如何使用大数据--如何进行数据分析?以电影票房预测为例
广播、电视、电影和影视录音制作业包含广播、电视、电影和影视节目制作、电影和影视节目发行以及电影放映等细分行业。目前国内电影票房的日趋火热,2010年到现在电影票房近乎呈指数增长,理念观影人数以及电影银幕数数量同样呈近乎指数的增长趋势,而由于中国人口基数大,每10万人拥有的屏幕数(2块左右)仍远低于美国的14.9块。在这样的大趋势下,电影票房预测分析顺应而生。电影票房预测分析有助于考察电影本身特质对票房的主要影响因素,在一定程度上预测电影票房,为投资方在初期提供决策,为拍摄方在电影相关细节方面给出合理化建议。做电影票房预测分析回答的核心问题只有一个:如何拍出票房可能更高的电影。
数据文件说明:数据文件名为:film.csv。该数据记录了2011年到2013年票房1千万以上的所有电影的相关数据,每个观测为一部电影,共273部电影。因变量就是电影票房,自变量包含两大部分:影片自身属性和导演演员相关属性,其中影片自身属性包括影片类型、影片IP属性、上映时间以及宣传方,导演演员属性包括导演名字、年代、第几部作品、获奖情况、导演是否转型、两个主演名字及对应的主演百度指数。
该案例分析主要包含四个步骤:
1.数据读入,读入常见的csv格式数据
2.数据清洗,主要处理缺失值,使分类变量更具直观的描述性
3.对数据进行基本的描述性和探索性分析,主要用到箱线图,观察电影票房在各分类变量条件下的关系,得到初步的关联概念,初步确定未来的研究方向
4.使用多元线性回归进行推断和预测分析,得到系数并且进行初步的观察和解释,并且运用模型对新变量进行预测
进入正题:
一,R读入csv格式数据
1.启动Rstudio
2.使用setwd()函数设置工作目录,将数据文件拷贝至工作目录下
3.清空当前全局环境中存储的所有变量,释放内存空间
4.使用read.csv读取数据,设置相应的参数,这里我们设置表头为真,不将字符串自动转化为因子向量,并且将读取的数据赋值给自定义的对象a。
5.查看读入的数据对象a。

二,数据清洗
对缺失值进行处理根据之后描述性分析、探索性分析及建模需求,对数据进行合理的转化和处理,使得数据更具解释性。去除带缺失值的行采用函数对变量进行计算生成新的变量。(因子变量标签转换,生成新的因子变量)
1.启动Rstudio
2.读取数据film.csv
3.查看所有变量的summary

4.去除缺失值

5.将票房按照个人定义的区间划分,生成新的分类变量,便于之后观察

6.自定义一个新的函数,将月份变量重新按照档期分类,将分类变量生成自定义标签的因子变量,新的函数同样可以帮助日后处理新的格式完全相同的数据时使用

7.对数据集使用自定义函数并且查看前三行确认修改结果

8.保存数据到film1.csv,boxbar.csv
三,描述性和探索性分析
主要涉及到将连续变量生成分类变量的cut函数,去除缺失值的na.omit函数,以及生成因子的factor函数。基本的数据描述分析包括描述性数据分析和探索性数据分析,描述性分析的目标主要在于描述数据集,而探索性分析的目标主要是在描述的基础上发现新的关联或者是未知的关系。通过描述性、探索性统计得到票房的分布情况,以及各影响因素对票房的影响。
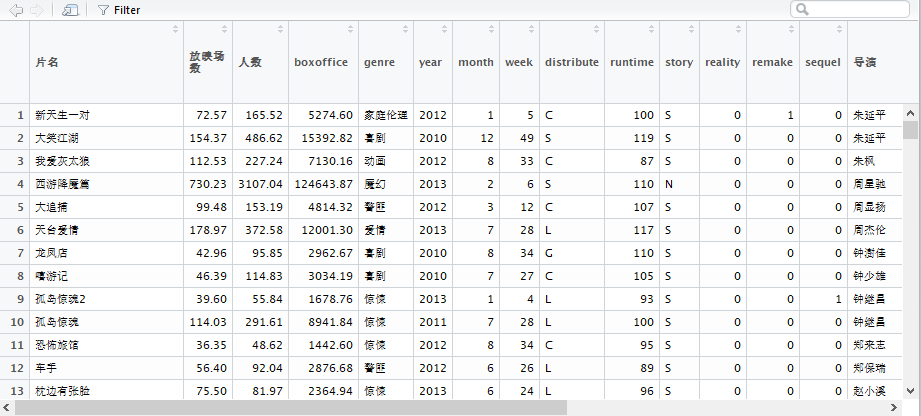
barplot(boxbar$Freq,names.arg=boxbar$Var1,col="dodgerblue",xlab="票房(万元)",ylab="频数")
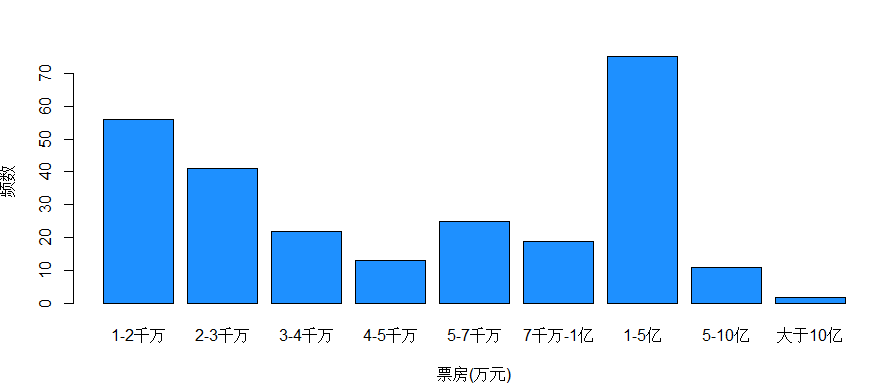
找到最高票房
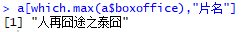
找到最低票房
从图中可见10-13年亿元票房俱乐部是一个坎儿,10亿票房俱乐部还有《西游降魔篇》
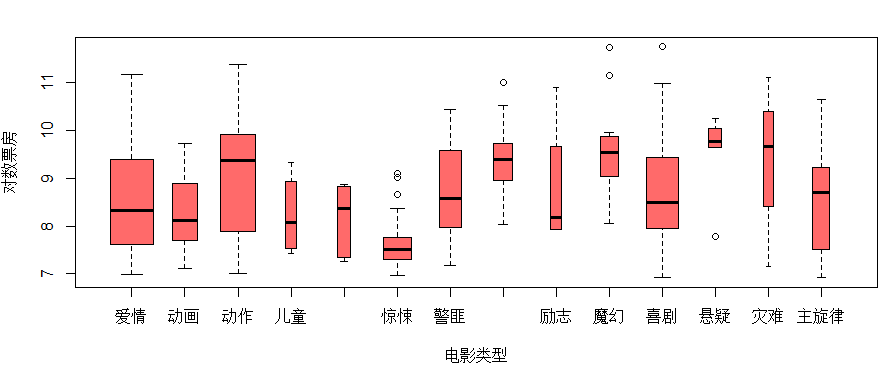
观察不同电影类型的对数票房boxplot(log(boxoffice)~genre,xlab="电影类型",data=a,col="indianred1",ylab="对数票房",varwidth=T)
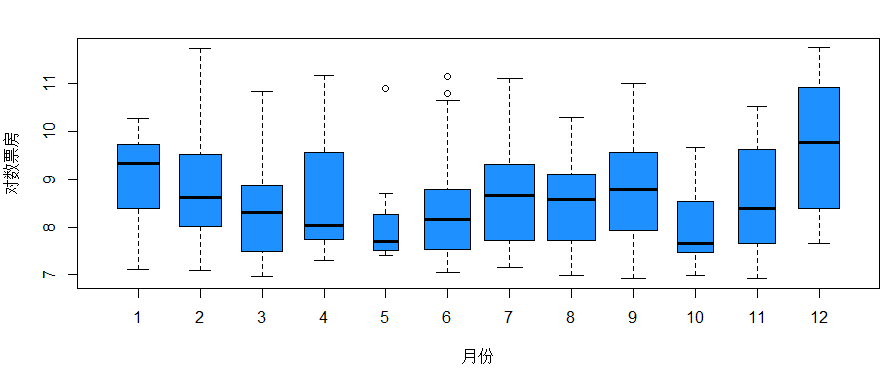
观察不同月份的对数票房分布boxplot(log(boxoffice)~month,xlab="月份",data=a,col="dodgerblue",ylab="对数票房",varwidth=T)
观察不同档期的对数票房分布boxplot(log(boxoffice)~dangqi,xlab="档期",data=a,col="yellow",ylab="对数票房",varwidth=T)
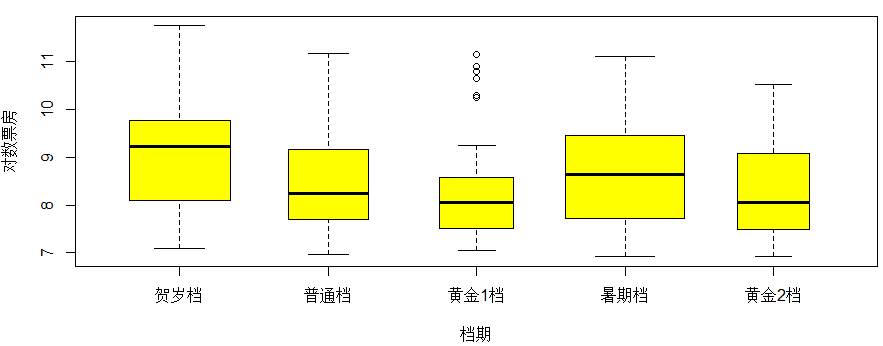
从知识点2中的清洗代码可知:贺岁档对应12-2月,普通档对应3-4月,黄金1档对应5-6月,暑期档对应7-9月,黄金2档对应10-11月
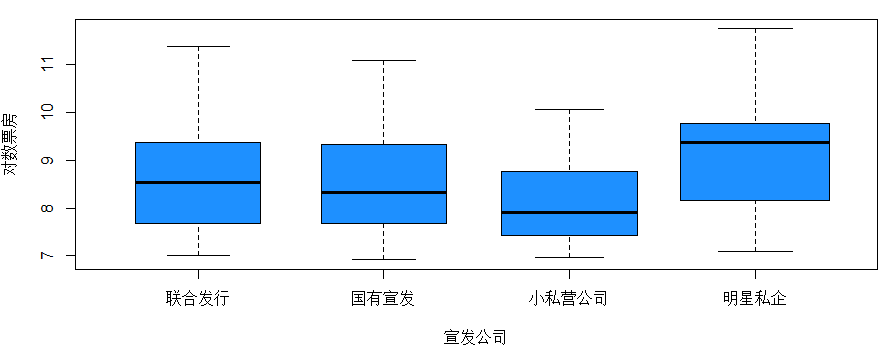
观察不同宣发公司对对数票房的影响boxplot(log(boxoffice)~distribute,xlab="宣发公司",data=a,col="dodgerblue",ylab="对数票房",varwidth=T)
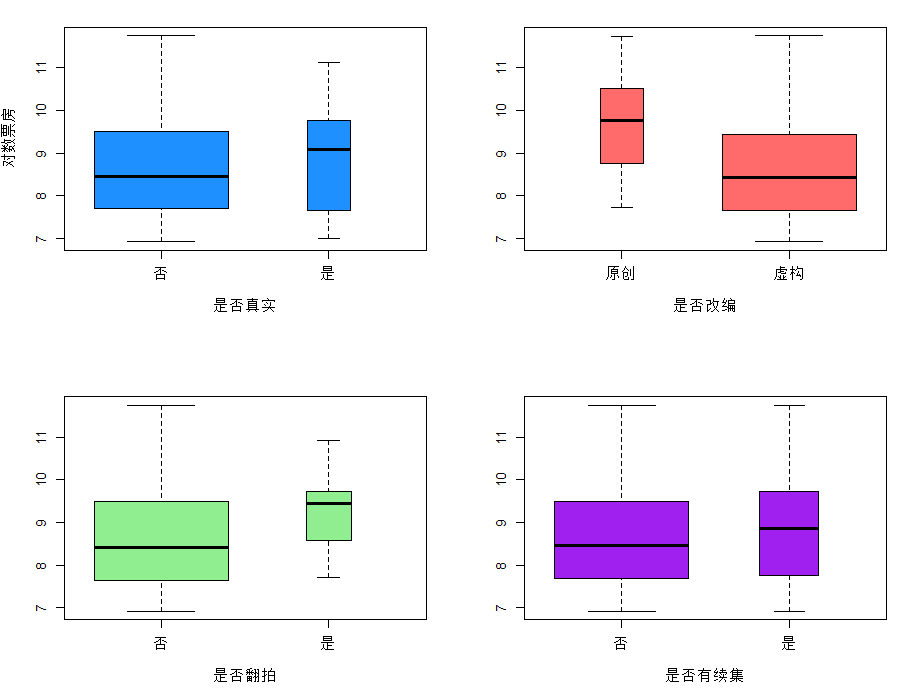
观察不同IP因素对对数票房的影响

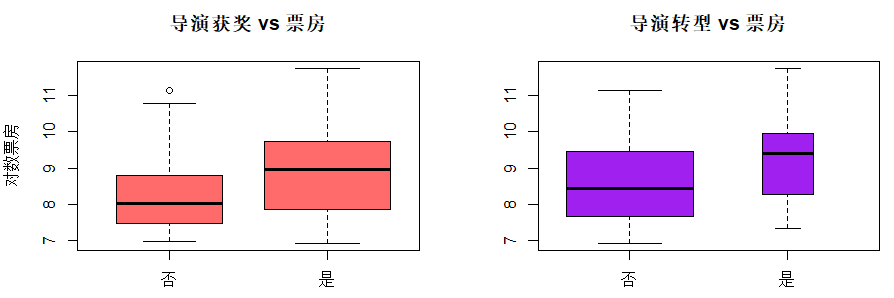
观察导演是否获奖和导演是否转型对票房的影响par(mfrow=c(1,2)) boxplot(log(boxoffice)~导演得奖情况,data=a,col=c("indianred1"), ylab="对数票房",xlab="",main="导演获奖 vs 票房",varwidth=T)boxplot(log(boxoffice)~导演是否转型,data=a,col=c("purple"), ylab="",xlab="",main="导演转型 vs 票房",varwidth=T) par(mfrow=c(1,1))
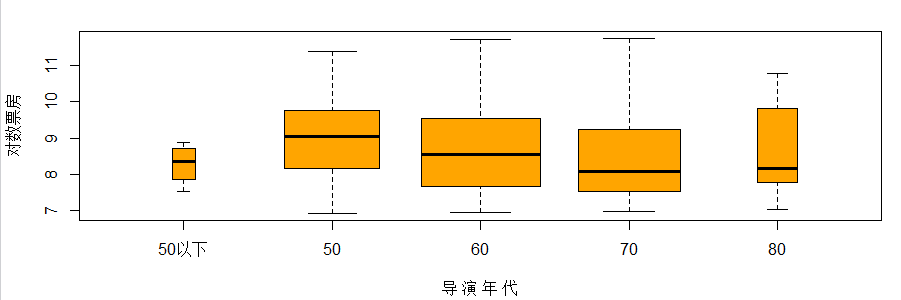
观察不同导演年代对对数票房的影响这里将30和40年代的导演统一归到50年代以下
得到若干影响因素和对数票房的分类箱线图,方便直观的观察各因素对票房的影响。描述性分析和探索性分析都是直观的通过图形来描述和探索变量之间的关系,本知识点大多数图形用箱线图表现出各影响因素对电影票房的影响,箱线图的宽度是此分类下的电影数量,所以这里用一维箱线图表现出了三维的数据,更加的直观简便。
四,用多元线性回归进行推断和预测分析
使用多元线性回归进行推断和预测分析得到系数并且进行初步的观察和解释运用模型对新变量进行预测
1.读取数据,进行回归分析
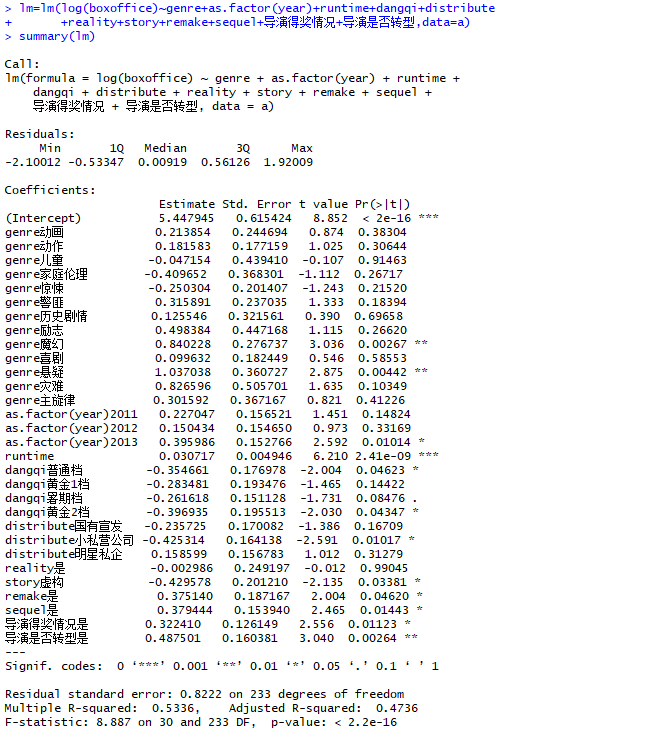
结果分析:R-squared: 0.5336,Adjusted R-squared: 0.4736。可见预测性一般。仅具备一定的参考价值。模型总结(显著性水平选择0.05):1.对比爱情片,魔幻片的票房平均高84%,悬疑片高104%2.电影时长每增加1分钟,票房增长3.1%3.对比贺岁档(12月-2月),普通档(3月-4月)票房平均降低35.5%,黄金2档低39.7%4.对比联合企业,选择小私营公司做宣发票房平均降低42.5%5.虚构故事比原创票房低43%,翻拍电影票房增高37.5%,电影拍续集票房提高37.9%。6.得过奖的导演比没有得过奖的票房提高32.2%,由演员转型的导演票房提高48.8%7.运用模型对新变量进行预测
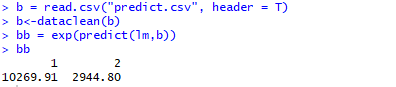
预测准确率偏低,原因可能是多方面的:数据选取逻辑不清晰,导致数据真实性不强回归模型解释力度不够
影响票房的主要因素有:影片类型、宣发团队、IP因素、档期、导演投资选材建议:选择魔幻、悬疑类题材,故事尽量原创,有一定的群众基础(最好是翻拍片),抢占贺岁档,宣发团队要豪华(联合企业),找一个从演员转行的得过奖的导演
从电影本身的属性建模由于电影市场发展的不成熟还是有很多困难,加上很难用变量限定电影质量。适当结合谷歌的搜索模型可能会得到更好的结果。
多元回归分析只是众多有监督预测方式的一种,由于存在线性假设,而线性假设在现实中并不常见,所以需要对模型进行进一步的调优以达到更高的模型拟合度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号