

论文查重算法
| 这个作业属于哪个课程 | 信安1912 |
|---|---|
| 这个作业要求在哪里 | 个人项目要求 |
| 这个作业的目标 | 设计论文查重算法,学习PSP+单元测试+性能分析+git管理代码 |
Github链接:
https://github.com/mightbealie/3219005443
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 90 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 710 | 810 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 120 |
| · Design Spec | · 生成设计文档 | 40 | 30 |
| · Design Review | · 设计复审 | 40 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 90 | 80 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 100 |
| Reporting | 报告 | 50 | 70 |
| · Test Report | · 测试报告 | 20 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 850 | 970 |
模块接口的设计与实现过程
主模块
获取路径下文件内容,输出相似度
Analyse类
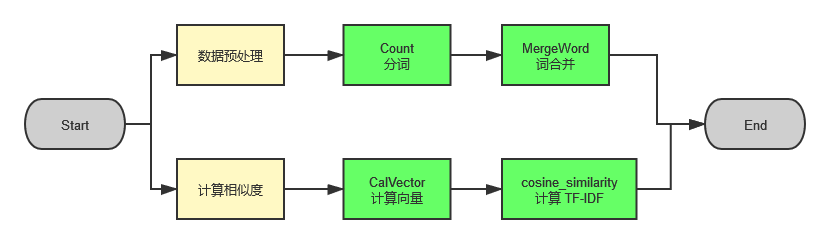
- TF-IDF
\[词频(TF)=\frac{某个词在文章中的出现次数}{该文出现次数最多的词的出现次数}
\]
\[逆文档频率(IDF)=\log\frac{语料库的文档总数}{包含该词的文档数+1}
\]
\[TF-IDF=\times{词频(TF)}{逆文档频率(IDF)}
\]
- jieba.analyse.textrank
jieba的具体用法
计算模块接口部分的性能改进
性能分析图
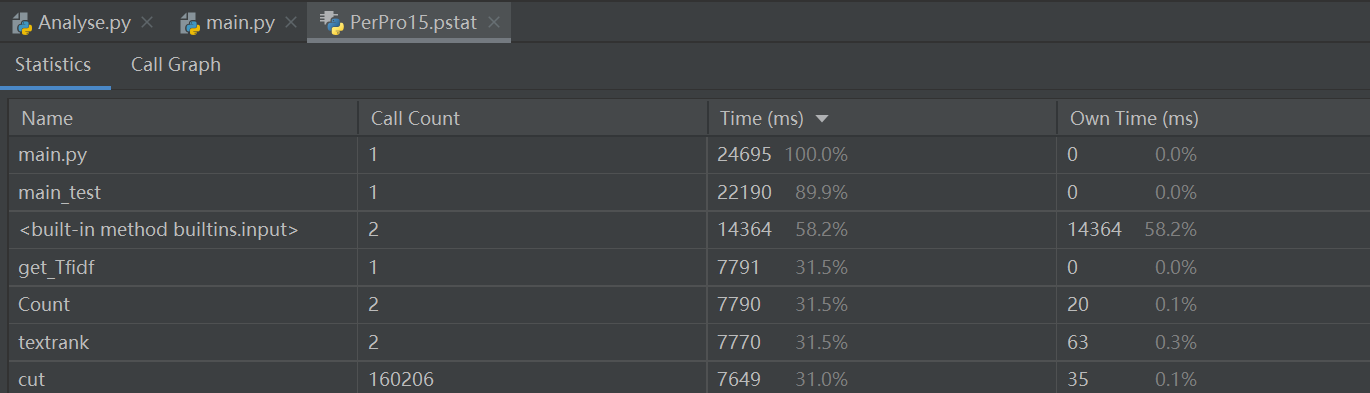
注意到答案输出中有这个问题,虽然不影响答案输出,但改进后可以使总体耗时降低

在import jieba库时加入以下这句
import jieba.analyse
jieba.setLogLevel(jieba.logging.INFO)
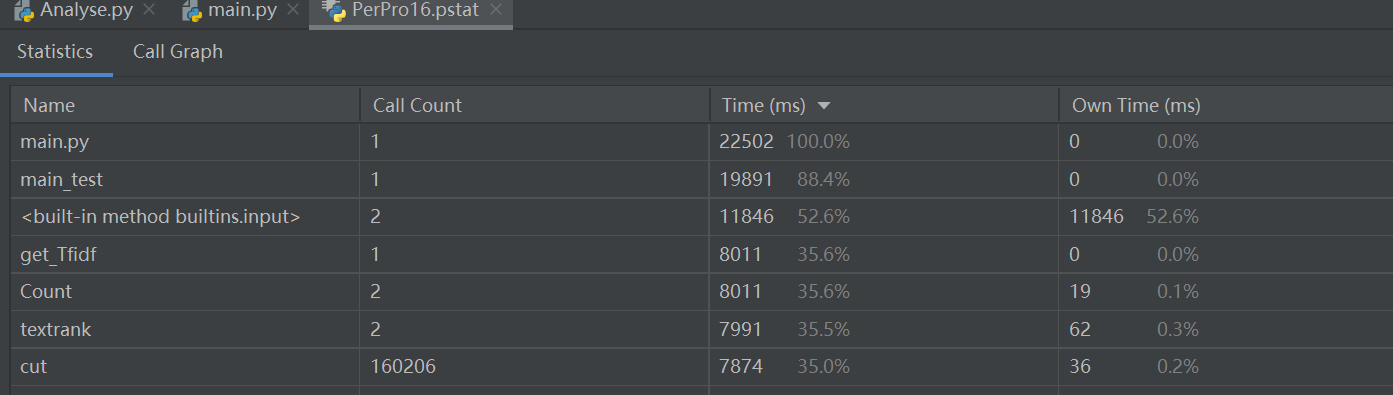
计算模块部分单元测试展示
单元测试结果

| 文本1 | 文本2 | 相似度 |
|---|---|---|
| orig.txt | orig_0.8_add.txt | 0.85 |
| orig.txt | orig_0.8_del.txt | 0.75 |
| orig.txt | orig_0.8_dis_1.txt | 0.90 |
| orig.txt | orig_0.8_dis_10.txt | 0.70 |
| orig.txt | orig_0.8_dis_15.txt | 0.65 |
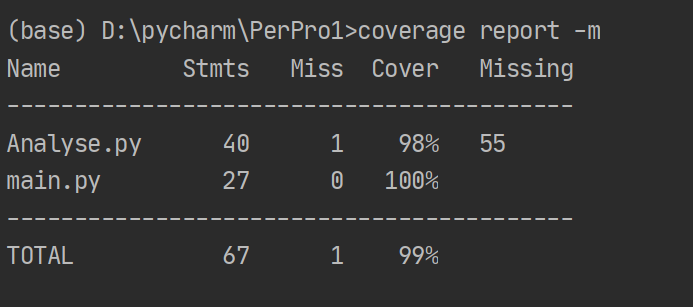
覆盖率
计算模块部分异常处理说明
如果在输入路径时输入错误,会导致程序错误运行。需要在开始计算前判断程序是否存在,若存在才继续计算,若不存在则结束程序。
- 引入 os.path.exists检查文件路径是否存在
- 在main_test中加入以下代码
if not os.path.exists(path1) :
print("论文原文文件不存在!")
exit()
if not os.path.exists(path2):
print("抄袭版论文文件不存在!")
exit()
自我总结
在这次项目完成中遇到了比较大的困难,由于在代码签入的过程中存在障碍,签入过程不太顺利,于是是在所有代码完成后一次性签入。
本次作业还是让我收获到了很多,比如学会了PSP,代码性能分析,覆盖率分析。

