自动化测试框架设计探索 | 从筑基期到破碎虚空
文章过长提醒:该文跟懒婆娘的裹脚布一样——又臭又长
【背景音乐:那女孩对我说】
有天晚上,那女孩对你说,说她累了,不想再点点点了......
你暗自窃喜,曾几何时听过,有个叫selenium的方外之物,可模仿人操作,嗯,表现的机会来了
step 1 流水账 | 筑基期
需求:浏览器打开百度自动搜索“银魂”,并判断网页是否真的搜索到了
1、导入包
2、选择自动化浏览器,并打开百度
3、找到搜索框、输入文字、回车
4、关闭浏览器
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("银魂")
driver.find_element_by_id("su").click()
time.sleep(3)
# print(driver.page_source)
# 判断搜索结果在不在页面中,可以用assert,也可以自己写if语句判断
if "空知英秋" in driver.page_source:
print("success")
else:
print("fail")
driver.quit()
执行,成功,漂亮!

但是,你仿佛听见有人在说你写的代码很辣鸡。作为一个半小时憋不出一行代码的人来说,你感受到了前所未有的羞辱,所以,你决定开动已经不怎么灵光的脑袋。
step 2 定义函数 | 炼气化神
1、定义函数
2、调用函数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
def search_something():
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("银魂")
driver.find_element_by_id("su").click()
time.sleep(3)
source = driver.page_source
if "空知英秋" in source:
print("success")
else:
print("fial")
driver.quit()
search_something()
执行,依然成功,奶思!

正当你嘴角上扬,想要跟那个女孩疯狂炫耀的时候,又有个奇怪的声音传来,“如果搜索很多组东西,是不是无法做到?还是只知道copy代码?”复制?不存在的,因为就在那一瞬间,你已突破“炼气化神“境界。
step 3 数据驱动 | 炼神还虚
何谓数据驱动?通俗来讲,就是不修改函数、只变换数据,根据不同的数据,得到不同的预期值。例如,我要搜索不同的关键字,但是需要判断不同的内容会出现的页面里面,以确保结果是准确的。故而可将这两个变量作为数据,来驱动整个用例执行。大概可以用三种方式实现:1、for循环;2,ddt库;3、文本存储。(实际远远不止)
1、for循环
需求:
1.1、重定义函数,将关键字和断言内容参数化
1.2、定义循环内容,重复调用执行函数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
num = 0
fail_num = 0
suc_num = 0
def search_something(keyword, words):
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(3)
global num, fail_num, suc_num
num += 1
source = driver.page_source
if words in source:
print(f"搜索{keyword}成功")
suc_num += 1
else:
print(f"搜索{keyword}失败")
fail_num += 1
driver.quit()
data_list = [["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"]]
for i in range(len(data_list)):
search_something(data_list[i][0], data_list[i][1])
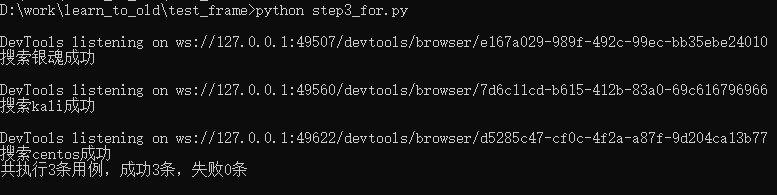
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
来来来,看看成效如何:
2、使用ddt库:
注意:因为这玩意儿只能和单元测试框架一起用,你写的时候一脸嫌弃
需求:
2.1、安装ddt库
2.2、定义数据,并调用ddt库引用
2.3、执行脚本
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
import unittest
from ddt import ddt,data,unpack
@ddt
class my_search(unittest.TestCase):
def setUp(self):
global num, fail_num, suc_num
num = 0
fail_num = 0
suc_num = 0
# data_list = [["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"]]
# 注意,这边传的各组参数要单独拿开(如下),如果跟上面这样传list,ddt会认为是一组参数,
# 比如@data(data_list)
# 需要注意的是,每次执行一组数据,整个类是重复执行一遍的,相当于循环执行这个类
@data(["银魂", "空知英秋"],["kali", "Kali Linux"], ["centos", "Red Hat"])
@unpack
def test_search(self, keyword, words):
self.driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
self.driver.get("https://www.baidu.com")
time.sleep(3)
self.driver.find_element_by_id("kw").send_keys(keyword)
self.driver.find_element_by_id("su").click()
time.sleep(3)
global num, fail_num, suc_num
num += 1
source = self.driver.page_source
if words in source:
print(f"搜索{keyword}成功")
suc_num += 1
else:
print(f"搜索{keyword}失败")
fail_num += 1
def tearDown(self):
self.driver.quit()
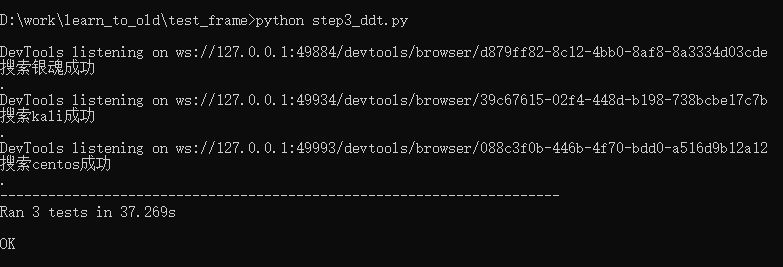
print(f"本次共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
if __name__ == "__main__":
unittest.main()
再来执行下:
3、自定义读取文档内容作为参数
3.1 定义好函数,这个在1.1里面已经弄好
3.2 with open打开文本,该文本有数据内容,详见step3_data.txt里面的内容
3.3 将读取的内容切片组装好,循环执行search_something函数
(因为与大部分与for循环一样,这里只贴更改的部分)
# with open(file_path,"r") as f 打开某个文件,并读取,“r“表示读取,”w"表示写入,'rb'表示读二进制文件,如图片等
# 切记:先将文本设置为utf-8,在复制中文进去,然后open要用encoding
with open("step3_data.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
print(lines)
for line in lines:
print(line.strip()) # strip() 去掉字符串末尾的\n
print(line.strip().split(",")) # 切片,用“,”来将字符串切成list
keyword_list = line.strip().split(",")
search_something(keyword_list[0], keyword_list[1])
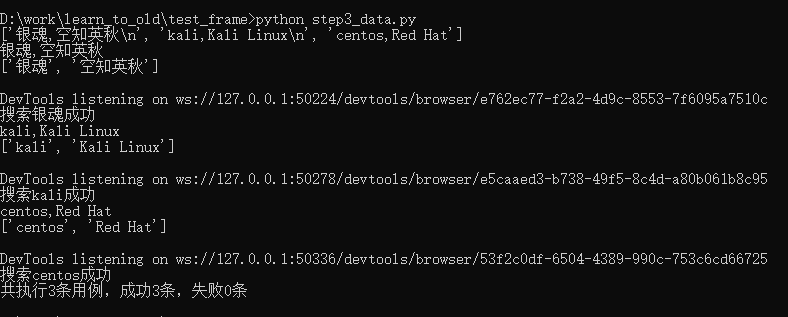
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
数据文本:

执行下:
写到这里,你忍不住暗夸自己惊才绝艳、非等闲之辈。那女孩肯定会多看你两眼。
等等,心思缜密的你盯着屏幕思考许久,还不够完美。姑娘不食人间烟火的模样还依稀浮现在你的脑海。或许可以做到类似自然语音描述测试步骤,这样那女孩即便不懂代码也能写自动化测试用例。也就是说,需要把所有的步骤都封装成函数,判断大部分可能性。
step 4 关键字驱动 还虚合道
什么是关键字驱动?简单来说,就是将想要的一些操作,封装成各种函数,当调用的时候,去匹配对应函数,从而达到简化用例描述的目的。
需求:
1、将每个步骤都定义为函数
2、在文本中描述测试步骤
3、读取步骤,并将其转为可以执行的命令(使用eval()函数)
4、执行
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from selenium import webdriver
import time
import sys
driver = None
num = 0
fail_num = 0
suc_num = 0
def choose_driver(driver_name):
global driver
if driver_name == "ie": # 注意if判断语句要用==
driver = webdriver.Ie(executable_path="D:\\work\\learn_to_old\\driver\\IEDriverServer.exe")
elif driver_name == "chrome":
driver = webdriver.Chrome(executable_path="D:\\work\\learn_to_old\\driver\\chromedriver.exe")
elif driver_name == "firefox":
driver = webdriver.Firefox(executable_path="D:\\work\\learn_to_old\\driver\\firefox.exe")
else:
print("选择的浏览器驱动有误,请重新选择!")
sys.exit()
def open_url(url):
global driver
driver.get(url)
def send_keywords(find_way, ele, keyword):
ele = find_ele(find_way, ele)
ele.send_keys(keyword)
def click(find_way, ele):
ele = find_ele(find_way, ele)
ele.click()
def sleep(sleep_seconds):
time.sleep(int(sleep_seconds))
# 封装元素查找方法,如果想获取list,则用find_elements_by_name之类
# 也可以用js来定位 driver.execute_script("document.getElementById('username')")
def find_ele(find_way, ele):
global driver
if find_way == "id":
ele = driver.find_element_by_id(ele)
# find_str = find_element_by_id
elif find_way == "name":
ele = driver.find_element_by_name(ele)
elif find_way == "xpath":
ele = driver.find_element_by_xpath(ele)
elif find_way == "link_text":
ele = driver.find_element_by_link_text(ele)
elif find_way == "partial_link_text":
ele = driver.find_element_by_partial_link_text(ele)
elif find_way == "tag_name":
ele = driver.find_element_by_tag_name(ele)
elif find_way == "class_name":
ele = driver.find_element_by_class_name(ele)
elif find_way == "css_selector":
ele = driver.find_element_by_css_selector(ele)
else:
print("元素查找方式有误,请修正!")
sys.exit()
return ele
def my_assert(words):
global driver, num, suc_num, fail_num
num += 1
source = driver.page_source
if words in source:
print(f"搜索{words}成功")
suc_num += 1
else:
print(f"搜索{words}失败")
fail_num += 1
def quit():
global driver
driver.quit()
# 2、使用步骤
# with open(file_path,"r") as f 打开某个文件,并读取,“r“表示读取,”w"表示写入,'rb'表示读二进制文件,如图片等
# 切记:先将文本设置为utf-8,在复制中文进去,然后open要用encoding
# 有两种方法可以将["open","xxx"]组装成'open("xxx")'
# 1、先定义模板str,使用replace()函数替换即可
# 2、直接使用格式化字符串方式替换,这里使用的是f"eeee{xxx}",其他%s或者format也可以,参考订阅号上次发布的文章
with open("step4_steps.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
# strs = "do_something()" 暂时不用此方法
for line in lines:
# print(type(line))
# 根据line.count('|')来判断,步骤可以更加简化
if "|" in line:
eval_str_list = line.strip().split("|")
# print("===========",eval_str_list)
if len(eval_str_list) == 2:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}')"
elif len(eval_str_list) == 3:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}')"
elif len(eval_str_list) == 4:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}')"
elif len(eval_str_list) == 5:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}', '{eval_str_list[4]}')"
elif len(eval_str_list) == 6:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}', '{eval_str_list[4]}', '{eval_str_list[5]}')"
else:
print("过长,需要优化程序")
print(eval_str_list,"*"*50)
print(eval_str)
eval(eval_str)
else:
# eval_str = strs.replace("do_something",line.strip())
eval_str = f"{line.strip()}()"
print(eval_str)
eval(eval_str)
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
用例描述为文本:
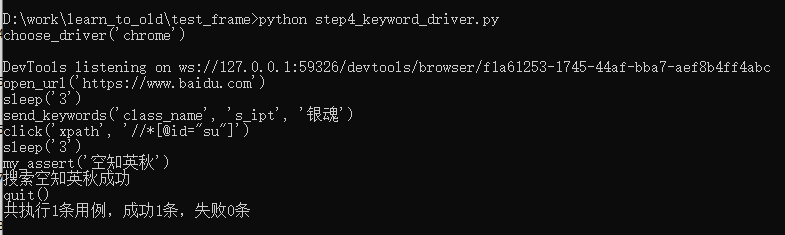
choose_driver|chrome open_url|https://www.baidu.com sleep|3 send_keywords|class_name|s_ipt|银魂 click|xpath|//*[@id="su"] sleep|3 my_assert|空知英秋 quit
执行结果:
嗯,又向前跨了一大步,你端着咖啡微眯着眼,虽然依稀能感受到头顶传来的阵阵凉意。
再向前跨一步吧,刚刚数据处理方式还是可以套用的,你放下手中的咖啡,摸了摸头发,又开始了。
step 5 混合驱动 | 破碎虚空
需求:
1、构造数据替换把位
2、使用正则将数据替换掉把位
3、执行
(因为大部分跟关键字驱动一样,这里只贴了部分,将open语句封装,以及后面部分逻辑)
def read_file_to_line(file_path):
with open(file_path, "r", encoding="utf-8") as f:
lines = f.readlines()
return lines
test_datas = read_file_to_line("step5_data.txt") #读取测试数据
for test_data in test_datas:
test_data = eval(test_data) # 将字符串转换为json,就不需要json.dump啥的了
test_steps = read_file_to_line("step5_steps.txt") # 读取测试步骤
for test_step in test_steps:
# 找到关键字“{{”,替换数据
if "${" in test_step:
# print("#"*10,type(test_step))
# 使用正则找到变量,$前面要加\,即便是字符串前用了r
key = re.search(r"\${(.*?)}", test_step).group(1)
# print("==== key ======",key)
# {{key}} value step 替换数据
test_step = re.sub(r"\${%s}" %key, test_data[key], test_step)
# print("#"*10,test_step)
# print(type(test_step))
# 根据line.count('|')来判断,步骤可以更加简化
if "|" in test_step:
eval_str_list = test_step.strip().split("|")
# print("===========",eval_str_list)
if len(eval_str_list) == 2:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}')"
elif len(eval_str_list) == 3:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}')"
elif len(eval_str_list) == 4:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}')"
elif len(eval_str_list) == 5:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}', '{eval_str_list[4]}')"
elif len(eval_str_list) == 6:
eval_str = f"{eval_str_list[0]}('{eval_str_list[1]}', '{eval_str_list[2]}', '{eval_str_list[3]}', '{eval_str_list[4]}', '{eval_str_list[5]}')"
else:
print("过长,需要优化程序")
print(eval_str_list,"*"*50)
else:
# eval_str = strs.replace("do_something",test_step.strip())
eval_str = f"{test_step.strip()}()"
print(eval_str)
# 异常处理
try:
eval(eval_str)
except Exception as e:
print(f"{e}")
print(f"共执行{num}条用例,成功{suc_num}条,失败{fail_num}条")
带把位的步骤:
choose_driver|chrome
open_url|https://www.baidu.com
sleep|3
send_keywords|class_name|s_ipt|${keyword}
click|xpath|//*[@id="su"]
sleep|3
my_assert|${assert_words}
quit
数据:
{"keyword":"银魂", "assert_words":"空知英秋"}
{"keyword":"kali", "assert_words":"Kali Linux"}
{"keyword":"centos", "assert_words":"Red Hat"}
执行:
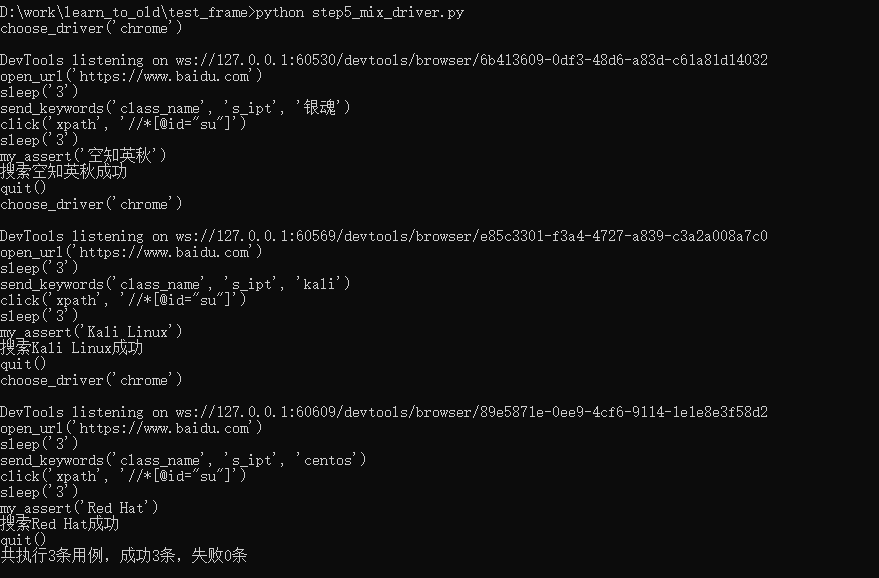
perfect!!!此刻你感觉人生已经到达巅峰了,生物本能驱动你立马寻找那个女孩,只是,四下望去,哪有什么女孩......
PS:本文涉及很多知识点,后续会一一补充,也欢迎反馈需要补充什么。
关注公众号,回复“测试框架设计”,即可获取所有代码。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号