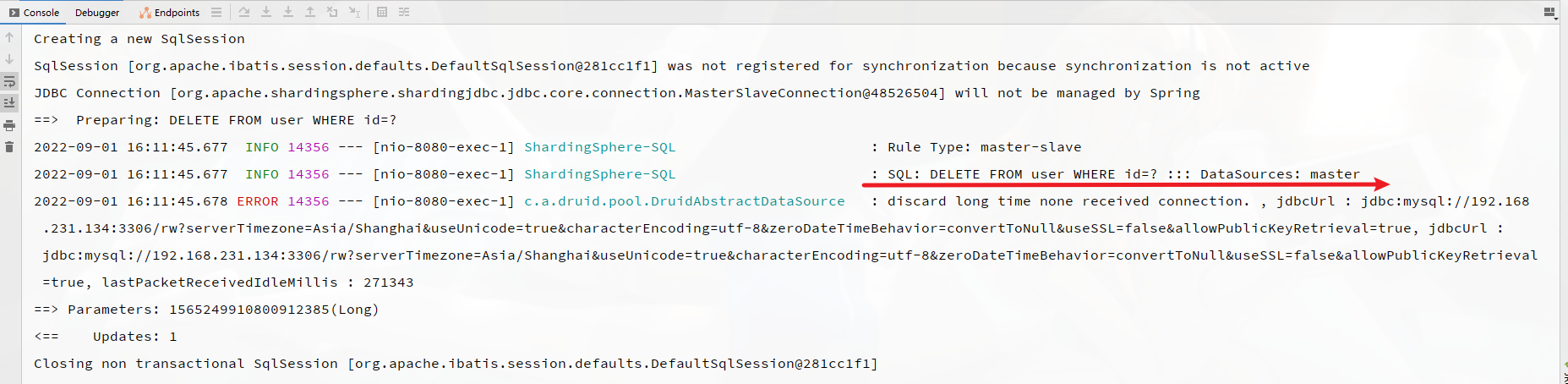
控制台输出日志,可以看到操作master主库:
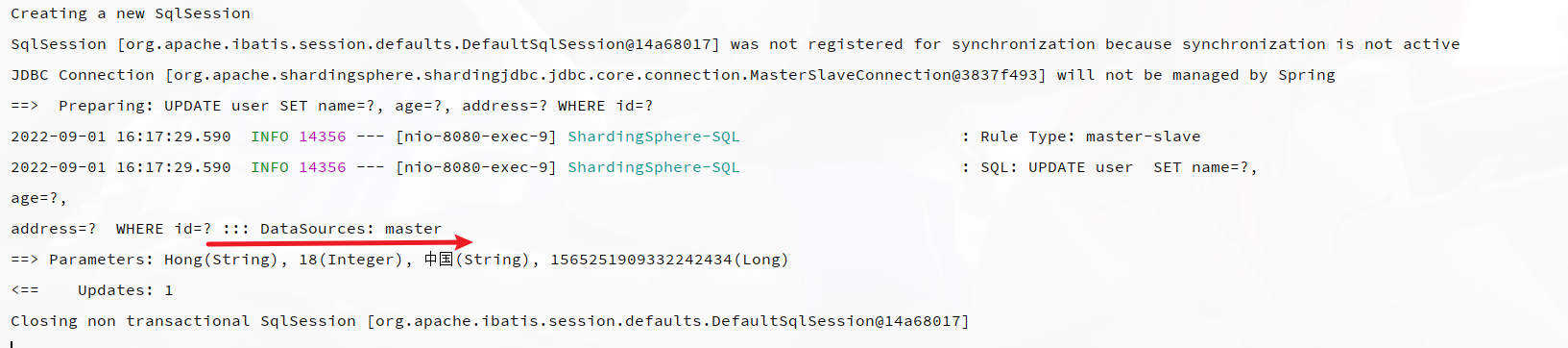
4.3 修改
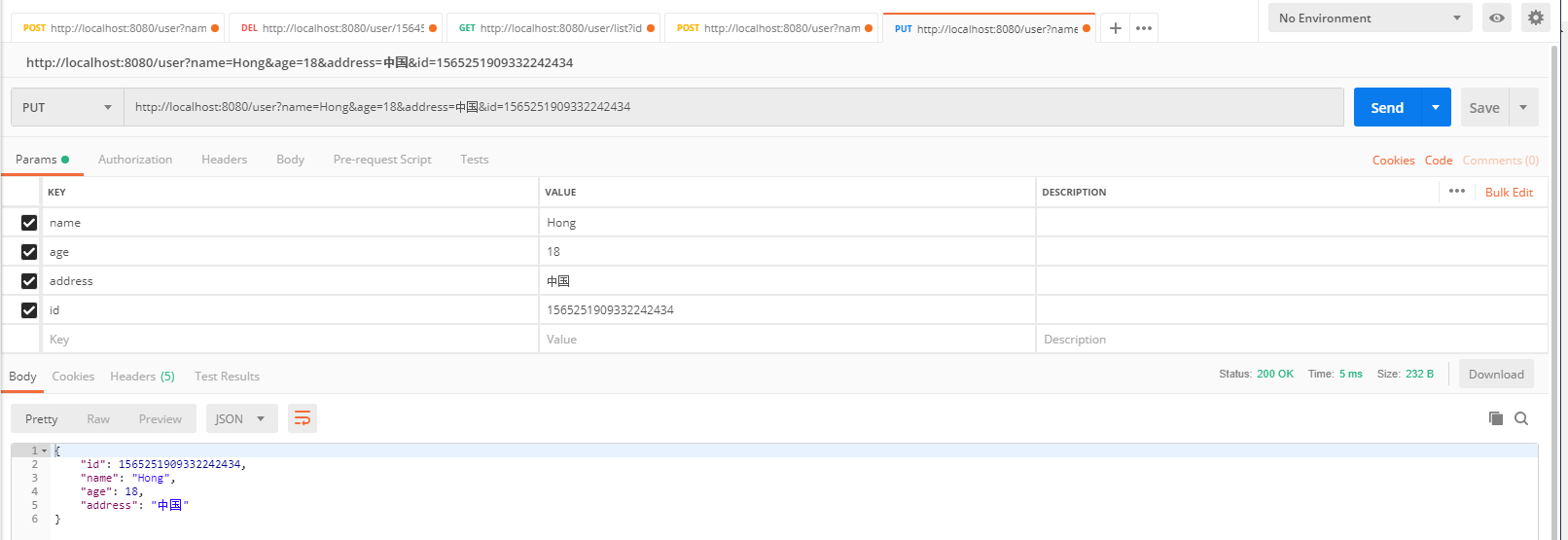
控制台输出日志,可以看到操作master主库:
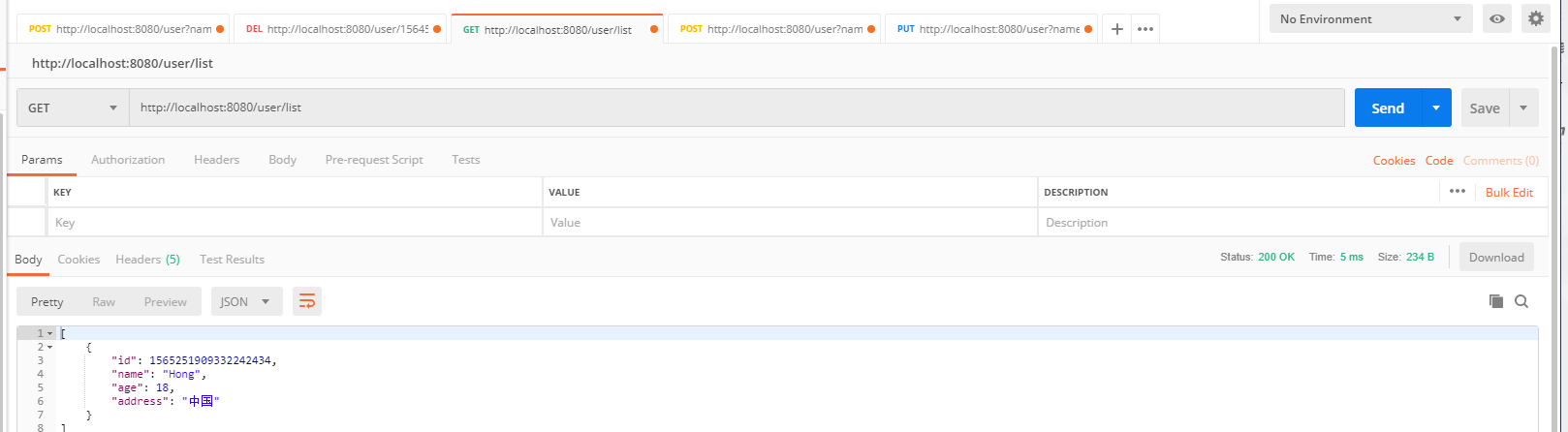
4.4 查询
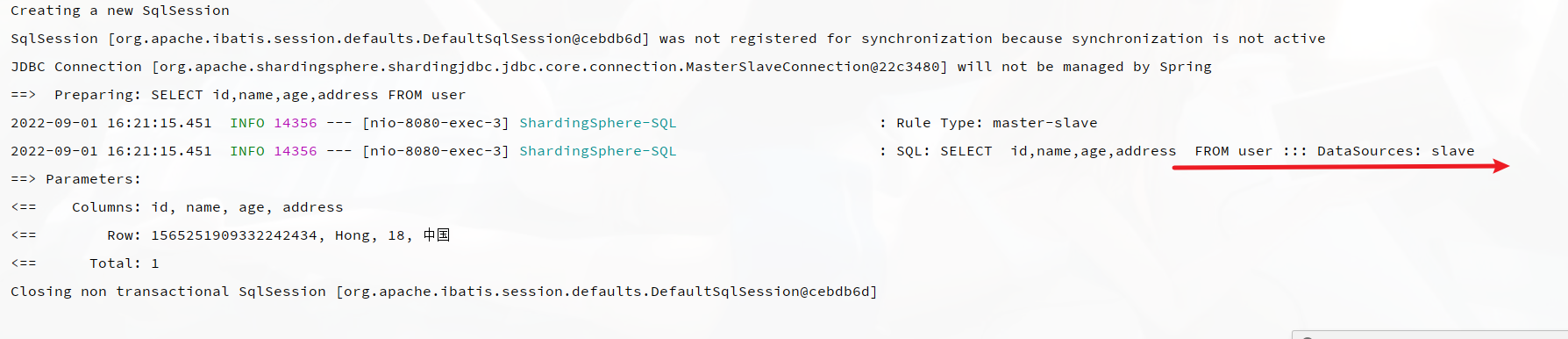
控制台输出日志,可以看到操作slave从库:
ps:
Sharding-JDBC官方地址
转载自:https://blog.csdn.net/weixin_53041251/article/details/126985331

 浙公网安备 33010602011771号
浙公网安备 33010602011771号