

Elasticsearch7.X ILM索引生命周期管理(冷热分离)
一、“索引生命周期管理”概述
二、为什么要使用“索引生命周期管理”
1、ELK集群之前的索引模式,通过app_name和日期区分,随着时间累积,索引数量逐渐增多,造成服务器内存、CPU、IO等指标上涨;
2、需要创建额外定时任务执行索引删除脚本,这种方式无法避免kafka重复消费造成的大量已删除索引重建,并无法用脚本按日期删除;
3、根据日志查询和存储的特点,将数据冷热分离,热数据使用高性能磁盘提高写入与查询效率,温数据只做查询不影响数据写入性能,冷数据用OSS等低价存储作为归档节约存储成本。
三、面临的问题
1、ES生命周期策略要紧密贴合业务模型
2、数据冷热节点和生命周期策略需要合理规划
3、数据高可用性规划(单纯日志场景对数据可用性并不高,可以规划0副本索引,减小系统开销)
四、配置方法及原理
1、生命周期管理的本质--RollOver
当现有索引被认为太大或太旧时,滚动索引API将别名滚动到新索引。该API接受一个别名和一个条件列表。别名必须只指向一个索引。如果索引满足指定条件,则创建一个新索引,并将别名切换到指向新索引的位置
2、使用场景
RollOver适合存放日志数据、索引非常大、索引实时导入数据等场景
在索引模板配置好索引的setting、mapping等参数,然后配置好_rollover规则,es会帮助你处理剩余的事情
索引生命周期管理使用了rollover的特性,将rollover分成四个阶段。
3、四个阶段
ES索引生命周期管理分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,warm、cold、delete分别对rollover后的数据进一步处理
| 描述 | |
|---|---|
| hot | 主要处理时序数据的实时写入 |
| warm | 可以用来查询,但是不再写入 |
| cold | 索引不再有更新操作,并且查询也会很少 |
| delete |
4、配置方法
实现索引生命周期,必须同时存在如下要素,缺一不可,上述四个阶段可以根据实际情况配置,并为ES数据节点添加相应的标签。
| 配置项 | 描述 |
|---|---|
| 节点标签 | 配置数据节点标签,区分热节点、温节点以及冷节点 |
| 生命周期策略 | 定义热阶段的大小、最大文档数或最大时长,温阶段是否缩小索引、冷阶段存在时长及删除周期 |
| 索引模板引用生命周期策略 | 模板中指定引用的生命周期策略,按模板规则创建索引后,加载生命周期策略 |
| 索引模板指定调度节点 | 将新建索引分片都分配到热节点 |
4.1、节点
热节点
这种类型的数据节点执行集群内所有的操作,节点存储的数据经常被查询,属于IO、CPU密集型操作,因而需要CPU比较空闲和装有高性能IO读写的磁盘(如SSD)的服务器支撑。
1 2 3 4 5 6 7 | #配置方法vim /data/app/elasticsearch/config/elasticsearch.yml#每个热节点加入如下配置并重启服务node.attr.box_type: hotnode.attr.rack: rack1#这两项配置是为节点增加标签,具体名称并不是写死的,与后面模板和策略配置有关 |
温节点
1 2 3 4 5 6 | #配置方法vim /data/app/elasticsearch/config/elasticsearch.yml#每个温节点加入如下配置并重启服务node.attr.box_type: warmnode.attr.rack: rack1 |
冷节点
冷节点数据适合作为归档使用,比温节点查询还要少(比如半月以上的归档日志),这种类型数据一般很少查询,并不会消耗CPU性能及IO,但是存储容量会很大,需要更低成本的存储,例如OSS或S3;ES可以使用经过fuse协议挂载的对象存储作为后端存储。
1 2 3 4 5 6 | #配置方法vim /data/app/elasticsearch/config/elasticsearch.yml#每个温节点加入如下配置并重启服务node.attr.box_type: coldnode.attr.rack: rack1 |
4.2、生命周期策略
配置方法:
1、利用Kibana新建策略并指定到模板
打开Kibana--->管理--->索引生命周期策略
创建策略
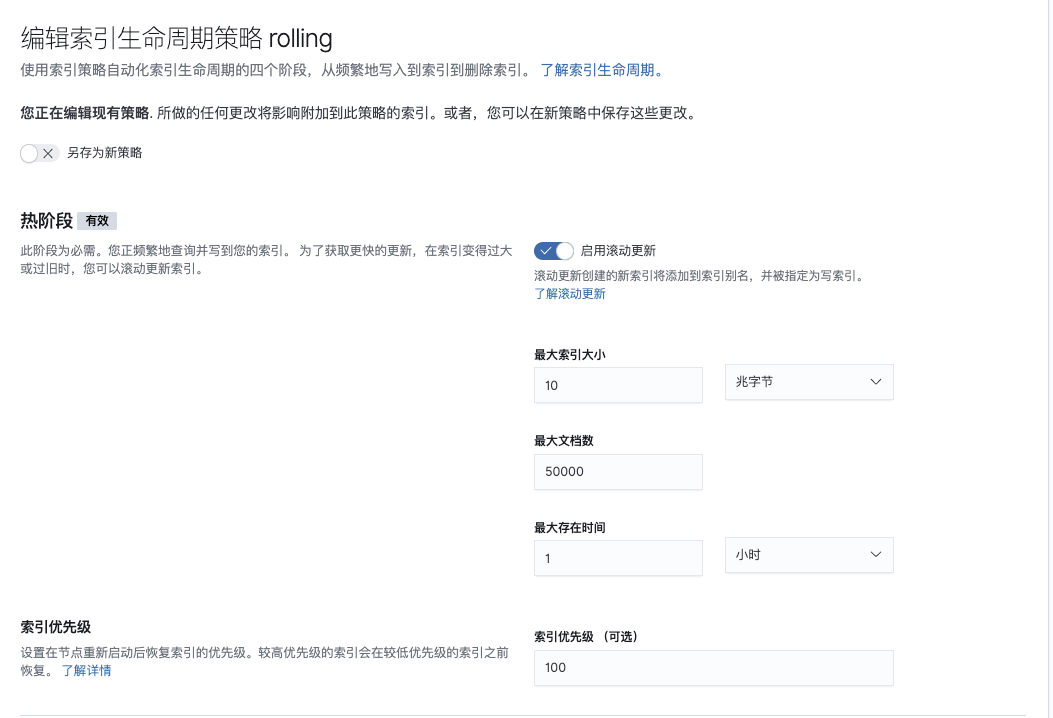
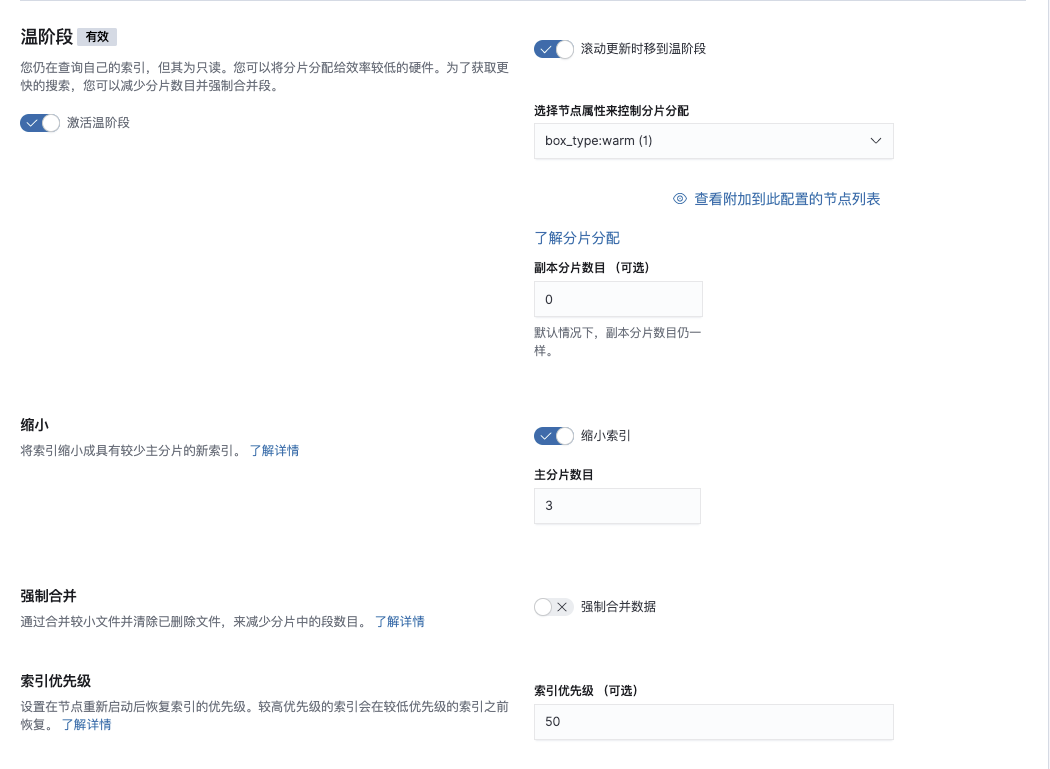
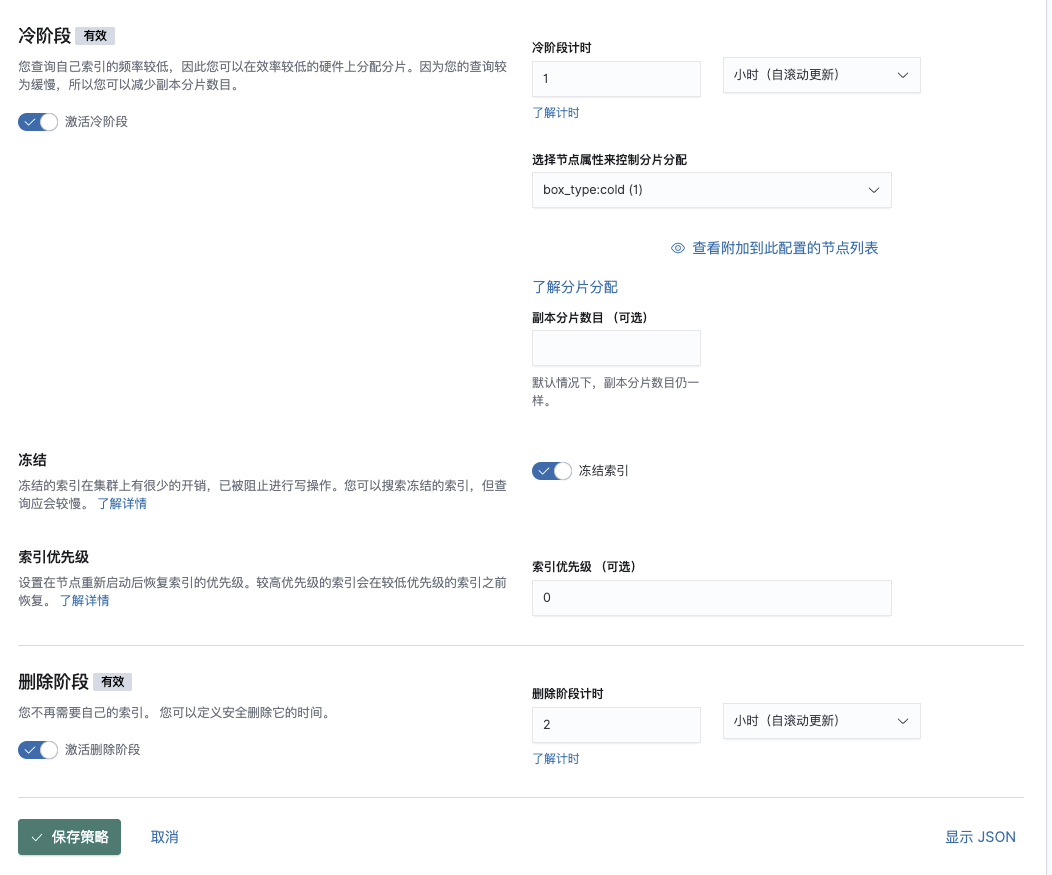
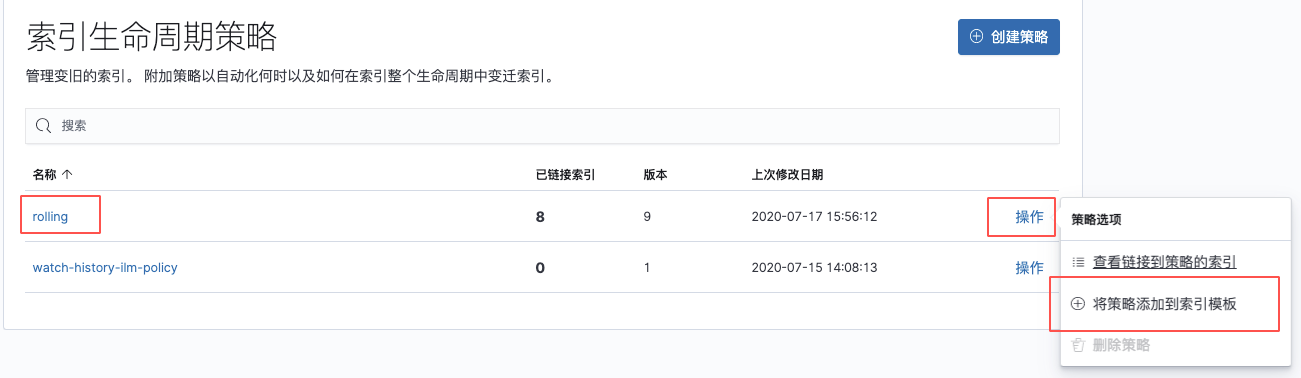
保存策略并在创建模板后添加到模板中
2、调用ESApi将策略写入ES
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | curl -XPUT -H "content-type:application/json" http://es_addr:9200/_ilm/policy/test_policy \-d "{ "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_age": "1h", "max_size": "10mb", "max_docs": 50000 }, "set_priority": { "priority": 100 } } }, "warm": { "min_age": "0ms", "actions": { "allocate": { "number_of_replicas": 0, "include": {}, "exclude": {}, "require": { "box_type": "warm" } }, "shrink": { "number_of_shards": 3 }, "set_priority": { "priority": 50 } } }, "cold": { "min_age": "1h", "actions": { "freeze": {}, "allocate": { "include": {}, "exclude": {}, "require": { "box_type": "cold" } }, "set_priority": { "priority": 0 } } }, "delete": { "min_age": "2h", "actions": { "delete": {} } } } }" |
4.3、索引模板
以下为索引模板配置,要有以下配置项策略才会生效,其他选项如字段mapping等请参考官方文档
1 2 3 4 5 6 7 8 9 10 11 | PUT _template/my_template{ "index_patterns": ["test-*"], "settings": { "number_of_shards": 5, "number_of_replicas": 0, "index.lifecycle.name": "test_policy", #指定索引生命周期策略名称 "index.lifecycle.rollover_alias": "test-alias", #指定rollover别名(索引写入与读取时所用的名称) "routing.allocation.require.box_type": "hot" #指定索引新建时所分配的节点(此项不指定会默认分配到所有节点) }} |
注意:索引创建的名称应该是以 “-00001”等可自增长的字段结尾,否则策略不生效,es指定索引的别名写入


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY