



6.824 Lab 2: Raft 2A
6.824 Lab 2: Raft
Part 2A Due: Feb 23 at 11:59pm
Part 2B Due: Mar 2 at 11:59pm
Part 2C Due: Mar 9 at 11:59pm
Introduction
This is the first in a series of labs in which you'll build a fault-tolerant key/value storage system. In this lab you'll implement Raft, a replicated state machine protocol. In the next lab you'll build a key/value service on top of Raft. Then you will “shard” your service over multiple replicated state machines for higher performance.
A replicated service achieves fault tolerance by storing complete copies of its state (i.e., data) on multiple replica servers. Replication allows the service to continue operating even if some of its servers experience failures (crashes or a broken or flaky network). The challenge is that failures may cause the replicas to hold differing copies of the data.
Raft manages a service's state replicas, and in particular it helps the service sort out what the correct state is after failures. Raft implements a replicated state machine. It organizes client requests into a sequence, called the log, and ensures that all the replicas agree on the contents of the log. Each replica executes the client requests in the log in the order they appear in the log, applying those requests to the replica's local copy of the service's state. Since all the live replicas see the same log contents, they all execute the same requests in the same order, and thus continue to have identical service state. If a server fails but later recovers, Raft takes care of bringing its log up to date. Raft will continue to operate as long as at least a majority of the servers are alive and can talk to each other. If there is no such majority, Raft will make no progress, but will pick up where it left off as soon as a majority can communicate again.
In this lab you'll implement Raft as a Go object type with associated methods, meant to be used as a module in a larger service. A set of Raft instances talk to each other with RPC to maintain replicated logs. Your Raft interface will support an indefinite sequence of numbered commands, also called log entries. The entries are numbered with index numbers. The log entry with a given index will eventually be committed. At that point, your Raft should send the log entry to the larger service for it to execute.
Your Raft instances are only allowed to interact using RPC. For example, different Raft instances are not allowed to share Go variables. Your code should not use files at all.
You should consult the extended Raft paper and the Raft lecture notes. You may find it useful to look at this illustration of the Raft protocol, a guide to Raft implementation written for 6.824 students in 2016, and advice about locking and structure for concurrency. For a wider perspective, have a look at Paxos, Chubby, Paxos Made Live, Spanner, Zookeeper, Harp, Viewstamped Replication, and Bolosky et al.
In this lab you'll implement most of the Raft design described in the extended paper, including saving persistent state and reading it after a node fails and then restarts. You will not implement cluster membership changes (Section 6) or log compaction / snapshotting (Section 7).
- Start early. Although the amount of code isn't large, getting it to work correctly will be challenging.
- Read and understand the extended Raft paper and the Raft lecture notes before you start. Your implementation should follow the paper's description closely, particularly Figure 2, since that's what the tests expect.
This lab is due in three parts. You must submit each part on the corresponding due date. This lab does not involve a lot of code, but concurrency makes it challenging to debug; start each part early.
Getting Started
If you have done Lab 1, you already have a copy of the lab source code. If not, you can find directions for obtaining the source via git in the Lab 1 instructions.
Do a git pull to get the latest lab software.
We supply you with skeleton code and tests in src/raft, and a simple RPC-like system in src/labrpc.
To get up and running, execute the following commands:
$ cd ~/6.824
$ git pull
...
$ cd src/raft
$ GOPATH=~/6.824
$ export GOPATH
$ go test
Test (2A): initial election ...
--- FAIL: TestInitialElection2A (5.04s)
config.go:305: expected one leader, got none
Test (2A): election after network failure ...
--- FAIL: TestReElection2A (5.03s)
config.go:305: expected one leader, got none
...
$
The code
Implement Raft by adding code to raft/raft.go. In that file you'll find a bit of skeleton code, plus examples of how to send and receive RPCs.
Your implementation must support the following interface, which the tester and (eventually) your key/value server will use. You'll find more details in comments in raft.go.
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer should send an ApplyMsg to the service (or tester).
type ApplyMsg
A service calls Make(peers,me,…) to create a Raft peer. The peers argument is an array of network identifiers of the Raft peers (including this one), for use with labrpc RPC. The me argument is the index of this peer in the peers array. Start(command) asks Raft to start the processing to append the command to the replicated log. Start() should return immediately, without waiting for the log appends to complete. The service expects your implementation to send an ApplyMsg for each newly committed log entry to the applyCh argument to Make().
Your Raft peers should exchange RPCs using the labrpc Go package that we provide to you. It is modeled after Go's rpc library, but internally uses Go channels rather than sockets. raft.go contains some example code that sends an RPC (sendRequestVote()) and that handles an incoming RPC (RequestVote()).
The reason you must use labrpc instead of Go's RPC package is that the tester tells labrpc to delay RPCs, re-order them, and delete them to simulate challenging network conditions under which your code should work correctly. Don't rely on modifications to labrpc because we will test your code with the labrpc as handed out.
Your first implementation may not be clean enough that you can easily reason about its correctness. Give yourself enough time to rewrite your implementation so that you can easily reason about its correctness. Subsequent labs will build on this lab, so it is important to do a good job on your implementation.
Part 2A
Implement leader election and heartbeats (AppendEntries RPCs with no log entries). The goal for Part 2A is for a single leader to be elected, for the leader to remain the leader if there are no failures, and for a new leader to take over if the old leader fails or if packets to/from the old leader are lost. Run go test -run 2A to test your 2A code.
实现领导人选举和心跳。第2A部分的目标是选出一个leader,如果没有失败,则leader继续担任leader,如果旧leader失败,或者发送给/接收旧leader的包丢失,则由新leader接管。
- Add any state you need to the Raft struct in raft.go. You'll also need to define a struct to hold information about each log entry. Your code should follow Figure 2 in the paper as closely as possible.你可以增加任意状态在Raft 结构,您还需要定义一个结构来保存关于每个日志条目的信息。您的代码应该尽可能地遵循论文中的图2。
- Fill in the RequestVoteArgs and RequestVoteReply structs. Modify Make() to create a background goroutine that will kick off leader election periodically by sending out RequestVote RPCs when it hasn't heard from another peer for a while. This way a peer will learn who is the leader, if there is already a leader, or become the leader itself. Implement the RequestVote() RPC handler so that servers will vote for one another.填充RequestVoteArgs和RequestVoteReply结构,修改Make()以创建一个后台goroutine,当它有一段时间没有收到其他peer的消息时,通过发送RequestVote rpc来定期启动领导人选举。这样同伴就会知道谁是领导者,如果已经有了领导者,或者成为领导者本身。实现RequestVote() RPC处理程序,以便服务器可以为彼此投票。
- To implement heartbeats, define an AppendEntries RPC struct (though you may not need all the arguments yet), and have the leader send them out periodically. Write an AppendEntries RPC handler method that resets the election timeout so that other servers don't step forward as leaders when one has already been elected.
- Make sure the election timeouts in different peers don't always fire at the same time, or else all peers will vote only for themselves and no one will become the leader.
- The tester requires that the leader send heartbeat RPCs no more than ten times per second.
- The tester requires your Raft to elect a new leader within five seconds of the failure of the old leader (if a majority of peers can still communicate). Remember, however, that leader election may require multiple rounds in case of a split vote (which can happen if packets are lost or if candidates unluckily choose the same random backoff times). You must pick election timeouts (and thus heartbeat intervals) that are short enough that it's very likely that an election will complete in less than five seconds even if it requires multiple rounds.
- The paper's Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds. Because the tester limits you to 10 heartbeats per second, you will have to use an election timeout larger than the paper's 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
- You may find Go's rand useful.
- You'll need to write code that takes actions periodically or after delays in time. The easiest way to do this is to create a goroutine with a loop that calls time.Sleep(). The hard way is to use Go's time.Timer or time.Ticker, which are difficult to use correctly.
- If you are puzzled about locking, you may find this advice helpful.
- If your code has trouble passing the tests, read the paper's Figure 2 again; the full logic for leader election is spread over multiple parts of the figure.
- A good way to debug your code is to insert print statements when a peer sends or receives a message, and collect the output in a file with go test -run 2A > out. Then, by studying the trace of messages in the out file, you can identify where your implementation deviates from the desired protocol. You might find DPrintf in util.go useful to turn printing on and off as you debug different problems.
- Go RPC sends only struct fields whose names start with capital letters. Sub-structures must also have capitalized field names (e.g. fields of log records in an array). The labgob package will warn you about this; don't ignore the warnings.
- You should check your code with go test -race, and fix any races it reports.
Be sure you pass the 2A tests before submitting Part 2A, so that you see something like this:
$ go test -run 2A
Test (2A): initial election ...
... Passed -- 2.5 3 30 0
Test (2A): election after network failure ...
... Passed -- 4.5 3 78 0
PASS
ok raft 7.016s
$
Each "Passed" line contains four numbers; these are the time that the test took in seconds, the number of Raft peers (usually 3 or 5), the number of RPCs sent during the test, and the number of log entries that Raft reports were committed. Your numbers will differ from those shown here. You can ignore the numbers if you like, but they may help you sanity-check the number of RPCs that your implementation sends. For all of labs 2, 3, and 4, the grading script will fail your solution if it takes more than 600 seconds for all of the tests (go test), or if any individual test takes more than 120 seconds.
Parts B and C will test leader election in more challenging settings and may expose bugs in your leader election code which the 2A tests miss.
Handin procedure for lab 2A
Before submitting, please run the 2A tests one final time. Some bugs may not appear on every run, so run the tests multiple times.
Submit your code via the class's submission website, located at https://6824.scripts.mit.edu/2018/handin.py/.
You may use your MIT Certificate or request an API key via email to log in for the first time. Your API key (XXX) is displayed once you are logged in, which can be used to upload the lab from the console as follows.
$ cd "$GOPATH"
$ echo "XXX" > api.key
$ make lab2a
Check the submission website to make sure it sees your submission!
You may submit multiple times. We will use the timestamp of your last submission for the purpose of calculating late days. Your grade is determined by the score your solution reliably achieves when we run the tester on our test machines.
my homework code:
package raft // // this is an outline of the API that raft must expose to // the service (or tester). see comments below for // each of these functions for more details. // // rf = Make(...) // create a new Raft server. // rf.Start(command interface{}) (index, term, isleader) // start agreement on a new log entry // rf.GetState() (term, isLeader) // ask a Raft for its current term, and whether it thinks it is leader // ApplyMsg // each time a new entry is committed to the log, each Raft peer // should send an ApplyMsg to the service (or tester) // in the same server. // import ( "labrpc" "math/rand" "sync" "time" ) // import "bytes" // import "labgob" // // as each Raft peer becomes aware that successive log entries are // committed, the peer should send an ApplyMsg to the service (or // tester) on the same server, via the applyCh passed to Make(). set // CommandValid to true to indicate that the ApplyMsg contains a newly // committed log entry. // // in Lab 3 you'll want to send other kinds of messages (e.g., // snapshots) on the applyCh; at that point you can add fields to // ApplyMsg, but set CommandValid to false for these other uses. // type ApplyMsg struct { CommandValid bool Command interface{} CommandIndex int } // // log entry contains command for state machine, and term when entry // was received by leader // type LogEntry struct { Command interface{} Term int } const ( Follower = 1 Candidate = 2 Leader = 3 HEART_BEAT_TIMEOUT = 100 //心跳超时,要求1秒10次,所以是100ms一次 ) // // A Go object implementing a single Raft peer. // type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int // this peer's index into peers[] // Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain. timer *time.Timer //定时器 timeout time.Duration //选举超时周期 election timeout state int //角色 appendCh chan bool //心跳 voteCh chan bool voteCount int currentTerm int //latest term server has seen (initialized to 0 on first boot, increases monotonically) votedFor int //candidateId that received vote in current term (or null if none) log []LogEntry //log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1) //Volatile state on all servers: commitIndex int //index of highest log entry known to be committed (initialized to 0, increases monotonically) lastApplied int //index of highest log entry applied to state machine (initialized to 0, increases monotonically) //Volatile state on leaders:(Reinitialized after election) nextIndex []int //for each server, index of the next log entry to send to that server (initialized to leader last log index + 1) matchIndex []int //for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically) } // return currentTerm and whether this server // believes it is the leader. func (rf *Raft) GetState() (int, bool) { var term int var isleader bool // Your code here (2A). rf.mu.Lock() term = rf.currentTerm isleader = rf.state == Leader rf.mu.Unlock() return term, isleader } // // save Raft's persistent state to stable storage, // where it can later be retrieved after a crash and restart. // see paper's Figure 2 for a description of what should be persistent. // func (rf *Raft) persist() { // Your code here (2C). // Example: // w := new(bytes.Buffer) // e := labgob.NewEncoder(w) // e.Encode(rf.xxx) // e.Encode(rf.yyy) // data := w.Bytes() // rf.persister.SaveRaftState(data) } // // restore previously persisted state. // func (rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } // Your code here (2C). // Example: // r := bytes.NewBuffer(data) // d := labgob.NewDecoder(r) // var xxx // var yyy // if d.Decode(&xxx) != nil || // d.Decode(&yyy) != nil { // error... // } else { // rf.xxx = xxx // rf.yyy = yyy // } } // // example RequestVote RPC arguments structure. // field names must start with capital letters! // type RequestVoteArgs struct { // Your data here (2A, 2B). Term int //candidate’s term CandidateId int //candidate requesting vote LastLogIndex int //index of candidate’s last log entry (§5.4) LastLogTerm int //term of candidate’s last log entry (§5.4) } // // example RequestVote RPC reply structure. // field names must start with capital letters! // type RequestVoteReply struct { // Your data here (2A). Term int //currentTerm, for candidate to update itself VoteGranted bool //true means candidate received vote } // // example RequestVote RPC handler. // func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (2A, 2B). rf.mu.Lock() defer rf.mu.Unlock() DPrintf("Candidate[raft%v][term:%v] request vote: raft%v[%v] 's term%v\n", args.CandidateId, args.Term, rf.me, rf.state, rf.currentTerm) reply.VoteGranted = false //Reply false if term < currentTerm if args.Term < rf.currentTerm { DPrintf("raft%v don't vote for raft%v\n", rf.me, args.CandidateId) reply.Term = rf.currentTerm reply.VoteGranted = false return } //If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.switchStateTo(Follower) } //If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote if rf.votedFor == -1 || rf.votedFor == args.CandidateId /*&& (rf.lastApplied == args.lastLogIndex && rf.log[rf.lastApplied].term == args.lastLogTerm) */ { DPrintf("raft%v vote for raft%v\n", rf.me, args.CandidateId) reply.VoteGranted = true rf.votedFor = args.CandidateId } reply.Term = rf.currentTerm go func() { rf.voteCh <- true }() } type AppendEntriesArgs struct { Term int //leader’s term LeaderId int //so follower can redirect clients PrevLogIndex int //index of log entry immediately preceding new ones PrevLogTerm int //term of prevLogIndex entry Entries []LogEntry //log entries to store (empty for heartbeat; may send more than one for efficiency) LeaderCommit int //leader’s commitIndex } type AppendEntriesReply struct { Term int //currentTerm, for leader to update itself Success bool //true if follower contained entry matching prevLogIndex and prevLogTerm } func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) { rf.mu.Lock() defer rf.mu.Unlock() DPrintf("leader[raft%v][term:%v] beat term:%v [raft%v][%v]\n", args.LeaderId, args.Term, rf.currentTerm, rf.me, rf.state) reply.Success = true if args.Term < rf.currentTerm { // Reply false if term < currentTerm (§5.1) reply.Success = false reply.Term = rf.currentTerm return } else if args.Term > rf.currentTerm { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.currentTerm = args.Term rf.switchStateTo(Follower) } go func() { rf.appendCh <- true }() } func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool { ok := rf.peers[server].Call("Raft.AppendEntries", args, reply) return ok } // // example code to send a RequestVote RPC to a server. // server is the index of the target server in rf.peers[]. // expects RPC arguments in args. // fills in *reply with RPC reply, so caller should // pass &reply. // the types of the args and reply passed to Call() must be // the same as the types of the arguments declared in the // handler function (including whether they are pointers). // // The labrpc package simulates a lossy network, in which servers // may be unreachable, and in which requests and replies may be lost. // Call() sends a request and waits for a reply. If a reply arrives // within a timeout interval, Call() returns true; otherwise // Call() returns false. Thus Call() may not return for a while. // A false return can be caused by a dead server, a live server that // can't be reached, a lost request, or a lost reply. // // Call() is guaranteed to return (perhaps after a delay) *except* if the // handler function on the server side does not return. Thus there // is no need to implement your own timeouts around Call(). // // look at the comments in ../labrpc/labrpc.go for more details. // // if you're having trouble getting RPC to work, check that you've // capitalized all field names in structs passed over RPC, and // that the caller passes the address of the reply struct with &, not // the struct itself. // func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool { ok := rf.peers[server].Call("Raft.RequestVote", args, reply) return ok } // // the service using Raft (e.g. a k/v server) wants to start // agreement on the next command to be appended to Raft's log. if this // server isn't the leader, returns false. otherwise start the // agreement and return immediately. there is no guarantee that this // command will ever be committed to the Raft log, since the leader // may fail or lose an election. even if the Raft instance has been killed, // this function should return gracefully. // // the first return value is the index that the command will appear at // if it's ever committed. the second return value is the current // term. the third return value is true if this server believes it is // the leader. // func (rf *Raft) Start(command interface{}) (int, int, bool) { index := -1 term := -1 isLeader := true // Your code here (2B). return index, term, isLeader } // // the tester calls Kill() when a Raft instance won't // be needed again. you are not required to do anything // in Kill(), but it might be convenient to (for example) // turn off debug output from this instance. // func (rf *Raft) Kill() { // Your code here, if desired. } // // the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. // func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft { rf := &Raft{} rf.peers = peers rf.persister = persister rf.me = me // Your initialization code here (2A, 2B, 2C). DPrintf("create raft%v...", me) rf.state = Follower rf.currentTerm = 0 rf.votedFor = -1 rf.voteCh = make(chan bool) rf.appendCh = make(chan bool) electionTimeout := HEART_BEAT_TIMEOUT*3 + rand.Intn(HEART_BEAT_TIMEOUT) rf.timeout = time.Duration(electionTimeout) * time.Millisecond DPrintf("raft%v's election timeout is:%v\n", rf.me, rf.timeout) rf.timer = time.NewTimer(rf.timeout) go func() { for { rf.mu.Lock() state := rf.state rf.mu.Unlock() electionTimeout := HEART_BEAT_TIMEOUT*3 + rand.Intn(HEART_BEAT_TIMEOUT) rf.timeout = time.Duration(electionTimeout) * time.Millisecond switch state { case Follower: //如果在选举超时之前都没有收到领导人的心跳,或者是候选人的投票请求,就自己变成候选人 select { case <-rf.appendCh: rf.timer.Reset(rf.timeout) case <-rf.voteCh: rf.timer.Reset(rf.timeout) case <-rf.timer.C: rf.mu.Lock() rf.switchStateTo(Candidate) rf.mu.Unlock() //变成候选人立马进行选举 rf.startElection() } case Candidate: select { case <-rf.appendCh: rf.timer.Reset(rf.timeout) rf.mu.Lock() rf.switchStateTo(Follower) rf.mu.Unlock() case <-rf.timer.C: rf.startElection() default: rf.mu.Lock() if rf.voteCount > len(rf.peers)/2 { rf.switchStateTo(Leader) } rf.mu.Unlock() } case Leader: //heartbeats rf.heartbeats() } } }() // initialize from state persisted before a crash rf.readPersist(persister.ReadRaftState()) return rf } //发送心跳包 func (rf *Raft) heartbeats() { for peer, _ := range rf.peers { if peer != rf.me { go func(peer int) { args := AppendEntriesArgs{} rf.mu.Lock() args.Term = rf.currentTerm args.LeaderId = rf.me rf.mu.Unlock() reply := AppendEntriesReply{} if rf.sendAppendEntries(peer, &args, &reply) { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.mu.Lock() if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.switchStateTo(Follower) } rf.mu.Unlock() } }(peer) } } time.Sleep(HEART_BEAT_TIMEOUT * time.Millisecond) } //切换状态,调用者需要加锁 func (rf *Raft) switchStateTo(state int) { if rf.state == state { return } if state == Follower { rf.state = Follower DPrintf("raft%v become follower in term:%v\n", rf.me, rf.currentTerm) rf.votedFor = -1 } if state == Candidate { DPrintf("raft%v become candidate in term:%v\n", rf.me, rf.currentTerm) rf.state = Candidate } if state == Leader { rf.state = Leader DPrintf("raft%v become leader in term:%v\n", rf.me, rf.currentTerm) } } func (rf *Raft) startElection() { rf.mu.Lock() // DPrintf("raft%v is starting election\n", rf.me) rf.currentTerm += 1 rf.votedFor = rf.me //vote for me rf.timer.Reset(rf.timeout) rf.voteCount = 1 rf.mu.Unlock() for peer, _ := range rf.peers { if peer != rf.me { go func(peer int) { rf.mu.Lock() args := RequestVoteArgs{} args.Term = rf.currentTerm args.CandidateId = rf.me // DPrintf("raft%v[%v] is sending RequestVote RPC to raft%v\n", rf.me, rf.state, peer) rf.mu.Unlock() reply := RequestVoteReply{} if rf.sendRequestVote(peer, &args, &reply) { rf.mu.Lock() if reply.VoteGranted { rf.voteCount += 1 } else if reply.Term > rf.currentTerm { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.currentTerm = reply.Term rf.switchStateTo(Follower) } rf.mu.Unlock() } else { // DPrintf("raft%v[%v] vote:raft%v no reply, currentTerm:%v\n", rf.me, rf.state, peer, rf.currentTerm) } }(peer) } } }
test result
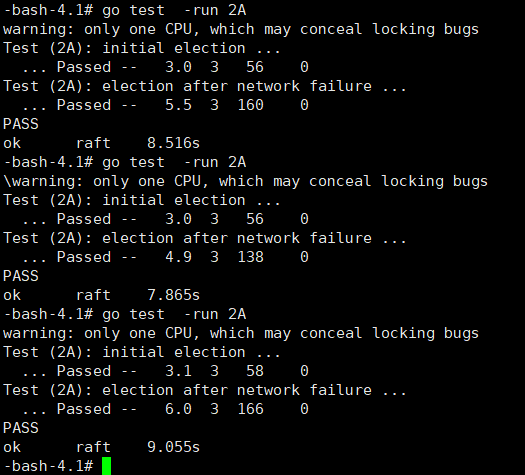
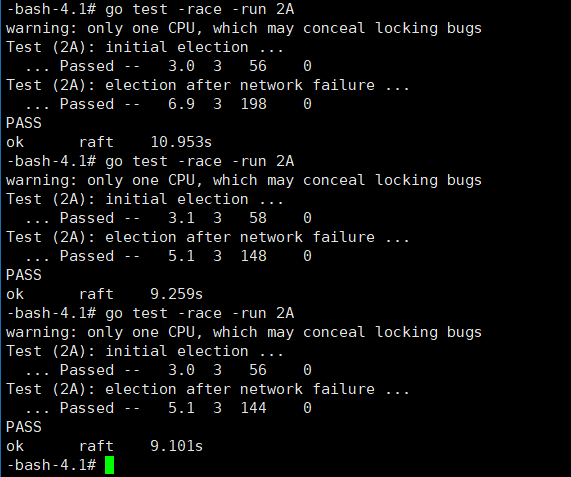
test -race result
以定时器的维度重写一版
package raft // // this is an outline of the API that raft must expose to // the service (or tester). see comments below for // each of these functions for more details. // // rf = Make(...) // create a new Raft server. // rf.Start(command interface{}) (index, term, isleader) // start agreement on a new log entry // rf.GetState() (term, isLeader) // ask a Raft for its current term, and whether it thinks it is leader // ApplyMsg // each time a new entry is committed to the log, each Raft peer // should send an ApplyMsg to the service (or tester) // in the same server. // import ( "labrpc" "math/rand" "sync" "time" ) // import "bytes" // import "labgob" // // as each Raft peer becomes aware that successive log entries are // committed, the peer should send an ApplyMsg to the service (or // tester) on the same server, via the applyCh passed to Make(). set // CommandValid to true to indicate that the ApplyMsg contains a newly // committed log entry. // // in Lab 3 you'll want to send other kinds of messages (e.g., // snapshots) on the applyCh; at that point you can add fields to // ApplyMsg, but set CommandValid to false for these other uses. // type ApplyMsg struct { CommandValid bool Command interface{} CommandIndex int } // // log entry contains command for state machine, and term when entry // was received by leader // type LogEntry struct { Command interface{} Term int } const ( Follower = 1 Candidate = 2 Leader = 3 HEART_BEAT_TIMEOUT = 100 //心跳超时,要求1秒10次,所以是100ms一次 ) // // A Go object implementing a single Raft peer. // type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int // this peer's index into peers[] // Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain. electionTimer *time.Timer // 选举定时器 heartbeatTimer *time.Timer // 心跳定时器 state int // 角色 voteCount int //投票数 currentTerm int //latest term server has seen (initialized to 0 on first boot, increases monotonically) votedFor int //candidateId that received vote in current term (or null if none) log []LogEntry //log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1) //Volatile state on all servers: commitIndex int //index of highest log entry known to be committed (initialized to 0, increases monotonically) lastApplied int //index of highest log entry applied to state machine (initialized to 0, increases monotonically) //Volatile state on leaders:(Reinitialized after election) nextIndex []int //for each server, index of the next log entry to send to that server (initialized to leader last log index + 1) matchIndex []int //for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically) } // return currentTerm and whether this server // believes it is the leader. func (rf *Raft) GetState() (int, bool) { var term int var isleader bool // Your code here (2A). rf.mu.Lock() term = rf.currentTerm isleader = rf.state == Leader rf.mu.Unlock() return term, isleader } // // save Raft's persistent state to stable storage, // where it can later be retrieved after a crash and restart. // see paper's Figure 2 for a description of what should be persistent. // func (rf *Raft) persist() { // Your code here (2C). // Example: // w := new(bytes.Buffer) // e := labgob.NewEncoder(w) // e.Encode(rf.xxx) // e.Encode(rf.yyy) // data := w.Bytes() // rf.persister.SaveRaftState(data) } // // restore previously persisted state. // func (rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } // Your code here (2C). // Example: // r := bytes.NewBuffer(data) // d := labgob.NewDecoder(r) // var xxx // var yyy // if d.Decode(&xxx) != nil || // d.Decode(&yyy) != nil { // error... // } else { // rf.xxx = xxx // rf.yyy = yyy // } } // // example RequestVote RPC arguments structure. // field names must start with capital letters! // type RequestVoteArgs struct { // Your data here (2A, 2B). Term int //candidate’s term CandidateId int //candidate requesting vote LastLogIndex int //index of candidate’s last log entry (§5.4) LastLogTerm int //term of candidate’s last log entry (§5.4) } // // example RequestVote RPC reply structure. // field names must start with capital letters! // type RequestVoteReply struct { // Your data here (2A). Term int //currentTerm, for candidate to update itself VoteGranted bool //true means candidate received vote } // // example RequestVote RPC handler. // func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (2A, 2B). rf.mu.Lock() defer rf.mu.Unlock() DPrintf("Candidate[raft%v][term:%v] request vote: raft%v[%v] 's term%v\n", args.CandidateId, args.Term, rf.me, rf.state, rf.currentTerm) reply.VoteGranted = false //Reply false if term < currentTerm if args.Term < rf.currentTerm { DPrintf("raft%v don't vote for raft%v\n", rf.me, args.CandidateId) reply.Term = rf.currentTerm reply.VoteGranted = false return } //If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.switchStateTo(Follower) } //If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote if rf.votedFor == -1 || rf.votedFor == args.CandidateId /*&& (rf.lastApplied == args.lastLogIndex && rf.log[rf.lastApplied].term == args.lastLogTerm) */ { DPrintf("raft%v vote for raft%v\n", rf.me, args.CandidateId) reply.VoteGranted = true rf.votedFor = args.CandidateId } reply.Term = rf.currentTerm rf.electionTimer.Reset(randTimeDuration()) } type AppendEntriesArgs struct { Term int //leader’s term LeaderId int //so follower can redirect clients PrevLogIndex int //index of log entry immediately preceding new ones PrevLogTerm int //term of prevLogIndex entry Entries []LogEntry //log entries to store (empty for heartbeat; may send more than one for efficiency) LeaderCommit int //leader’s commitIndex } type AppendEntriesReply struct { Term int //currentTerm, for leader to update itself Success bool //true if follower contained entry matching prevLogIndex and prevLogTerm } func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) { rf.mu.Lock() defer rf.mu.Unlock() DPrintf("leader[raft%v][term:%v] beat term:%v [raft%v][%v]\n", args.LeaderId, args.Term, rf.currentTerm, rf.me, rf.state) reply.Success = true if args.Term < rf.currentTerm { // Reply false if term < currentTerm (§5.1) reply.Success = false reply.Term = rf.currentTerm return } else if args.Term > rf.currentTerm { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.currentTerm = args.Term rf.switchStateTo(Follower) } rf.electionTimer.Reset(randTimeDuration()) } func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool { ok := rf.peers[server].Call("Raft.AppendEntries", args, reply) return ok } // // example code to send a RequestVote RPC to a server. // server is the index of the target server in rf.peers[]. // expects RPC arguments in args. // fills in *reply with RPC reply, so caller should // pass &reply. // the types of the args and reply passed to Call() must be // the same as the types of the arguments declared in the // handler function (including whether they are pointers). // // The labrpc package simulates a lossy network, in which servers // may be unreachable, and in which requests and replies may be lost. // Call() sends a request and waits for a reply. If a reply arrives // within a timeout interval, Call() returns true; otherwise // Call() returns false. Thus Call() may not return for a while. // A false return can be caused by a dead server, a live server that // can't be reached, a lost request, or a lost reply. // // Call() is guaranteed to return (perhaps after a delay) *except* if the // handler function on the server side does not return. Thus there // is no need to implement your own timeouts around Call(). // // look at the comments in ../labrpc/labrpc.go for more details. // // if you're having trouble getting RPC to work, check that you've // capitalized all field names in structs passed over RPC, and // that the caller passes the address of the reply struct with &, not // the struct itself. // func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool { ok := rf.peers[server].Call("Raft.RequestVote", args, reply) return ok } // // the service using Raft (e.g. a k/v server) wants to start // agreement on the next command to be appended to Raft's log. if this // server isn't the leader, returns false. otherwise start the // agreement and return immediately. there is no guarantee that this // command will ever be committed to the Raft log, since the leader // may fail or lose an election. even if the Raft instance has been killed, // this function should return gracefully. // // the first return value is the index that the command will appear at // if it's ever committed. the second return value is the current // term. the third return value is true if this server believes it is // the leader. // func (rf *Raft) Start(command interface{}) (int, int, bool) { index := -1 term := -1 isLeader := true // Your code here (2B). return index, term, isLeader } // // the tester calls Kill() when a Raft instance won't // be needed again. you are not required to do anything // in Kill(), but it might be convenient to (for example) // turn off debug output from this instance. // func (rf *Raft) Kill() { // Your code here, if desired. } // // the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. // func Make(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft { rf := &Raft{} rf.peers = peers rf.persister = persister rf.me = me // Your initialization code here (2A, 2B, 2C). DPrintf("create raft%v...", me) rf.state = Follower rf.currentTerm = 0 rf.votedFor = -1 rf.heartbeatTimer = time.NewTimer(HEART_BEAT_TIMEOUT * time.Millisecond) rf.electionTimer = time.NewTimer(randTimeDuration()) go func() { for { select { case <-rf.electionTimer.C: rf.mu.Lock() switch rf.state { case Follower: rf.switchStateTo(Candidate) case Candidate: rf.startElection() } rf.mu.Unlock() case <-rf.heartbeatTimer.C: rf.mu.Lock() if rf.state == Leader { rf.heartbeats() rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond) } rf.mu.Unlock() } } }() // initialize from state persisted before a crash rf.readPersist(persister.ReadRaftState()) return rf } //发送心跳包 func (rf *Raft) heartbeats() { for peer, _ := range rf.peers { if peer != rf.me { go func(peer int) { args := AppendEntriesArgs{} rf.mu.Lock() args.Term = rf.currentTerm args.LeaderId = rf.me rf.mu.Unlock() reply := AppendEntriesReply{} if rf.sendAppendEntries(peer, &args, &reply) { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.mu.Lock() if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.switchStateTo(Follower) } rf.mu.Unlock() } }(peer) } } time.Sleep(HEART_BEAT_TIMEOUT * time.Millisecond) } func randTimeDuration() time.Duration { return time.Duration(HEART_BEAT_TIMEOUT*3+rand.Intn(HEART_BEAT_TIMEOUT)) * time.Millisecond } //切换状态,调用者需要加锁 func (rf *Raft) switchStateTo(state int) { if state == rf.state { return } DPrintf("Term %d: server %d convert from %v to %v\n", rf.currentTerm, rf.me, rf.state, state) rf.state = state switch state { case Follower: rf.heartbeatTimer.Stop() rf.electionTimer.Reset(randTimeDuration()) rf.votedFor = -1 case Candidate: //成为候选人后立马进行选举 rf.startElection() case Leader: rf.electionTimer.Stop() rf.heartbeats() rf.heartbeatTimer.Reset(HEART_BEAT_TIMEOUT * time.Millisecond) } } func (rf *Raft) startElection() { // DPrintf("raft%v is starting election\n", rf.me) rf.currentTerm += 1 rf.votedFor = rf.me //vote for me rf.electionTimer.Reset(randTimeDuration()) rf.voteCount = 1 for peer, _ := range rf.peers { if peer != rf.me { go func(peer int) { rf.mu.Lock() args := RequestVoteArgs{} args.Term = rf.currentTerm args.CandidateId = rf.me // DPrintf("raft%v[%v] is sending RequestVote RPC to raft%v\n", rf.me, rf.state, peer) rf.mu.Unlock() reply := RequestVoteReply{} if rf.sendRequestVote(peer, &args, &reply) { rf.mu.Lock() if reply.VoteGranted && rf.state == Candidate { rf.voteCount += 1 if rf.voteCount > len(rf.peers)/2 { rf.switchStateTo(Leader) } } else if reply.Term > rf.currentTerm { //If RPC request or response contains term T > currentTerm:set currentTerm = T, convert to follower (§5.1) rf.currentTerm = reply.Term rf.switchStateTo(Follower) } rf.mu.Unlock() } else { // DPrintf("raft%v[%v] vote:raft%v no reply, currentTerm:%v\n", rf.me, rf.state, peer, rf.currentTerm) } }(peer) } } }
go test -race -run 2A

 浙公网安备 33010602011771号
浙公网安备 33010602011771号