

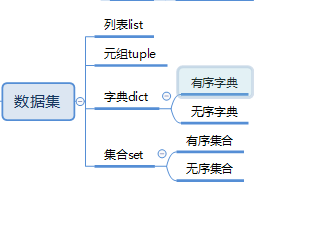
Python数据类型-数据集
数据类型-数据集
一、基本数据类型——列表
列表的定义:
定义:[] 内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
列表的创建:
list_test=['张三', '李四', '王五']
或
list_test = list('王五')
列表的特点和常用操作
特性:
1. 可存放多个值
2. 按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序
3. 可修改指定索引位置对应的值,可变
常用操作:
# 索引
i = ['egon', 'test', 'seven', 'mike'] print(i[0])
# 切片
i[0:2]
['egon', 'test']
>>> i[2:5]
['seven', 'mike']
>>> i[:2]
['egon', 'test']
>>> i[::2]
['egon', 'seven']
>>> i[::-1]
['mike', 'seven', 'test', 'egon']
# 追加
>>> i.append('eve')
>>> i
['egon', 'test', 'seven', 'mike', 'eve']
# 删除
>>> i.remove('eve')
>>> i
['egon', 'test', 'seven', 'mike']
>>> i.pop()
'mike'
# 长度
>>> len(i)
# 包含
>>> 'mike' in i
True
列表与字符串 —— split 和 join
# 分割
item1 = []
item = "www.luffycity.com"
item1 = item.split('.')
print(item1)
# 连接
>>> i= ['hi', 'mike']
>>> '!'.join()
'hi!mike'
# range
count = 0
for i in range(101):
if i % 2 == 0:
count += i
print(count)
二、 基本数据类型—— 元组
元组的定义和特性
特性:
- 可存放多个值
- 不可变
- 按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
元组的创建与常用操作
# 创建
ages = (11,22, 33, 44, 55)
或
ages = tuple((11,22, 33, 44, 55))
# 常用操作
# 索引
>>> ages = (11,22, 33, 44, 55)
>>> ages[0]
11
>>> ages[-1]
55
# 切片 : 同list
# 循环
>>> for age in ages:
print(age)
11
22
33
44
55
# 长度
>>> len(ages)
5
# 包含
>>> 11 in ages
True
元组的特性详解
1. 可存放多个值
如果元组中只有一个值
t = (1,)
t = (1) # <==>t = 1
元组中不仅可以存放数字,字符串,还可以存放更加复杂的数据类型
2. 不可变
元组本身不可变,如果元组中还包含其它可变元素,这些可变元素可以改变
三 、可变 不可变数据类型和hash
| 可变类型 | 不可变类型 |
| 列表 | 数字 |
| 字符串 | |
| 元组 |
# 列表
>>> i = [1,2,3,4]
>>> id(i)
4392665160
>>> i[1] = 1.5
>>> i
[1,1.5,3,4]
>>> id(i)
4392665160
# 数字
>>> a = 1
>>> id(a)
4297537952
>>> a+=1
>>> id(a)
4297537984
从内存角度看列表与数字的变与不变
字符串
# 例1
>>> s = 'hello'
>>> s[1] = 'a'
Traceback (most recent call last):
File "<pyshell#5>". line 1, in<module>
s[1] = 'a'
TypeError:'str' object does not support item assignment
# 例2
>>> s = 'hello'
>>> id(s)
4392917064
>>> s += 'world'
>>> s
'hello world'
>>> id(s)
4393419504
字符串也可以像列表一样使用索引操作,但是通过上例可以看出,不能像修改列表一样修改一个字符串的值,当对字符串进行拼接的时候,原理和整数一样,id值已经发生了变化,id值已经发生了变化,相当于变成了另外一个字符串。
元组不允许修改
>>> t = (1,2,3,4)
>>> t[1] = 1.5
Traceback (most recent call last):
File "<pyshell#5>". line 1, in<module>
t[1] = 1.5
TypeError: 'tuple' object does not support item assignment
hash
存储如下一些数据:
张三 13912345678
李四 13812345678
王五 13612345678
>>> hash("张三")
-354361033326252388
>>> hash("李四")
-8011736106419318409
>>> hash("王五")
-5353383273595561117
四、字典
字典的定义和特性
字典是python语言中唯一的映射类型
定义: {key1:value1,key2:value2}
1、键与值用冒号":"分开
2、项与项用逗号“,” 分开
特性:
- key-value结构
- key必须可hash,且必须为不可变数据类型,必须唯一
- 课存放任意多个值,课修改、可以不唯一
- 无序
字典的创建与常见操作
person = {"name":"mike", age:20}
或
person = dict(name='mike', age=20}
或
person = dict((['name','mike'],['tom',22]))
{}.fromkeys(seq,100) # 不指定100默认为NOne
# 注意
>>> dic = {}.fromkeys(['k1','k2'],[])
>>> dic
{'k1': [], 'k2': []}
>>> dic['k1'].append(1)
>>> dic
{'k1': [1], 'k2': [1]}
字典的常见操作
键、值、键值对
- dic.keys() 返回一个包含字典所有key的列表
- dic.values() 返回一个包含字典所有value的列表
- dic.items() 返回一个包含所有(键、值)元组的列表
- dic.iteritems()、dic.iterkeys()、dic.itervalues() 与它们对应的非迭代方法一样,不同的是他们返回一个迭代值,而不是一个列表
# 新增
- dic['new_key'] = 'new_value'
- dic.setdefault(key,None), 如果字典中不存在key键,由dic[key]= default 为他赋值
# 删除
- dic.pop(key[,default]) 和get方法相似。如果字典中存在key,删除并返回key对应的vuale;如果key不存在,且没有给出default的值,则引发keyerror异常
- dic.clear() 删除字典中的所有项或元素
# 修改
- dic['key'] = 'new_value',如果key在字典中存在,‘new_value'将会替代原来的value值
- dic.update(dic2) 将字典dic2的键值对添加到字典dic中
# 查看
- dic['key'] ,返回字典中key对应的值,若key不存在字典中,则报错
- dic.get(key,default=None) 返回字典中key对应的值,若key不存在字典中,则返回default的值
# 循环
- for k in dic.keys()
- for k,v in dic.items()
- for k in dic
# 长度
len(dic)
五、 集合
认识集合
集合是一个数学概念,由一个或多个确定的元素所构成的整体叫集合
集合中的元素有三个特点:
- 确定性(元素必须可hash)
- 互异性(去重)
- 无序性(集合中的元素没有先后之分),如集合{3,4,5}和{3,5,4}算作一个集合
注意: 集合存在的意义就在于去重和关系运算
集合的关系运算
&.& =:交集——即学习跆拳道课程也学习机器人的同学
i={'张三','李四','王五'}
p={'张三','李四','mike'}
print(i.intersection(p))
print(i & p)
|,|=:合集,也叫并集——学习跆拳道课程和学习机器人的同学
i={'张三','李四','王五'}
p={'张三','李四','mike'}
print(i.union(p))
print(i|p)
-,-=:差集——只在学习跆拳道课程而不学习机器人的同学
i={'张三','李四','王五'}
p={'张三','李四','mike'}
print(i.difference(p))
print(i-p)
~,~=:对称差集——只在学习跆拳道课程或只学习机器人的同学
i={'张三','李四','王五'}
p={'张三','李四','mike'}
print(i.symmetric_difference(p))
print(i^p)
包含关系
in,not in:判断某元素是否在集合内
==,!= : 判断两个集合是否相等
两个集合之间一般有三种关系,相交、包含、不相交,在python中分别用下面的方法判断
- set.isdisjonit(s): 判断两个集合是不是不相交
- set.issuperset(s): 判断集合是不是包含其他集合,等同于a>=b
- set.issubset(s): 判断集合是不是被其他集合包含,等同于a<=b
集合的常用操作:
# 元素的增加
单个元素的增加: add(),add的作用类似列表中的append
对序列的增加:update(),而update类似extend方法,update方法可以支持同时传入多个参数
#元素的删除
集合删除单个元素有两种方法:
元素不在原集合中时:
set.discard(x)不会抛出异常
set.remove(x) 会抛出keyError错误
pop(): 由于集合是无序的,pop返回的结果不能确定,且当集合为空时调用pop会抛出keyerror错误
clear(): 清空集合
六:collections
collections模块:
- namedtuple: 生成可以使用名字来访问元素内容的tuple子类
- deque:双端队列,可以快速的从另外一侧追加和推出对象
- counter:计数器,主要用来计数
- orderddict:有序字典
- defaultdict:带有默认值的字典
# namedtuple
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(1, 2)
print(p.x)
print(p.y)
输出:
1
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素
类似的,要用坐标和半径表示一个圆,可以用namedtuple定义
# namedtuple('名称',[属性list]):
Circle = namedtuple('Circle',['x','y','r'])
deque
deque 是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('x')
q.appendleft('y')
print(q)
defaultdict
使用dict时,如果引起的key不存在,就会抛出KeyError。希望key不存在时,返回默认值,用defaultdict
orderedDict
使用dict时,key是无序的,在对dict做迭代时,无法确定key的顺序
要保持key的顺序,可以用orderedDict
orderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的key
from collections import Counter
c = Counter()
for ch in 'programming':
c[ch] = c[ch] + 1
print(c)
输出:
Counter({'r': 2, 'g': 2, 'm': 2, 'p': 1, 'o': 1, 'a': 1, 'i': 1, 'n': 1})
Counter实际上也是dict的一个子类
知识点小结:
基本数据类型:
|
可变数据类型 |
不可变数据类型 |
| 列表(list) | 数字类(bool,int,float,complex) |
| 字典(dict) | 字符串(str) |
| 集合(set) | 元组(tuple) |
| 不可变集合(frozenset) |
扩展数据类型
- namedtuple: 生成可以使用名字来访问元素内容的tuple子类
- deque:双端队列,可以快速的从另外一侧追加和推出对象
- counter:计数器,主要用来计数
- orderddict:有序字典
- defaultdict:带有默认值的字典

