Selenium+BeautifulSoup实现懒加载页面数据抓取
背景描述:
1.爬取列表页数据
2.页面数据时动态懒加载,只有当页面滚动才能加载出相关图片
3.查看页面源码所得结构和页面显示的结构不一样
4.页面滚动到底部,中间部分的图片无法获取到
BeautifulSoup适合与爬取静态页面数据,擅长解析页面结构,获取元素信息
Selenium适合于模拟手动打开浏览器,适合处理懒加载的数据加载,可以定制交互式操作,用于自动化测试
需要先安装Chromedriver,安装过程:
查看chrome浏览器版本:
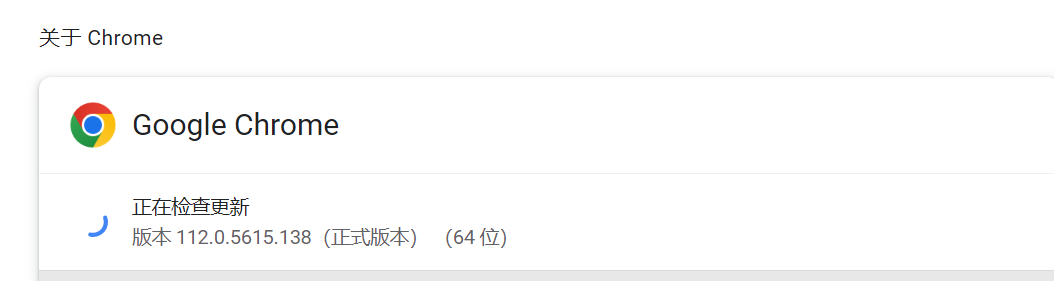
在https://registry.npmmirror.com/binary.html?path=chromedriver/搜索相近版本,下载
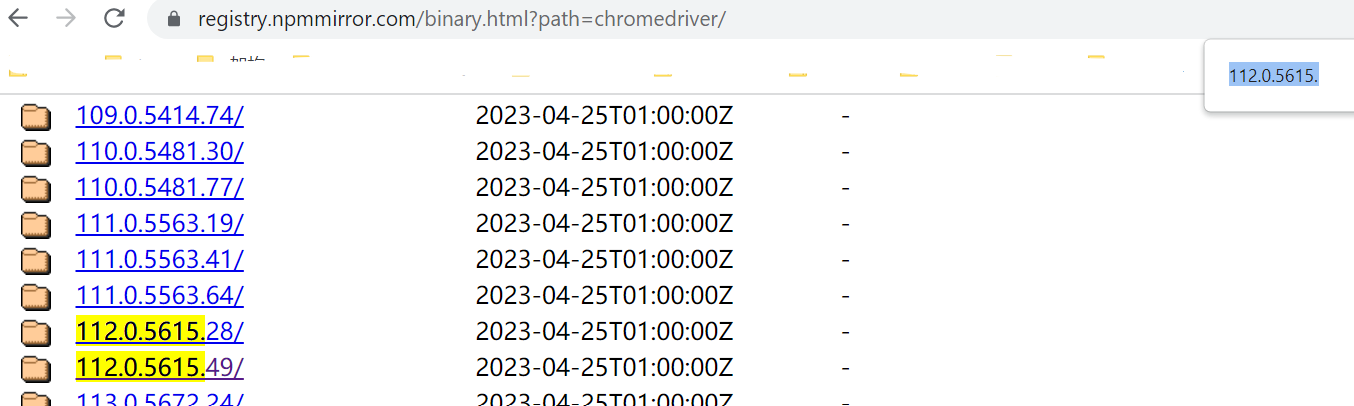
下载chromedriver_win32.zip即可,解压后将路径配置到windows环境变量的Path里面,接下来就可以通过from selenium import webdriver 使用模拟浏览器。
解决方案:
目前一般使用BeautifulSoup可以实现简单动态页面的数据抓取,考虑到时懒加载,需要考虑结合页面实际情况应用。
经分析,页面数据为懒加载,通过javascript 动态替换数据,实现页面实时的渲染,我们选择Selenium+BeautifulSoup实现。
因为列表页上产品比较多,需要鼠标下拉才能实现动态加载图片,所以需要使用Selenium,并且安装webdriver的chrome模拟用户行为。
抓取数据的网站:https://www.firstbottlewines.com/wines
代码:


import time from selenium import webdriver from selenium.webdriver.common.by import By from bs4 import BeautifulSoup from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import csv import codecs # 通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录。 # chromedriver已经添加环境变量 options= Options() options.add_experimental_option("detach", True) driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options) # 控制浏览器访问url地址 driver.get("https://www.firstbottlewines.com/wines") # 实现滚轮向下滑动,第一个参数是横向滚轮,第二个参数是纵向 page_height=driver.execute_script("return document.body.scrollHeight;") for i in range(1,31): scroll_s=str((i-1)*page_height/30) scroll_e=str(i*page_height/30) js = 'window.scrollTo('+scroll_s + ','+scroll_e+')' # 执行js代码 driver.execute_script(js) time.sleep(4) # Since you are calling BeautifulSoup as soup soup_page = BeautifulSoup(driver.page_source, 'html.parser') info_doms = soup_page.find_all('div',attrs={'filter-product mb-1 col-sm-6 col-md-3'}) params = [] i=1 for dom in info_doms: print(dom) #brand brand = dom.find('h3',class_='product-title').text brand_fomart=str(brand).strip().replace('\n', '').replace('\r', '').replace('\t', '') print('brand',brand_fomart) #type type_str=str(dom.find('div',class_='product-specs').text).strip().replace('\n', '').replace('\r', '').replace(u'\xa0', u' ') type = type_str.split('|')[0].strip() print('type',type) #year year = str(brand_fomart)[-4:].strip() print('year',year) #origin origin = type_str.split('|')[1].strip() print('origin',origin) #price price = str(dom.find('span',class_='product-actual-price').text).strip() print('price',price) #image_url img=dom.findAll('img') #image_url = dom.find('img',class_='mb-0 v-lazy-image v-lazy-image-loaded').get("src") image_url =str(img[0]["src"]).strip() print('image_url',image_url) res = [str(i),brand_fomart,type,year,origin,price,image_url] #res = brand_fomart+','+type+','+year+','+origin+','+price+','+image_url+ '\n' params.append(res) i=i+1 #print(params) with open('text.txt', 'w') as f: #for dom in wq1: #f.write(dom.get_text().strip()) f.write(str(params)) #with open('red_wine.csv', 'w',encoding="utf-8",newline="") as f: with open('red_wine.csv', 'w',encoding="utf-8-sig",newline="") as f: #f.write("Text;Time\n") #f.write(codecs.BOM_UTF8) wr = csv.writer(f,delimiter=',', quoting=csv.QUOTE_ALL) #wr.writerow(['Text', 'Time']) #for i in [params]: #wr.writerows(i) for p in params: f.write(p[0]+'|'+p[1]+'|'+p[2]+'|'+p[3]+'|'+p[4]+'|'+p[5]+'|'+p[6]+'\n') # 退出浏览器 driver.quit()
注:解决写入csv乱码,将写入时的配置改为 :encoding='utf-8-sig'
效果:
开启chrome webdriver,自动模拟手动拖动网页,实现懒加载,获取真实图片
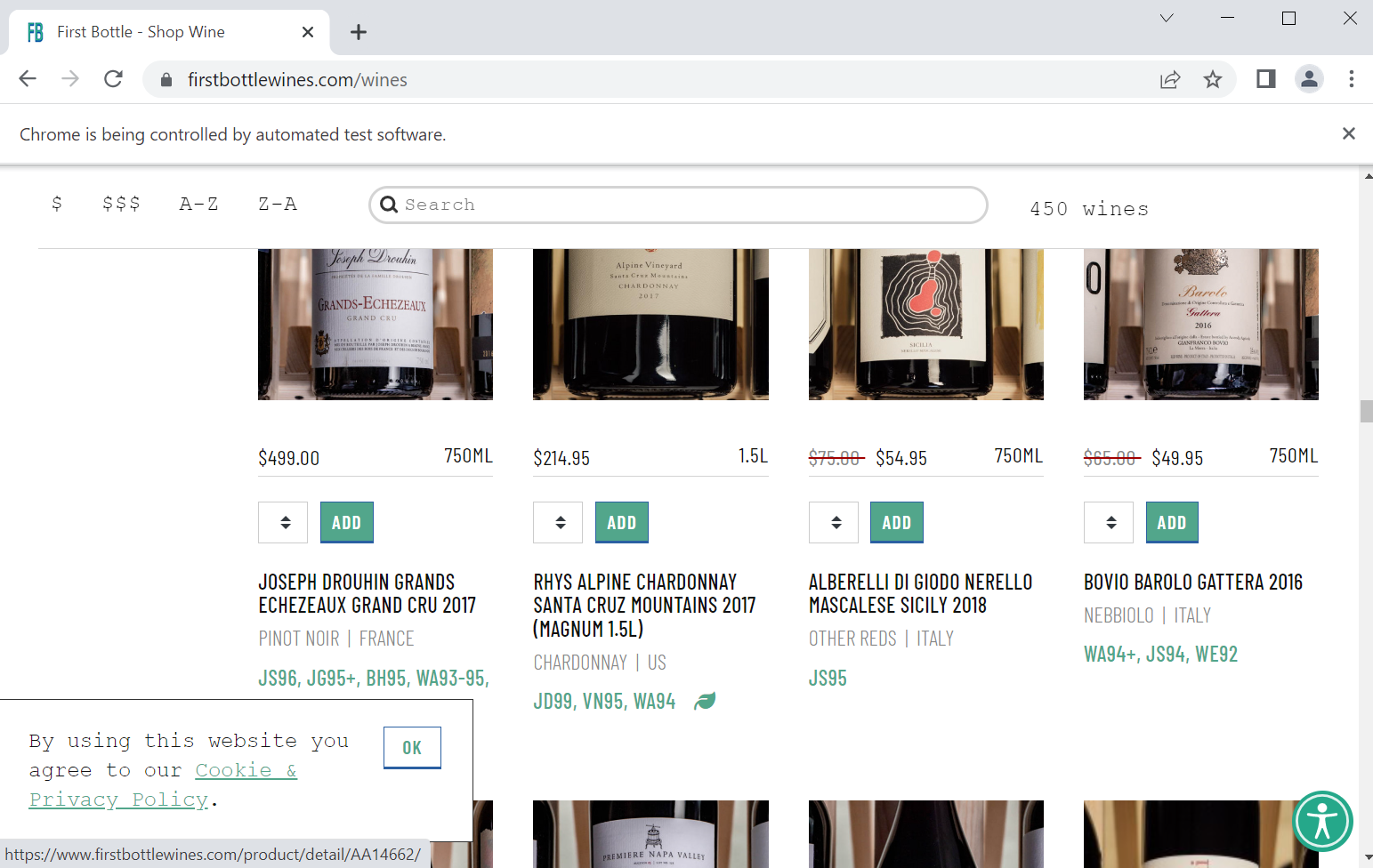
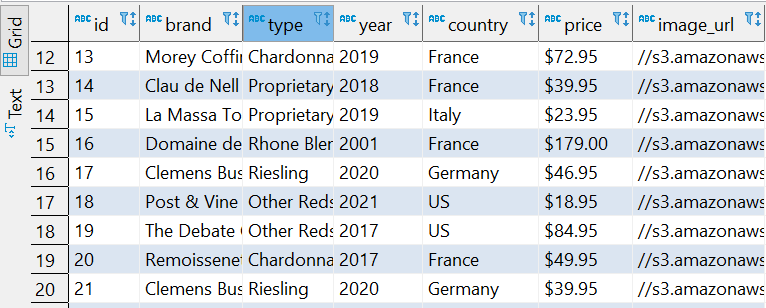
csv结果:

导入到postgresql,初始化的表结构:
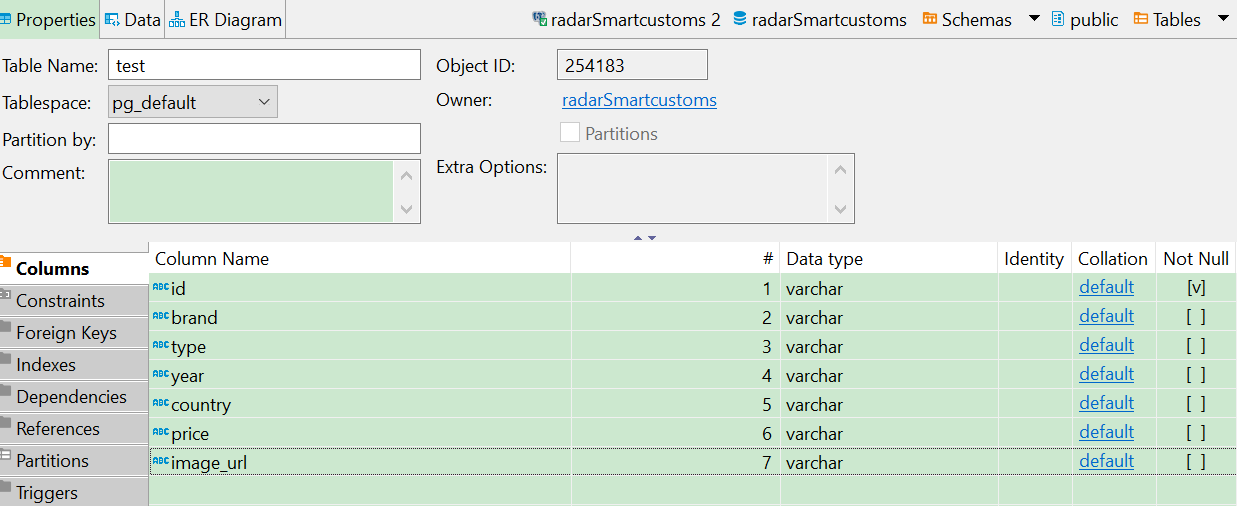
使用dbeaver的import date 直接导入数据,
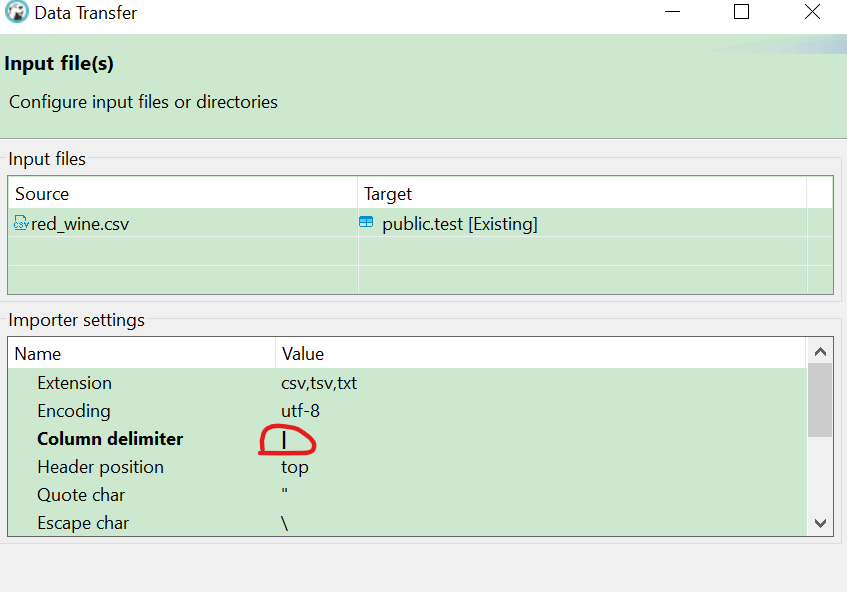
修改分隔符,选择映射columns,
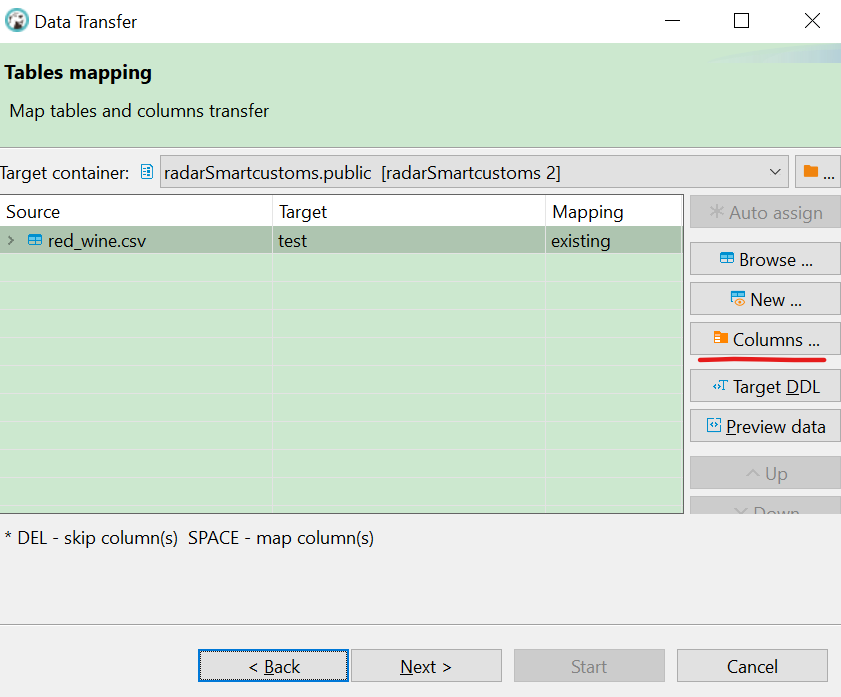
选择进行映射,
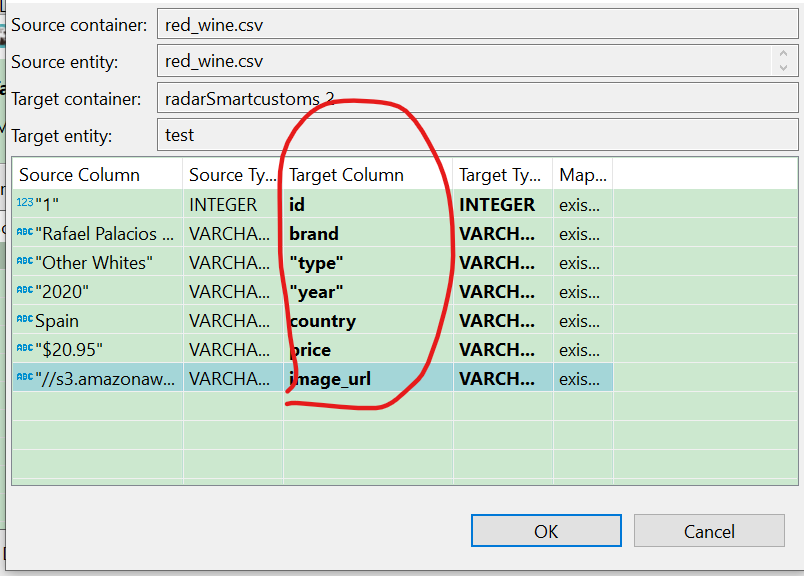
即可完成导入,导入成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号