
python学习交流 - 内置函数使用方法和应用举例
内置函数
python提供了68个内置函数,在使用过程中用户不再需要定义函数来实现内置函数支持的功能。更重要的是内置函数的算法是经过python作者优化的,并且部分是使用c语言实现,通常来说使用内置函数相比于用户自己定义函数实现相同功能,在执行效率和对内存的分配和使用上是要更加理想的。所以理解和熟练运用python中的内置函数,不仅可以增强代码的可读性,同时也可以提升代码的品质。下面对内置函数的使用方法进行分类介绍,以方便归纳理解。
一、查看作用域中变量相关
global ()
功能:查看全局作用域中变量的变量名和值
local ()
功能:查看所在局部作用域中变量的变量名和值
举例:通过下面的代码可以查看变量x和y分别属于哪个变量作用域
1 x = 1 2 def func(): 3 y = 1 4 print(globals()) 5 print(locals()) 6 func()
二、用户交互相关
input(‘<str>’)
功能:让用户进行输入,并将输入内容以字符串的形式返回。括号内可以输入字符,起到提示用户的作用
print(self, *args, sep=' ', end='\n', file=None, flsh = False)
*args:接收所有按位置传参的参数(被打印的对象)
sep = ' ': 多个被打印对象之间的连接字符串,默认是空格
end = ‘\n’:打印的内容以什么结尾,默认是换行符
file = None:打印的内容写入什么地方,默认None是打印在当前python的控制台,也 可以传入文件句柄,实现把内容写入到文件中。
flush = bool:是否后打印的内容可以冲刷掉之前打印的内容


print(1, 2, 3, 4, sep = '*',end = '') print('a', 'b', 'c', 'd', sep = '&',end = '')
1 import time 2 for i in range(0,101,2): 3 time.sleep(0.4) 4 char_num = i//2 #打印多少个'*' 5 per_str = '\r%s%% : %s\n' % (i, '*' * char_num) if i == 100 else '\r%s%% : %s'%(i,'*'*char_num) 6 print(per_str,end='', flush=True) 7 ## \r 可以将光标移动到行首
format
功能:定义字符串的对齐格式等
1 print(format('test', '^20')) # print一个长度为20的字符串,'test'居中 2 3 print(format('test', '>20')) # print一个长度为20的字符串,'test'右对齐 4 5 print(format('test', '<20')) # print一个长度为20的字符串,'test'左对齐
三、查看数据类型相关
type(para)
功能:查看变量type的数据类型
四. 内存相关相关
id(para)
功能:返回变量para的内存地址
hash(para)
功能:返回一个可hash变量的hash值(一个int型的数字)
说明
1. 每一次程序执行,内容相同的可hash变量的hash值不会变化
2. 对于字典,会把保存value的内存地址和对应的key的hash值关联起来,所有可以通过key迅速查找对应的value。同时这也是要求key必须是可hash数据类型的原因
五. 文件操作相关
open(file, mode='r', encoding=None)
功能:打开文件,返回一个文件句柄
说明:
1. file:要打开的文件的路径
2. mode:r, w, a 分别对应只读,只写和只写(末尾追加)模式
rb, wb, ab 表示以2进制进行内容的读/写
3. encoding:以何种编码方式打开文件(‘utf-8' 'gbk'等),windows系统默认使用'utf-8'
六. 模块相关
import
功能:引入模块到程序中
说明:
两种调用import函数的方法:
import <模块名>
<模块名> = __import__.('模块名')
七.调用相关
callable(obj)
功能:判断对象是否可以被调用,返回bool值
dir(obj)
功能:查看参数所属类型的所有内置方法
说明:
例如,可以通过以下判断变量是否是一个可迭代对象
lst = [1,2,3,4,5]
print('__iter__' in dir(lst))
八. 数字类型和进制转化相关
bool() int() float() complex()
功能:分别对应把变量转化成bool型,整形,浮点型,复数型
bin() oct() hex()
分别对应把变量转化成二进制,八进制,十六进制
九、数学运算相关
abs(para)
功能:返回变量的绝对值
divmode(<除数>,<被除数>) -> (商,余)
功能:返回一个元祖,包含除法运算的商和余数
min(*args[, key = None[, default =obj] )
功能:返回args中的值最小元素
说明:
1. key可以设置为函数名变量,将args中的元素逐一作为该函数的参数,返回值最小的元素为min的返回值
1 ret = min([1,2,-3], key=abs) 2 3 print(ret) ## -1
2. 如果设置了defalut,当args为空时,不会报错,而是返回default
ret = max([],default=10) print(ret) ## 打印 10
max(args[, key = None[, default =obj] )
功能:返回args中最大的元素,用法和min()相同
sum(iterable[, start])
功能:返回iterable中所有元素的和
说明:
1. 参数iterable: 可迭代对象,不支持动态参数
2. start: iterable的和再与start相加,start默认为0
1 ret = sum([1,2,3],5) 2 3 print(ret) #打印11 1,2,3的和在与5相加
round(x, y)
功能:返回保留x保留y位小数后的结果
1 ret = round(3.1415926,2) 2 3 print(ret) #3.14
pow(x,y,z)
功能:pow(x,y)返回x的y次幂
说明:
1. pow(x,y,z)返回x的y次幂在除以z的余数
1 ret1 = pow(2,3) 2 3 ret2 = pow(2,3,2) 4 5 print(ret1) # 8 6 7 print(ret2) # 0
十. 字符串类型代码执行相关
exec(str)
功能:把字符串的内容作为代码来执行,返回值为None
说明:
1. 因为没有返回值,适用于字符串中是流程性代码的情况
1 a = "print(123)" 2 3 exec(a) # 123 4 5 print(exec(a)) # 返回值为None
eval(str)
功能:eval也是把字符串的内容作为代码来执行,与exec不同的是可以返回代码执行的返回值
说明:
1. 多用于执行表达式类型的字符串代码
1 a = 'min(1,3,5,7,9)' 2 3 ret = eval(a) 4 5 print(ret) # 1
compile(str,<filename>,<mode>)
功能:把字符成代码
说明:
1. filename: 用于指定字符串类型代码的作用域,不指定的话传入一个空字符串
2. mode:
'eval': 编译后的代码用eval函数执行
'exec': 编译后的代码用exec函数执行
'single': 编译后的代码用eval函数执行,只执行第一句代码
1 code1 = compile("print(1,2,3)\nprint('a','b','c')",'','exec') 2 3 exec (code1) # 1 2 3 4 5 #a b c
repr(obj)
功能:将内容转化成适合编译器阅读的形式
说明:
1. r = repr(object) -> eval(r) == object
2. 而eval(str)是执行引号内的内容
1 str1 = repr('abc') 2 3 str2 = str('abc') 4 5 print(str1) # >> 'abc' 适于解释器阅读的形式 6 7 print(str2) # >> abc 适于解释器阅读的形式 8 9 print('abc' == eval(str1)) #True
十一、处理序列相关
reversed(iterable)
功能:翻转数列中的元素,返回一个迭代器,不改变原列表
1 lst = [0, 1, 2, 3, 4, 5, 6, 7, 9] 2 3 g = reversed(lst) #reversed函数获得一个迭代器 4 5 lst_new = list(g) #从迭代器中取值 6 7 print(lst_new) # >> [9, 7, 6, 5, 4, 3, 2, 1, 0]
slice(start, stop[, step])
功能:slice类的一个构造函数,返回一个切片对象
说明:
1. 对字符串切片的语法list[start:stop:step],其实是slice构造函数的一个语法糖
1 lst = [0, 1, 2, 3, 4, 5, 6, 7, 9] 2 3 sli = slice(1,4,None) #生成一个切片对象 4 5 lst_new = lst[sli] #用切片对象对lst进行切片 6 7 print(lst_new) #[1, 2, 3]
十二、字符串转字节相关
bytes([source[, encoding[, errors]]])
功能:基于source,返回一个不可修改的字节串
说明:
1. 当source为字符串类型是,encoding参数必须指定
2. 也可以用 str.encode('encoding')的方法将转字符串转成字节数组
3. 当source为一个整数时,返回这个整数指定长度的空字节串
4. 返回的字节串不可以修改
5. 当source是一个可迭代对象的时候,每个数字元素必须在0 <= x < 256范围内
1 b_arr1 = bytes('测试', encoding='utf-8') #用bytes函数将字符串转换成字节数组 2 3 print(b_arr1) #b'\xe6\xb5\x8b\xe8\xaf\x95' 4 5 b_arr2 = '测试'.encode('utf-8') #用字符串类的encode方法将字符串转换成字节数组 6 7 print(b_arr2) #b'\xe6\xb5\x8b\xe8\xaf\x95'
6. bytes函数在网络编程中有较多应用。只有byte型才能通过网络传输
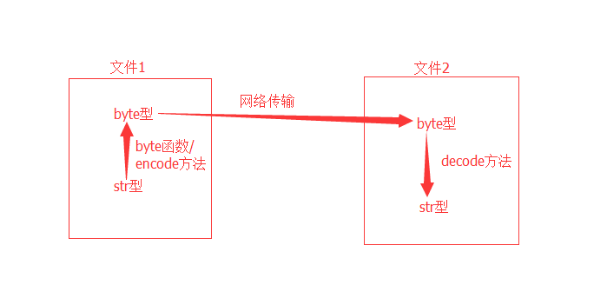
bytearray([source[, encoding[, errors]]])
功能:返回一个可以被修改的字节数组
说明:
1. 各参数的使用方法与bytes()函数相同
2. 必须使用ASCII码修改字字节数组中的元素
3. 给字节数组的元素重新赋值需要使用ASCII码
4. 先把字符串转化成字节数组再进行元素的修改,可以避免修改字符串的元素是需要定义新的字符串的问题。使用于需要频繁修改某个字符串中的元素的情景。
1 b_arr1 = bytearray('abc', encoding='utf-8') 2 3 print(b_arr1) #bytearray(b'abc') 4 5 b_arr1[0] = 65 #修改字节数组的元素,65为'A'的ASCII码 6 7 print(b_arr1) #bytearray(b'Abc') 8 9 str1 = b_arr1.decode('utf-8') 10 11 print(str1) # Abc
memoryview()
功能:为支持buffer protocol[1,2]的对象提供了按字节的内存访问接口,返回内存查看对象
说明:
对内存查看对象进行切片等操作,不会在内存中产生一个新的对象。方便查看一个字符串的整体或局部,而不不需要创建新对象占用内存。
1 b_arr1 = bytearray('abc', encoding='utf-8') 2 3 view = memoryview(b_arr1) 4 5 print(view[0]) # 97 查看a的ASCII码,但切片操作没有在内存中产生新的对象
ord 和 chr函数
ord功能:查看一字符对应的ASCII码
chr功能:查看一个ASCII码对应的字符
print(ord('A')) #65
print(chr(65)) #A
十三、序列重构相关
enumerate(iterable[, start])
功能:返回一个迭代器,每个元素是一个元祖
说明:
1. 返回的元祖的第一元素是序号,第二个元素原iterable中的元素
2. start可以指定序号的起始值,默认从0开始
1 lst = ['苹果','华为','小米'] 2 3 for i in enumerate(lst,1): 4 5 print(i[0],i[1]) 6 7 g = enumerate(lst,1) 8 9 print('__iter__' in dir(g)) # True 10 11 print('__next__' in dir(g)) # True
all(iterable)和any(iterable)函数
功能:
all():判断可迭代对象中的元素是否全为真
any():判断可迭代对象中的元素是否存在为真的
1 lst1 = [1,'abc',(1,3)] 2 3 lst2 = [1,'abc',(1,3),None] 4 5 lst3 = [None,'',()] 6 7 print(any(lst1)) #True 8 9 print(any(lst2)) #True 10 11 print(any(lst3)) #False 12 13 print(all(lst1)) #True 14 15 print(all(lst2)) #False 16 17 print(all(lst3)) #False
zip(*args)函数
功能:接收任意数量的序列为参数,返回一个迭代器。迭代器每个元素是一个元祖,依次包含所有序列的第1个,第2个......元素
说明:
1. 生成器能取出元素的个数以参数中最短的序列为准
1 test1 = zip([1,2,3],['a','b','c']) 2 3 test2 = zip([1,2,3],['a','b','c','d']) 4 5 print(list(test1)) # [(1, 'a'), (2, 'b'), (3, 'c')] 6 7 print(list(test2)) #[(1, 'a'), (2, 'b'), (3, 'c')]
zip函数应用举例:
需求:现有两个元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
1 tu = (('a'),('b')),(('c'),('d')) 2 3 solution1 = [{i[0]:i[1]} for i in zip(tu[0], tu[1])] #方法一:列表推导式 4 5 print(solution1) #[{'a': 'c'}, {'b': 'd'}] 6 7 solution2 = map(lambda x:{x[0]:x[1]}, zip(tu[0], tu[1])) #方法二:使用map函数构造 8 9 solution2 = list(solution2) #迭代器强转列表 10 11 print(solution2) #[{'a': 'c'}, {'b': 'd'}]
filter(func, iterable)
功能:将可迭代对象中每个元素逐一作为函数func的参数,只保留返回值为True的元素。filter函数返回一个迭代器
应用举例:
需求:筛选出列表中为偶数的元素
1 lst = [0, 1, 2, 3, 4, 5, 6 ,7, 8, 9] 2 lst_filter = filter(lambda x: x % 2 == 0, lst) 3 print(list(lst_filter)) #[0, 2, 4, 6, 8]
map(func, iterable)
功能:将可迭代对象的每个元素逐一作为函数func的参数,返回一个迭代器。迭代器中的每个元素为上述func函数的返回值。
应用举例:
需求:把包含员工名字的列表,每个元素后面拼接上邮箱地址
1 lst = ['zhangsan', 'lisi', 'wangwu', 'zhaoliu'] 2 3 lst_map = map(lambda x: x + '@balabala.com', lst) 4 5 print(list(lst_map)) #['zhangsan@balabala.com', 'lisi@balabala.com', 'wangwu@balabala.com', 'zhaoliu@balabala.com']
sorted(iterable, reverse=T/F, key=func)
功能:对可迭代对象进行排序,返回一个包含排序过后元素的列表(因为排序算法需要获取可迭代对象中的每一个元素进行操作,所以sorted函数的返回值不是迭代器)
说明:
1. 默认变量reverse为True,进行正向排序。设置为False时,进行反向排序
2. 如果设置默认变量key,则按照可迭代对象中元素传入func后的返回值的大小进行排序
应用举例:
需求:按照可迭代对象的绝对值的大小进行排序
1 tu = (1, -5, 3, -4, 2) 2 3 lst_sorted = sorted(tu, key=abs) 4 5 print(lst_sorted) #[1, 2, 3, -4, -5]
