
基于NodeJs的网页爬虫的构建(一)
好久没写博客了,这段时间已经忙成狗,半年时间就这么没了,必须得做一下总结否则白忙。接下去可能会有一系列的总结,都是关于定向爬虫(干了好几个月后才知道这个名词)的构建方法,实现平台是Node.JS。
背景
一般爬虫的逻辑是这样的,给定一个初始链接,把该链接的网页下载保存,接着分析页面中的链接,找到目标链接检查是否已经请求过,如果未请求则放入请求队列,页面下载完成后交给索引器建立索引,如此往复即可建立一套提供给搜索引擎使用的文档库。我当时的需求并不是这样,而是抓取某几个网站的数据并把规定的字段输出为结构化的文件最终会放到EXCEL中分析。后者也许只需要该网站全量的商品数据,其它一概不需要,这样见面不需要保存。
我将顺着时间顺序记录问题和想法。
问题
编码遇到的第一个问题,也是在哪里都会遇到的问题,要彻底解决编码问题,就需要弄清楚三个问题:
- 为什么乱码?
- 如何找到内容的正确编码?
- 如何转码?
为什么乱码,当然是因为当前的字符串使用的编码并不是“正确”的,所谓“正确”就是该字符串在进入内存时用的什么编码去存储。举个粟子,“你”字的utf8编码[1]时内存的值: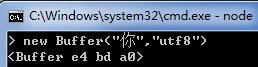
这时候使用ascii来解码就得不到正确的文本,因为ascii最大也就认识7E[2]。之所以NodeJS打印非utf8的字符串乱码,是因为它默认使用utf8,所以必须要找到来源的正确编码转换成utf8。
那么如何找到内容的正确编码?看HTTP协议!在HTTP header中有一个Content-Type的field[3],它可以指定协议所支持的media-type,包括图片、文本、音频等,我们只看文本,并且是文本中的html,一般后面会跟上字符集编码。举个例子:
Content-Type: text/html; charset=ISO-8859-4
可以看到指定了html格式的文本类型和字符集,那当我们接收到返回时,只需要读取返回头中的Content-Type块,这就可以解决绝大部分问题了。但还没有完,有的网站并没有在HTTP header里面告诉你是什么字符集,例如:
Content-Type: text/html
baidu.com返回的就是这样的头,那浏览器如何知道怎么解析页面呢,因为浏览器打开并不会乱码,仔细看看返回的HTML文件就会发现文档里面会有meta标签来指定编[4]:
When the http-equiv attribute is specified on a meta element, the element is a pragma directive. You can use this element to simulate an HTTP response header, but only if the server doesn't send the corresponding real header; you can't override an HTTP header with a meta http-equiv element.这样看来呢,协议头里面的优先级会高一点,所以正确的解析顺序是先从协议头中找编码方式,找不到再从文档里面寻找meta的http-equiv标签。(还有两篇文章关于UTF-8和Unicode详解写的很详细([5],[6]))。
找到了正确的编码以后,就可以找类库来做转码。比如从GBK编码转到UTF-8,只需要使用它们的编码对应关系做对应的替换。在NodeJS里面使用iconv和iconv-lite可以很好地完成这个工作,iconv是C++实现的本地库,安装会有些困难,iconv-lite是纯javascript实现的转码,安装相对简单,缺点是可能码不全也没有正式版。
多谢@落幕残情的提醒,再加一点补充。编码是可以通过检测来获取的,但是在WEB中并不是正确的做法,这种方法通常在不知道源的编码情况被迫使用的,而HTTP协议中和HTML文档规定了字符编码!检测概率模型存在误差,NodeJS有一个库叫做jschardet,该模块在node-webcrawler中被使用,实践告诉我出错概率非常大。再次感谢,欢迎其他想法。
[1]. http://zh.wikipedia.org/wiki/UTF-8
[2]. http://zh.wikipedia.org/wiki/ASCII
[3]. http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html
[4]. http://www.w3.org/wiki/HTML/Elements/meta
[5]. 关于文件编码格式的一点探讨
[6]. Unicode详解

