hadoop安装与配置
设置2台服务器:
主机:master 192.168.0.252
从机:slave0 192.168.0.184
可以根据自己的实际情况设置多台从机slave1,slave2.....
每一个节点的安装与配置是相同的,在实际工作中,我们在主机master节点上完成安装和配置后,然后将安装目录复制到其他节点就可以,没有必要把所有节点都配置一遍,那样没有效率。
注意:所有操作都是root用户权限
1、下载hadoop包(只在master做)
访问hadoop官网地址http://hadoop.apache.org/
centos下目前最新下载是wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
2、解压(只在master做)
直接把hadoop-3.2.2.tar.gz放在/opt下
解压 tar -zxf hadoop-3.2.2.tar.gz
解压之后将文件夹重命名为hadoop mv hadoop-3.2.2 hadoop

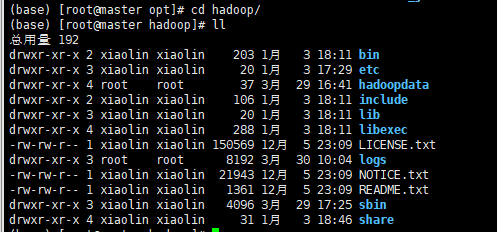
进入安装目录查看(hadoopdata是在后面第11操作中加上去的),有以下目录表示安装成功
3、配置env文件hadoop-env.sh(只在master做)
配置jdk文件vim /opt/hadoop/etc/hadoop/hadoop-env.sh

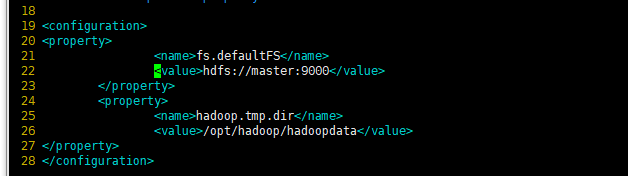
4、配置核心组件文件core-site.xml(只在master做)
vim /opt/hadoop/etc/hadoop/core-site.xml,在<configuration>和</configuration>之间加入如下代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
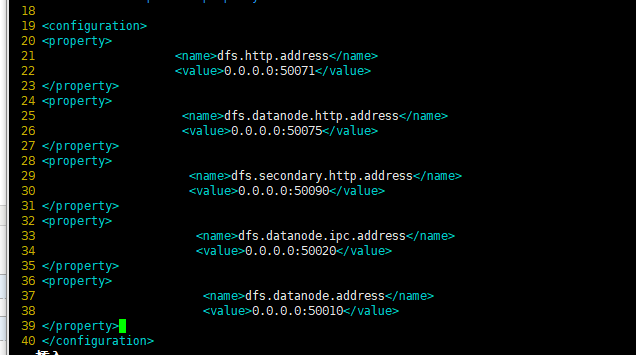
5、配置文件系统hdfs-site.xml(只在master做)这里就是hadoop的默认web访问端口修改的地方,默认是50070、50075、50090
vim /opt/hadoop/etc/hadoop/hdfs-site.xml,在<configuration>和</configuration>之间加入如下代码:
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50071</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>0.0.0.0:50090</value>
</property>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50010</value>
</property>
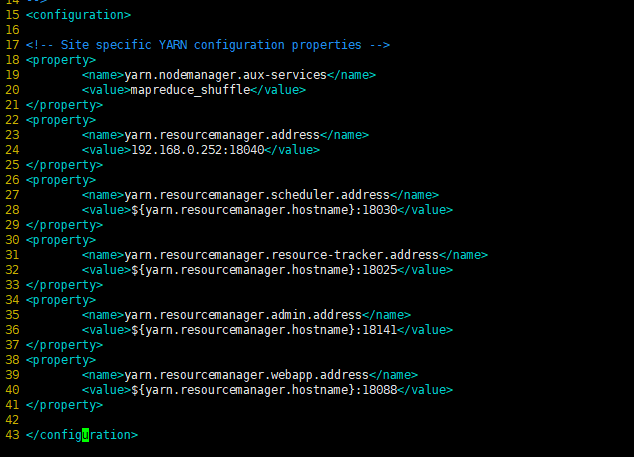
6、配置Yarn的站点配置文件yarn-site.xml(只在master做)
vim /opt/hadoop/etc/hadoop/yarn-site.xml,在<configuration>和</configuration>之间加入如下代码:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.252:18040</value> 百度搜的这里都是配置的master,而不是具体的ip,不知道为什么没有调用master成功,配置ip就可以
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:18088</value> 这里就是yarn的默认访问端口8088,修改为其他端口去访问yarn页面
</property>
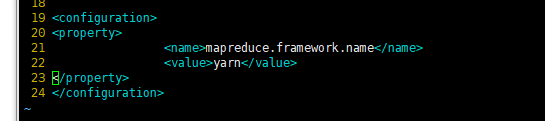
7、配置MapReduce计算框架文件mapred-site.xml(只在master做)
vim /opt/hadoop/etc/hadoop/mapred-site.xml,在<configuration>和</configuration>之间加入如下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
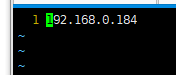
8、配置master的slaves文件(只在master做)
vim /opt/hadoop/etc/hadoop/slaves
注意:用vi或vim编辑slaves文件,根据自己所搭建集群的实际情况进行编辑。
比如我只安装了slave0
所以应当加入以下代码:
9、复制master上的Hadoop到slave节点(只在master做)
复制命令如下:
scp -r /opt/hadoop root@192.168.0.184:/opt会提示要你输入184的密码,如果有多台slave节点,就再次scp到其他ip就行
10、Hadoop集群的启动-配置操作系统环境变量(主机和从机节点都做)
回到hadoop主目录 cd /opt/hadoop
然后用vi或vim编辑.bash_profile文件 vim ~/.bash_profile ,把以下代码追加到文件的尾部
#HADOOP
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

保存退出后执行命令source ~/.bash_profile,使上述配置生效
注意:主机和从机节点都要配置
11、创建Hadoop数据目录(只在master做)
mkdir /opt/hadoop/hadoopdata
12、格式化文件系统(只在master做)
hadoop namenode -format
13、配置start-all.sh、stop-all.sh,添加以下参数:(这一步没操作执行第14步就会报错,百度搜解决办法)
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

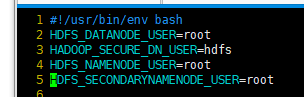
配置start-dfs.sh、stop-dfs.sh,添加以下参数:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
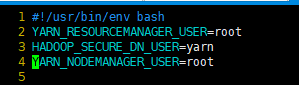
配置start-yarn.sh、stop-yarn.sh,添加以下参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
14、启动和关闭Hadoop集群(只在master做)
cd /opt/hadoop/sbin
启动命令:start-all.sh
停止命令:stop-all.sh
百度解释:下次启动Hadoop时,无须NameNode的初始化,只需要使用start-dfs.sh命令即可,然后接着使用start-yarn.sh启动Yarn。
实际上,Hadoop建议放弃(deprecated)使用start-all.sh和stop-all.sh一类的命令,而改用start-dfs.sh和start-yarn.sh命令。
但实际上我每次启动直接用的start-all.sh和stop-all.sh
出现的Hadoop错误:ssh: Could not resolve hostname master: Name or service not known,解决办法如下:
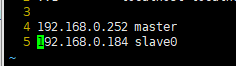
vim /etc/hosts,将主机和从机配置进去
15、验证Hadoop集群是否启动成功
首先在master做,输入jps,只要有以下4个进程(SecondaryNameNode、 ResourceManager、 Jps 和NameNode)表示主节点master启动成功,平时如果删进程也是用kill -9 进程号
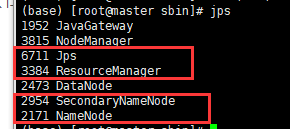
然后在从机184上输入jps,只要有以下3个进程(NodeManager、Jps 和 DataNode)表明从节点(slave0)启动成功
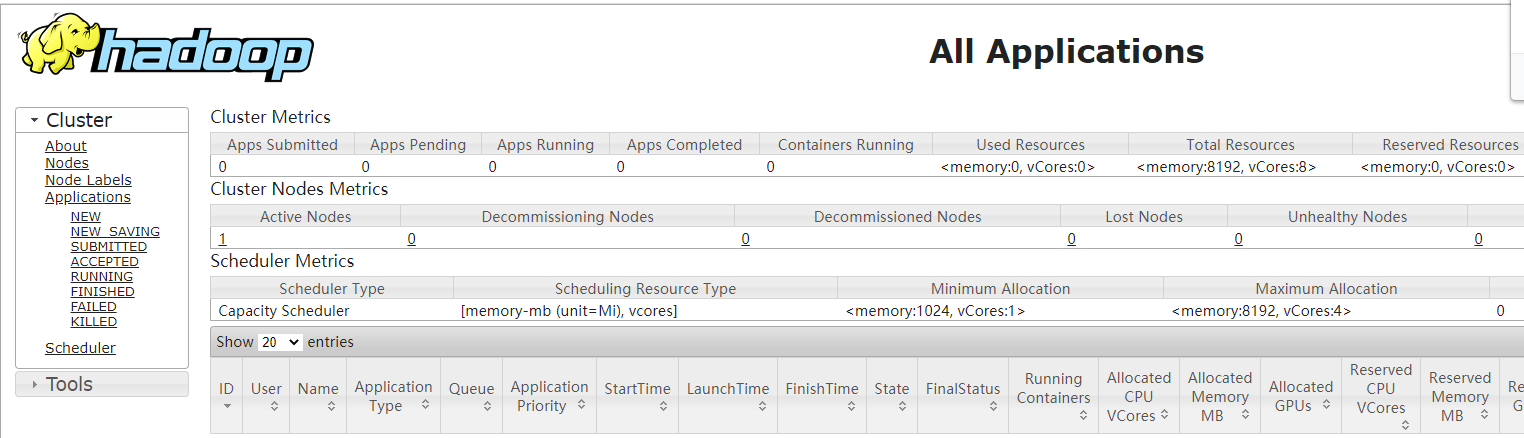
16、访问页面
第5步中的hdfs配置端口50071访问:http://192.168.0.252:50071
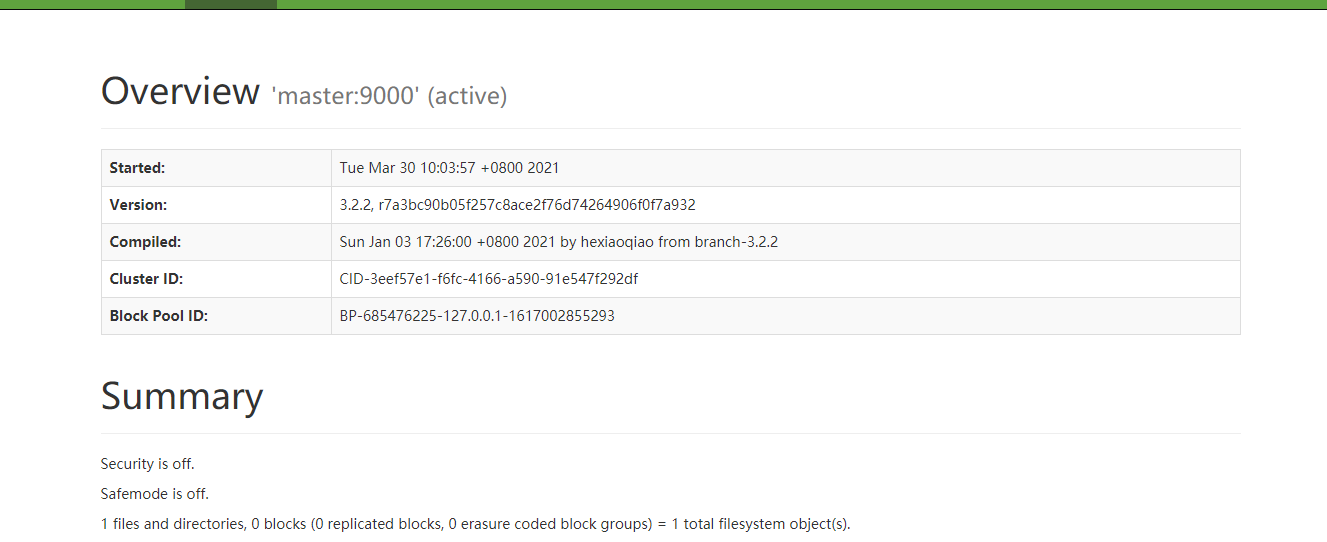
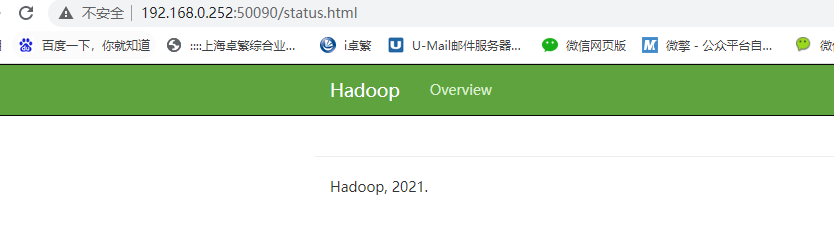
访问http://192.168.0.252:50090
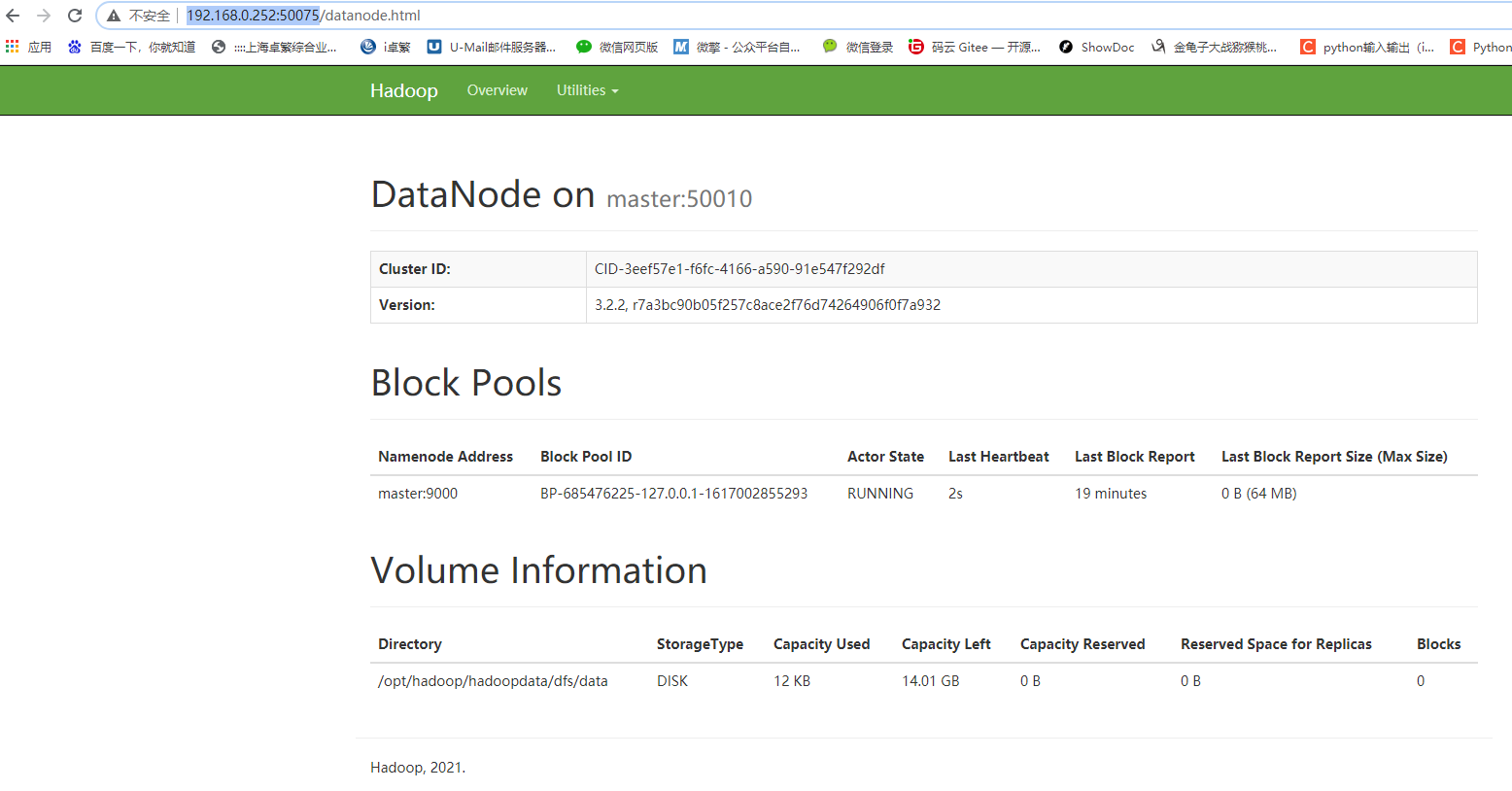
访问http://192.168.0.252:50075
第6步中的yarn配置端口18088,访问http://192.168.0.252:18088