组合数据类型,英文词频统计
总结列表,元组,字典,集合的联系与区别。
列表是可变的对象,可进行动态的增加、删除、更新,可以用list()函数或者[]创建。列表的元素不需要有相同的类型;使用索引来访问元素,元素是有序的,可重复。
元组和列表在结构上没有什么区别,唯一的差异在于元组是只读的,不能修改。元组用()或者tuple()函数来实现。
字典是存储键值对数据的对象,字典的元素都是无序的,且键不能相同,可以通过键,找到值,字典最外面用大括号,每一组用冒号连接起来。
集合相当于字典的键key,也是一个无序不重复的元素集,用一对{}表示。
列表,元组,字典,集合的遍历。
列表和元组:列表和元组都是有序的。列表是可变序列,元组是不可变序列;列表的值可以修改,而元祖的值初始化后不可修改。
集合和字典:两者都是无序的;数据量大时可用集合或列表来创建。
英文词频统计:
- 下载一首英文的歌词或文章str
- 分隔出一个一个的单词 list
- 统计每个单词出现的次数 dict
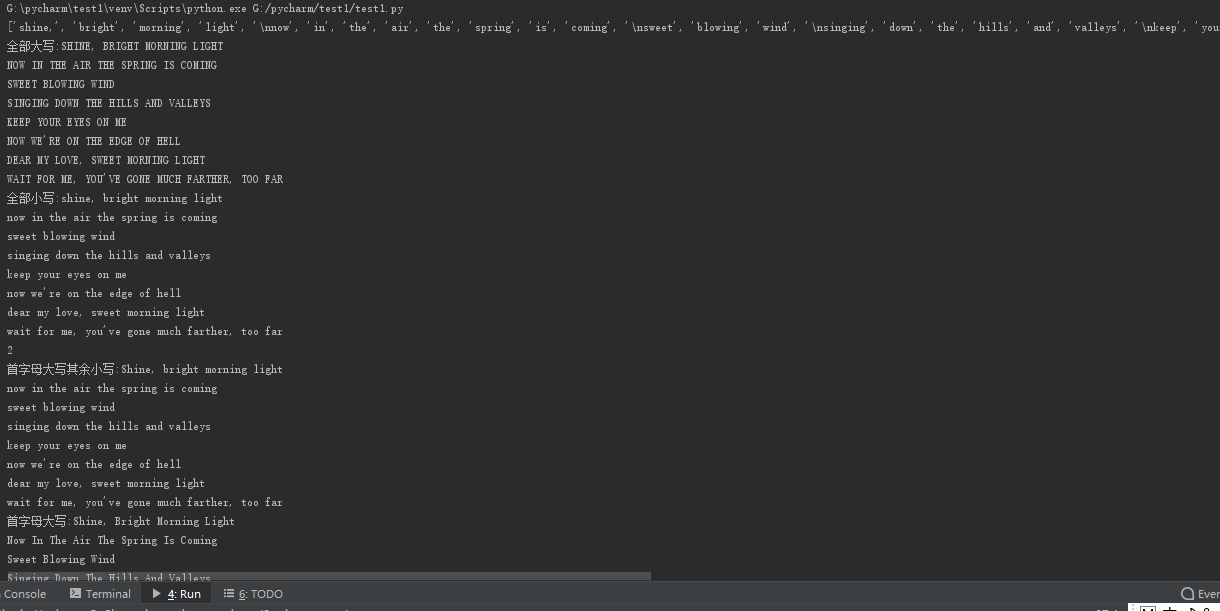
strBig=('''shine, bright morning light
now in the air the spring is coming
sweet blowing wind
singing down the hills and valleys
keep your eyes on me
now we're on the edge of hell
dear my love, sweet morning light
wait for me, you've gone much farther, too far ''')
strList=strBig.split(' ')
print(strList) #转化为列表
x1=str.upper(strBig)
print("全部大写:"+x1) #全部转化为大写
x2=str.lower(strBig)
print("全部小写:"+x2)
print(strBig.count('you'))
x3=str.capitalize(strBig)
print("首字母大写其余小写:"+x3)
x4=str.title(strBig)
print("首字母大写:"+x4)
x5=str.swapcase(strBig)
print("大小写互换:"+x5)
x6=max(strBig) ##max()
print(x6)
x7=min(strBig)
print(x7)
strSet=set(strList) ##字母出现的次数
for word in strSet:
print(word,strList.count(word))
运行结果:


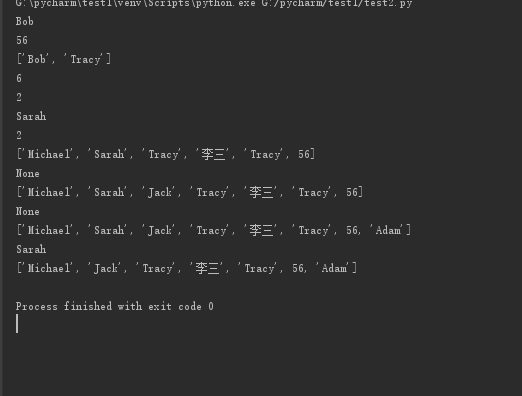
classmates=['Michael','Bob','Tracy','李三','Tracy',56]
a=classmates[1] ##取元素片段
print(a)
b=classmates[-1] ##取最后一个元素
print(b)
print(classmates[1:3]) ##取元素1:3
f=len(classmates) ##取属性
print(f)
c=classmates.index('Tracy') ##取元素的索引
print(c)
d=classmates[1]='Sarah' ##修改
print(d)
e=classmates.count('Tracy') ##计数
print(e)
print(classmates)
h=classmates.insert(2,"Jack") ##插入元素
print(h)
print(classmates)
i=classmates.append("Adam") ##追加元素
print(i)
print(classmates)
j=classmates.pop(1) ##删除元素
print(j)
print(classmates)
运行结果:
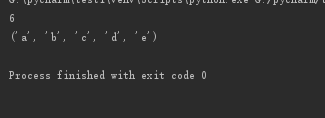
元组:
a=('Micheal','Bob','Tracy','李三','Tracy',56)
print(len(a)) ##取属性
b=tuple('abcde') ##元组
print(b)
运行结果:
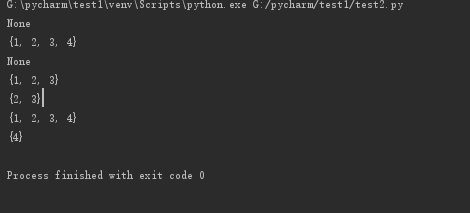
集合:
s={1,2,3}
a=s.add(4)
print(a)
print(s)
b=s.remove(4)
print(b)
print(s)
s=set([1,2,2,3,4])
s1=set([1,2,3])
s2=set([2,3,4])
g=s1 & s2 ##集合的交运算
print(g)
k=s1| s2 ##集合的并运算
print(k)
g=s2 - s1 ##集合的差运算
print(g)
运行结果:
字典:
classmates=['Michael','Bob','Tracy']
scores=[95,75,85]
d={'Bob':75,"Michael":95,'Tracy':85}
print(d['Michael']) ##取值
print(len(d)) ##元素个数
'Thomas' in d ##判断Thomas是否在d中
d['Rose']=88 ##添加与修改
print(d.pop('Bob')) ##删除
print(d.keys()) ##输出元素的键
print(d.values()) ##输出元素的值
print(d.items())
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号