scrapy 学习笔记(1)
scrapy 学习笔记
一、简介
最为python最富盛名之一的爬虫框架,当然要属scrapy了,优点就是高效,强大,缺点嘛或许是上手容易精通难。
之前没有系统的学习过,所以一直也就是使用requests+bs4自己搞一些简单的爬虫,相比较scrapy可能要简陋许多,之前之所以没有上手主要还是因为环境搭载的问题,记得大约是3年前接触的python,就听说了scrapy框架,但是搭建环境遇到各种坑,渐渐的放弃了,最近心血来潮想说再尝试一下,虽然也是各种坑,但是总算还是成功的弄好了环境。至于坑嘛,我遇到的感觉和网上查到的资料有出入。
1.1搭建环境
至于scrapy的环境嘛其实还是推荐使用linux系统来搭建,直接使用
sudo apt update
sudo apt install python3
pip intsall scrapy
作为各种系统都玩的我来说还是比较容易的,当然如果你使用的windows系统可以考虑使用虚拟机,如果不使用虚拟机安装linux系统,那么要记得使用windows的命令窗口来安装,之前我使用的是pycharm的终端来安装的,所以装了一百遍失败一百遍。
具体的当然先搭建好python3环境,具体的请自行百度,这里不赘述了,搭建好python3之后,我们就使用pip来安装scrapy
pip install scrapy -i https://mirrors.aliyun.com/pypi/simple
安装好之后使用scrapy来确认是否安装成功,成功就会出现如下菜单:
至此scrapy安装完成。
二、新建一个简单的爬虫项目
新建一个文件夹testspider,进入该文件夹,然后在终端窗口中输入如下命令:
scrapy startproject 项目名
这时候就会在该目录下生成“项目名” 文件夹和scrapy.cfg文件,然后cd到该文件夹里面执行“scrapy genspider example example.com”
scrapy genspider example example.com
example是爬虫名,example.com是将要爬取的入口网址,需要注意的是爬虫名字不能和项目名字一样,否则报错,接下来我们以电影天堂为例,爬去简单的电影列表,因此我们在项目文件夹里面输入
scrapy genspider dytt www.dytt8.net
这时候打开项目文件夹里面的spider文件夹,发现新建了一个叫做dytt.py的文件,内容如下:
# -*- coding: utf-8 -*-
import scrapy
class DyttSpider(scrapy.Spider):
name = 'dytt'
allowed_domains = ['www.dytt8.net'] # 这里是允许的域名
start_urls = ['http://www.dytt8.net'] # 这里是入口网址
def parse(self, response): # 这个是爬虫的主程序
pass
我们来尝试一下打开入口网址,然后我们爬去最新电影更新这个列表

我们将爬虫的主程序修改为如下:
# -*- coding: utf-8 -*-
import scrapy
class DyttSpider(scrapy.Spider):
name = 'dytt'
allowed_domains = ['www.dytt8.net']
start_urls = ['httpS://www.dytt8.net']
def parse(self, response):
new_list = response.xpath('//*[@id="header"]/div/div[3]/div[2]/div[1]/div/div[2]').extract() # 使用xpath定位到要找的节点
for n_item in new_list: #遍历循环
print(n_item) # 将结果打印出来
然后在命令终端输入
scrapy crawl dytt # crawl 爬虫名字 用来启动爬虫
然后得到如下结果:
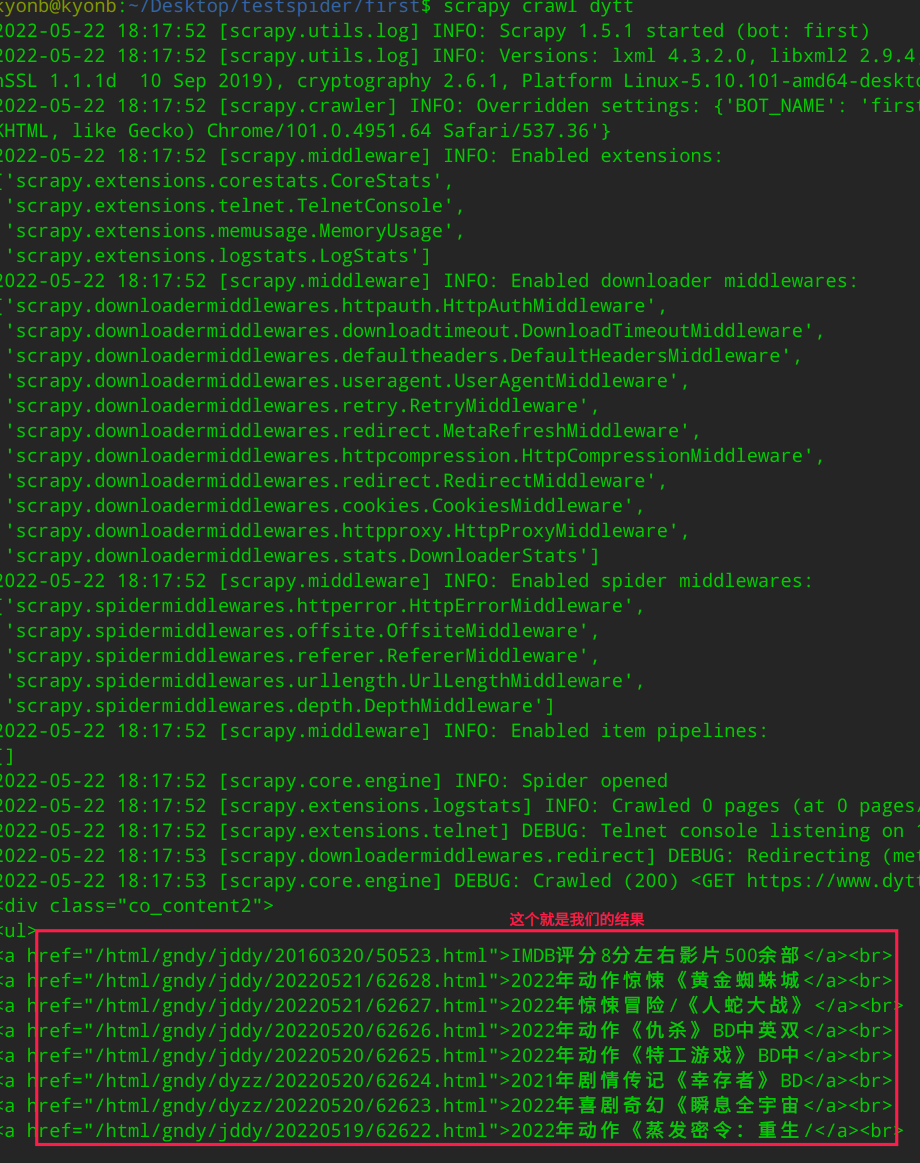
这样一个简单的爬虫就搞定了。

