
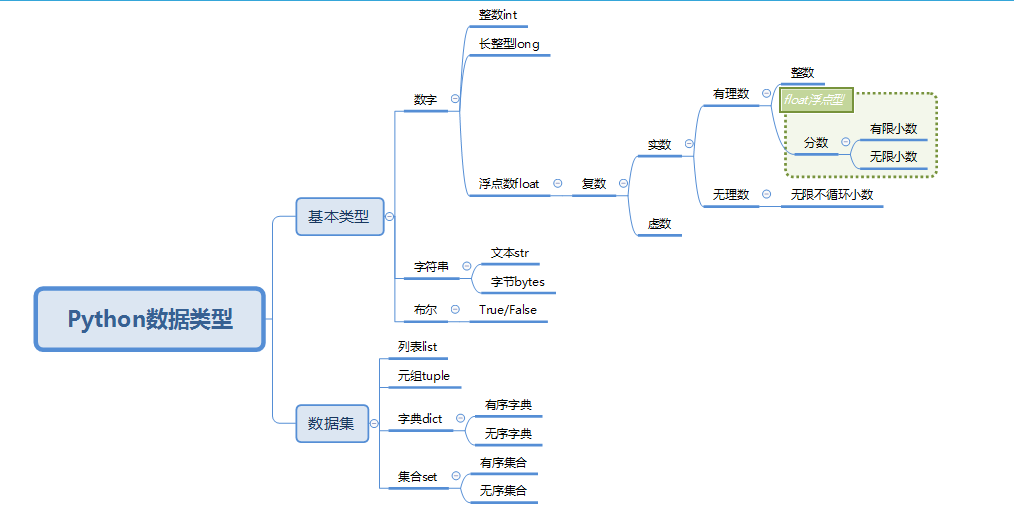
Python数据类型-基本数据类型
二进制与十进制转换
二进制:是用0和1两个数字来表示的数。
128 64 32 16 8 4 2 1
20 1 0 1 0 0
200 1 1 0 0 1 0 0 0
直接十进制转二进制:bin(20)
十进制转八进制: Oct(10)
十进制转十六制: hex(10)
字符编码
字符编码发展循序:
1、ascii码
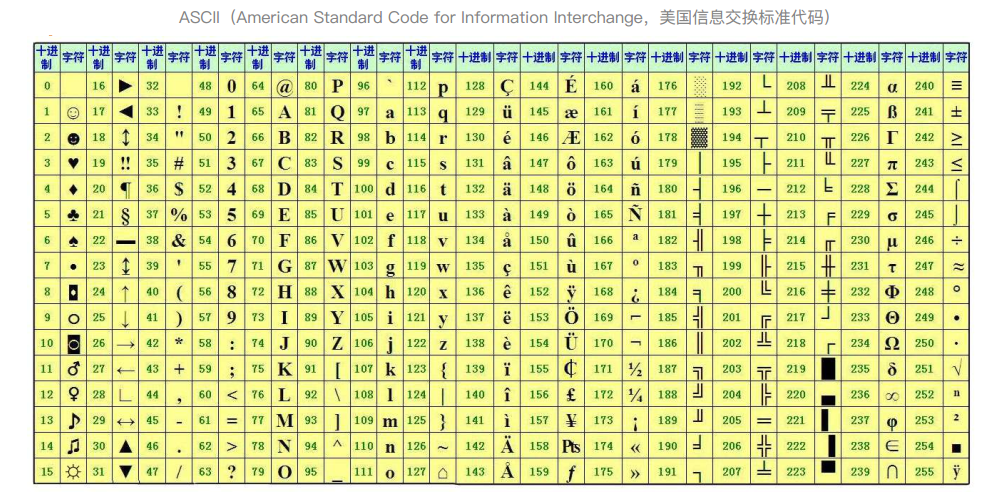
主要用于显示现代英语和其它西欧语言,它是现今最通用的单字节编码系统。
bit: 位,计算机中最小的表示单位
8bit: 字节,最小的存储单位,1bytes缩写为1B
ASCII对于因为程序员来说,圆满了,对于中文程序员来说,是不够的,于是有了gbk和gb2312
2、gbk和gb2312
一个字节只能最多表示256个字符,要处理中文显示一个字节是不够的,需要用两个字节表示,还不能和ASCII编码冲突,指定了gb2312
3、Unicode
Unicode把所有语言都同意到一套编码里面,解决乱码问题。
ASCII编码和Unicode编码的区别:
- ASCII编码是1个字节,而Unicode编码通常是2个字节
- 字母A用ASCII编码是十进制的65,二进制的01000001
- 字符0用ASCII编码是十进制的48,二进制的00110000
新的问题出现了,乱码是解决了,但是写的文本基本上全都是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间。
4、utf-8
为了节约存储空间,出现了“可变长编码”的utf-8编码。
utf-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字站用3个字节
基本数据类型-字符串
创建:
s = ‘Hello,Eva!How are you?’
字符串的特性:
按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序
常用操作:
1、索引
s = 'hello'
s[1] = 'e'
s[-1] = 'o'
s.index('e')=1
2、查找
s.find('e) = 1
s.find('i') = -1
3、移除空白
s = ‘ hello,Word!’
s.strip()
s.lstrip()
s.rstrip()
s2 = ***hello,world!***'
s2.strip('*')
4、长度
s = ' hello,Word!'
len(s)
5、替换
s = ' hello,Word!'
s.replace('h','H')
6、切片
s = 'abcdefghigklmn'
s[0:7] = 'abcdefg'
s[7:14] = 'higklmn'
s[:7] = 'abcdefg'
s[7:] = 'higklmn'
s[:] = 'abcdefghigklmn'
s[0:7:2] = 'aceg'
s[::2] = 'acegikm'
s[::-1] = 'nmlkgihgfedcba'
其它常用的:
s.capitallize() : 首字母变大写
str.isdigit() : 判断是否数字
str.find() :查找
str.join() :连接
str.replace() : 替换
str.count() :计数,顾头不顾尾,统计某个字符的个数,空格也算一个字符
str.strip() : 替换空白
str.center() :居中显示,不够用其它字符替换,比如print('欢迎登录'.center(20, '-) 显示为:--------欢迎登录--------
str.split() :分割,默认以空格分割。也可以以其他的字符分割
item1 = []
item = "www.luffycity.com"
item1 = item.split('.')
print(item1)
输出
['www', 'luffycity', 'com']
str.format() : 格式化输出
三种形式:
形式一:
print('{0}{1}{0}'.format('a', 'b'))
输出
aba
形式二:必须一一对应
print('{}{}'.format('a', 'b'))
输出:
ab
形式三:
print('{name} {age}'.format(age=18, name='lhf'))
输出:
lhf 18

 浙公网安备 33010602011771号
浙公网安备 33010602011771号