Redis 数据库
1. 认识 redis
1.1 NoSQL 数据库
NoSQL (Not Only SQL)数据库即非关系型数据库,与关系型数据库区别:
- 表与表之间没有关联
- 不支持 SQL 语法,不支持事务
- 不擅长关系特别复杂的数据查询,但是速度快
- 以 key-value 形式存储数据
- NoSQL 中没有通用的语言,每种数据库都有自己的语法,以及擅长的业务场景
常见的 NoSQL有:Redis、MongoDB、Hbase hadoop 以及 Cassandra hadoop 等
NoSQL数据库的四大分类表格分析
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value)[3] | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。[3] | Key 指向 Value 的键值对,通常用hash table来实现[3] | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据[3] |
| 列存储数据库[3] | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库[3] | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库[3] | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。[3] |
1.2 Redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
优势
- 性能极高:Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型:Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 : Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性: Redis还支持 publish/subscribe, 通知, key 过期等等特性。
应用场景
- 用来做缓存(ehcache/memcached):edis的所有数据是放在内存中的(内存数据库)
- 可以在某些特定应用场景下替代传统数据库:比如社交类的应用
- 在一些大型系统中,巧妙地实现一些特定的功能:session共享、购物车
- redis 官网:https://redis.io/
- redis 中文网:http://redis.cn/
安装
sudo apt-get update
sudo apt-get install redis-server
redis-server # 启动 redis 服务
redis-cli # 查看 redis 是否在运行
pip3 install redis # Python 安装
常用命令
# 服务端
redis-server --help # 查看帮助文档
sudo service redis start # 启动服务
sudo service redis stop # 停止
sudo service redis restart # 重启
ps - ef |grep redis # 查看 redis 服务器进程
sudo kill -9 pid # 杀死 redis 服务器进程
sudo redis-server /etc/redis/redis.conf # 指定加载的配置文件
# 客户端
redis-cli --help # 查看帮助文档
redis-cli # 连接 redis
ping # 运行测试命令
select n # 切换数据库,数据库没有名称,默认16个,从 0-15,如:select 10
# 查看命令
help 命令
# 通过 apt-get 安装的
# 开启、关闭和重启 redis-server 服务
/etc/init.d/redis-server start
/etc/init.d/redis-server stop
/etc/init.d/redis-server restart
配置
Redis 的配置信息在 /etc/redis/redis.conf 中
核心配置选项:
# 绑定ip:如果需要远程访问,可将此⾏注释,或绑定⼀个真实ip
bind 127.0.0.1
# 端⼝,默认为6379
port 6379
# 是否以守护进程运⾏
# 如果以守护进程运⾏,则不会在命令⾏阻塞,类似于服务
# 如果以⾮守护进程运⾏,则当前终端被阻塞
# 设置为yes表示守护进程,设置为no表示⾮守护进程
# 推荐设置为yes
daemonize yes
# 数据⽂件
dbfilename dump.rdb
# 数据⽂件存储路径
dir /var/lib/redis
# ⽇志⽂件
logfile /var/log/redis/redis-server.log
# 数据库,默认有16个
database 16
# 主从复制,类似于双机备份。
slaveof
# 设置 Redis 连接密码,如果配置了连接密码,客户端在连接 Redis 时需要通过 AUTH <password> 命令提供密码,默认关闭
requirepass foobared
配置 redis 外网可访问
由于 redis 采用的安全策略,默认会只准许本地访问。需要通过简单配置,完成允许外网访问。
修改 redis 的配置文件,将所有 bind 信息全部屏蔽。2.8 版本以上还需要将 protected-mode 修改为 no
# bind 192.168.1.100 10.0.0.1
# bind 192.168.1.8
# bind 127.0.0.1
修改完成后,需要重新启动 redis 服务。
参考资料:
2. redis 存储数据结构
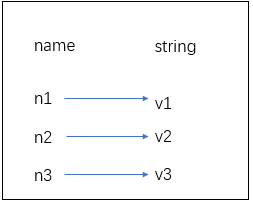
redis 以 key-value 存储数据,每条数据即一个键值对:
- 键:必须是字符串,不能重复
- 值:字符串、哈希(hash)、列表、集合(set)、有序集合(zset)
- 数据操作行为:保存、删除、修改以及获取
查询命令:http://redis.cn/commands.html
2.1 键命令
终端
keys * # 查看所有已存在的 key
keys 'a*' # 查看 key 中包含 a 的键 正则匹配
exists key1 # 查看键是否存在,存在返回 1,否则返回 0
type key # 查看键对应 value 的类型
del key1 key2 # 删除 key1、key2 及所对应的 value
expire key second # 设置过期时间
expire 'a1' 3 # 单位为 秒
ttl key # 查看有效时间,单位秒
Python 程序
exists(name)
delete(name)
type(name)
keys(pattern) # 正则
randomkey() # 随机获取一个
rename(src dst) # 重命名键,src 原,dst 新
dbsize() # 获取当前数据库中键的数目
expire(name, time) # 键超时时间,单位秒
ttl(name) # 获取键过期时间,单位秒,-1 永不过期
move(name, db) # 将键移到其他数据库
flushdb() # 删除当前选择数据库中的所有键
flushall() # 删除所有数据库中的所有键
2.2 字符串
字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等。在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
set(key, value, ex=None, px=None, nx=False, xx=False)
在 Redis中设置值,不存在则创建,存在则修改
参数:
- ex:过期时间(秒)
- px:过期时间(毫秒)
- nx:如果设置为True,则只有name不存在时,当前set操作才执行
- xx:如果设置为True,则只有name存在时,当前set操作才执行
set name rose
set name1 lila ex 3 # 超时 3s,3s后就为空
127.0.0.1:6379> set name tom nx # 存在的 key,设置失败
(nil)
127.0.0.1:6379> set name2 tom nx # 不存在的才能设置成功
OK
set name2 john nx # 替换已存在的键原来的值
setnx(name, value) # 等于 set name2 tom nx
setex(name, value, time) # 等于 set name1 lila ex 3
get(name)根据键获取值
get name
mset(*args, **kwargs)批量赋值
# 只有在 k1 和 k2 不存在的情况下才能赋值成功
mset(k1='v1', k2='v2')
mget({'k1': 'v1', 'k2': 'v2'})
psetex(name, time_ms, value)超时时间
psetex name3 3 jjjj
mget(keys, *args)批量获取
mget name name2
getset(name, value)设置新值并获取原来的值
getset name kdkdk
getrange(key, start, end)切片,start 和 end 为字节
# 从 0 开始,支持负索引,中文三个字节
127.0.0.1:6379> get name
"shshsh"
127.0.0.1:6379> getrange name 0 2
"shs"
127.0.0.1:6379> set name4 蜂蜜
OK
127.0.0.1:6379> getrange name4 0 3
"\xe8\x9c\x82\xe8"
setrange(name, offset, value)设置指定键的值得子字符串
# offset 为字节偏移量
127.0.0.1:6379> get name
"shshsh"
127.0.0.1:6379> setrange name 6 abc
(integer) 9
127.0.0.1:6379> get name
"shshshabc"
127.0.0.1:6379> setrange name 10 abc
(integer) 13
127.0.0.1:6379> get name
"shshshabc\x00abc"
setbit(name, offset, value)对 name 对应值的二进制表示的位进行操作
# setbit 是修改每个字符串所对应的 010101 中间的值
# 比如:foo 对应的是 01100110 01101111 01101111
# 将第 7 位修改为 1,则变为了 01100111 01101111 01101111 即 goo
127.0.0.1:6379> set n foo
OK
127.0.0.1:6379> setbit n 7 1
(integer) 0
127.0.0.1:6379> get n
"goo"
# 将字符串转换为 010101
s = 'foo'
for i in s:
n = ord(i)
print(bin(n).replace('b', ''))
示例
使用 setbit 实时统计网站访问人数,以及访问的用户名:
每个用户都有一个用户 ID,假设分别为:199 、299 、399...
127.0.0.1:6379> setbit usercount 199 1
(integer) 0
127.0.0.1:6379> setbit usercount 299 1
(integer) 0
127.0.0.1:6379> setbit usercount 399 1
(integer) 0
# 获取实际访问人数
127.0.0.1:6379> bitcount usercount
(integer) 3
# 也可以根据用户 ID,判断其是否登录
127.0.0.1:6379> getbit usercount 299
(integer) 1
优势:setbit 以 010101 二进制存储,占用空间小,redis 速度快,能够实时刷新。
getbit(name, offset)获取 name 对应的值的二进制表示中的某位的值 (0或1)
# goo:01100111 01101111 01101111
127.0.0.1:6379> get n
"goo"
127.0.0.1:6379> getbit n 7
(integer) 1
bitcount(key, start=None, end=None)获取name对应的值的二进制表示中 1 的个数
# goo:01100111 01101111 01101111
127.0.0.1:6379> bitcount n 0 -1
(integer) 17
strlen(name)返回name对应值的字节长度(一个汉字3个字节)
127.0.0.1:6379> strlen n
(integer) 3
incr(self, name, amount=1)自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增 1
# 已存在的 key
127.0.0.1:6379> set n1 2
OK
127.0.0.1:6379> incr n1
(integer) 3
127.0.0.1:6379> incr n1
(integer) 4
# 不存在的 key,设置初始值为 amount
127.0.0.1:6379> incr n2
(integer) 1
127.0.0.1:6379> get n2
"1"
incrbyfloat(self, name, amount=1.0)自增浮点数
127.0.0.1:6379> set n3 1.1
OK
127.0.0.1:6379> incrbyfloat n3 1.2
"2.3"
decr(self, name, amount=1)自减
127.0.0.1:6379> get n1
"4"
127.0.0.1:6379> decr n1
(integer) 3
append(key, value)在redis name对应的值后面追加内容
127.0.0.1:6379> get n
"goo"
127.0.0.1:6379> append n rose
(integer) 7
127.0.0.1:6379> get n
"goorose"
2.3 哈希
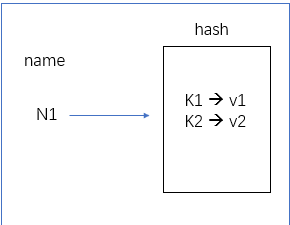
hset(name, key, value)name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
127.0.0.1:6379> hset rose age 18
(integer) 1
127.0.0.1:6379> hget rose age
"18"
hsetnx(name, key, value)当name对应的hash中不存在当前key时则创建(相当于添加)
# 对于已经存在的,不能设置
127.0.0.1:6379> hsetnx rose age 19
(integer) 0
127.0.0.1:6379> hget rose age
"18"
hmset(name, mapping)批量设置键值对
# mapping 映射字典
redis.hmset('price', {'apple': 12, 'banana': 6})
127.0.0.1:6379> hmset price apple 12 banana 6
OK
127.0.0.1:6379> hget price apple
"12"
hget(name,key)获取键为 name 的 hash中对应的 value
hget price apple
hmget(name, keys, *args)批量获取
127.0.0.1:6379> hmget price apple banana
1) "12"
2) "6"
hgetall(name)获取name对应hash的所有键值
127.0.0.1:6379> hgetall price
1) "apple"
2) "12"
3) "banana"
4) "6"
hlen(name)获取name对应的hash中键值对的个数
127.0.0.1:6379> hlen price
(integer) 2
hkeys(name)获取name对应的hash中所有的key的值
127.0.0.1:6379> hkeys price
1) "apple"
2) "banana"
hvals(name)获取name对应的hash中所有的value的值
127.0.0.1:6379> hvals price
1) "12"
2) "6"
hexists(name, key)检查name对应的hash是否存在,存在返回 1,否则返回 0
127.0.0.1:6379> hexists price apple
(integer) 1
127.0.0.1:6379> hexists price abc
(integer) 0
hdel(name,*keys)将name对应的hash中指定key的键值对删除,支持删除多个
127.0.0.1:6379> hdel price apple
(integer) 1
127.0.0.1:6379> hdel price apple banana
(integer) 1
hincrby(name, key, amount=1)自增name对应的hash中的指定key的值,不存在则创建 key=amount
127.0.0.1:6379> hincrby price apple 2
(integer) 2
127.0.0.1:6379> hincrby price apple 2
(integer) 4
127.0.0.1:6379> hget price apple
"4"
hincrbyfloat(name, key, amount=1.0)自增,浮点数
127.0.0.1:6379> hincrbyfloat price apple 1.2
"5.2"
hscan(name, cursor=0, match=None, count=None)增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
- name:redis的name
- cursor:游标(基于游标分批取获取数据)
- match:匹配指定key,默认None 表示所有的key
- count:每次分片最少获取个数,默认None表示采用Redis的默认分片个数
127.0.0.1:6379> hscan price1 6 match '*a*' count 2
1) "0"
2) 1) "apple1"
2) "12"
3) "banana1"
4) "6"
hscan_iter(name, match=None, count=None)利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
- match:匹配指定key,默认None 表示所有的key
- count:每次分片最少获取个数,默认None表示采用Redis的默认分片个数
print(r.hkeys('price1'))
print(list(r.hscan_iter('price1', match='*a*', count=1)))
for item in r.hscan_iter('price1', match='*a*', count=1):
print(item)
运行结果如下:
[b'apple1', b'banana1', b'dec', b'hfj']
[(b'apple1', b'12'), (b'banana1', b'6')]
(b'apple1', b'12')
(b'banana1', b'6')
2.4 列表
redis 中的 List 在在内存中按照一个 name 对应一个List来存储,如下图所示:

lpush(name,values)添加元素,被添加到最左边
127.0.0.1:6379> lpush a 11 22 33
(integer) 3
(0.97s)
127.0.0.1:6379> lrange a 0 -1
1) "33"
2) "22"
3) "11"
rpush(name, values)表示从右向左操作lpushx(name,value)在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
127.0.0.1:6379> lpushx a 456
(integer) 4
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "33"
3) "22"
4) "11"
# 不存在 name,添加失败
127.0.0.1:6379> lpushx b 1
(integer) 0
rpushx(name, value)表示从右向左操作llen(name)name对应的list元素的个数
127.0.0.1:6379> llen a
(integer) 4
linsert(name, where, refvalue, value))在name对应的列表的某一个值前或后插入一个新值
参数:
- name:redis的name
- where:BEFORE或AFTER
- refvalue:标杆值,即:在它前后插入数据
- value:要插入的数据
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "33"
3) "22"
4) "11"
# 在 33 前插入 44
127.0.0.1:6379> linsert a before 33 44
(integer) 5
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "44"
3) "33"
4) "22"
5) "11"
lset(name, index, value)对name对应的list中的某一个索引位置重新赋值
127.0.0.1:6379> lset a 1 55
OK
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "55"
3) "33"
4) "22"
5) "11"
r.lrem(name count value)在name对应的list中删除指定的值
参数:
- name:redis的name
- value:要删除的值
- count:num=0,删除列表中所有的指定值,要删除的个数
- count=2,从前到后,删除2个;
- count=-2,从后向前,删除2个
127.0.0.1:6379> linsert a before 33 55
(integer) 5
127.0.0.1:6379> linsert a before 33 55
(integer) 6
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "55"
3) "55"
4) "33"
5) "22"
6) "11"
127.0.0.1:6379> lrem a 2 55
(integer) 2
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "33"
3) "22"
4) "11"
lpop(name)在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
127.0.0.1:6379> lpop a
"456"
rpop(name)表示从右向左操作lindex(name, index)在name对应的列表中根据索引获取列表元素
127.0.0.1:6379> lrange a 0 -1
1) "33"
2) "22"
3) "11"
127.0.0.1:6379> lindex a 2
"11"
lrange(name, start, end)在name对应的列表分片获取数据,从 0 开始,最后一位为 -1
127.0.0.1:6379> lrange a 0 1
1) "33"
2) "22"
ltrim(name, start, end)在name对应的列表中移除没有在start-end索引之间的值
127.0.0.1:6379> lrange a 0 -1
1) "33"
2) "22"
3) "11"
# 移除没有在 0 - 1 之间的值
127.0.0.1:6379> ltrim a 0 1
OK
127.0.0.1:6379> lrange a 0 -1
1) "33"
2) "22"
rpoplpush(src, dst)从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
- src:要取数据的列表的name
- dst:要添加数据的列表的name
127.0.0.1:6379> lrange a 0 -1
1) "33"
2) "22"
127.0.0.1:6379> lpush b 123 456 789
(integer) 3
127.0.0.1:6379> rpoplpush a b
"22"
127.0.0.1:6379> lrange b 0 -1
1) "22"
2) "789"
3) "456"
4) "123"
blpop(keys, timeout)返回并删除名称为 keys 中的 list 中首个元素,若干列表为空,则一直阻塞等待
参数:
- keys:redis的name的集合
- timeout:超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
127.0.0.1:6379> lrange b 0 -1
1) "22"
2) "789"
3) "456"
4) "123"
127.0.0.1:6379> blpop b 0
1) "b"
2) "22"
127.0.0.1:6379> lrange b 0 -1
1) "789"
2) "456"
3) "123"
r.brpop(key [key ...] timeout)从右向左获取数据brpoplpush(src, dst, timeout=0)从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
- src:取出并要移除元素的列表对应的name
- dst:要插入元素的列表对应的name
- timeout:当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
127.0.0.1:6379> lrange b 0 -1
1) "789"
2) "456"
127.0.0.1:6379> lrange a 0 -1
1) "22"
127.0.0.1:6379> brpoplpush b a 0
"456"
127.0.0.1:6379> lrange b 0 -1
1) "789"
127.0.0.1:6379> lrange a 0 -1
1) "456"
2) "22"
2.5 集合
集合即不允许重复
sadd(name,values)name对应的集合中添加元素
127.0.0.1:6379> sadd s1 1 2 # 可以添加多个元素
(integer) 2
scard(name)获取name对应的集合中元素个数
127.0.0.1:6379> scard s1
(integer) 2
sdiff(keys, *args)返回给定集合的差集(即将两个集合所有元素合并在一起,去掉重复的,并保留左边不重复的,去掉右边不重复的)
127.0.0.1:6379> sadd s1 1 2
(integer) 2
127.0.0.1:6379> sadd s2 1 3 4
(integer) 3
127.0.0.1:6379> sdiff s1 s2
1) "2"
sdiffstore(dest, keys, *args)求差集并将差集保存到 dest 集合中
127.0.0.1:6379> sdiffstore s3 s1 s2
(integer) 1
127.0.0.1:6379> smembers s3
1) "2"
sinter(keys, *args)求交集(即两个集合重复的元素)
127.0.0.1:6379> smembers s1
1) "1"
2) "2"
127.0.0.1:6379> smembers s2
1) "1"
2) "3"
3) "4"
127.0.0.1:6379> sinter s1 s2
1) "1"
sinterstore(dest, keys, *args)求交集,并将其添加到 dest 中
127.0.0.1:6379> sinterstore s4 s1 s2
(integer) 1
127.0.0.1:6379> smembers s4
1) "1"
sismember(name, value)检查value是否是name对应的集合的成员(是则返回 1, 否则返回0)
127.0.0.1:6379> smembers s1
1) "1"
2) "2"
127.0.0.1:6379> sismember s1 1
(integer) 1
127.0.0.1:6379> sismember s1 3
(integer) 0
smembers(name)获取name对应的集合的所有成员
127.0.0.1:6379> smembers s1
1) "1"
2) "2"
smove(src, dst, value)将某个成员从一个集合中移动到另外一个集合
127.0.0.1:6379> smembers s1
1) "1"
2) "2"
127.0.0.1:6379> smembers s2
1) "1"
2) "3"
3) "4"
127.0.0.1:6379> smove s1 s2 2
(integer) 1
127.0.0.1:6379> smembers s2
1) "1"
2) "2"
3) "3"
4) "4"
spop(name)随机移除一个成员,并将其返回
127.0.0.1:6379> spop s2
"2"
srandmember(name, numbers)从name对应的集合中随机获取 numbers 个元素
127.0.0.1:6379> smembers s2
1) "1"
2) "3"
3) "4"
127.0.0.1:6379> srandmember s2
"1"
127.0.0.1:6379> srandmember s2 2
1) "4"
2) "1"
srem(name, values)在name对应的集合中删除某些值
127.0.0.1:6379> srem s2 3
(integer) 1
sunion(keys, *args)获取多一个name对应的集合的并集(即将两个集合中的所有元素合并在一起,去掉重复的,保留两个集合中都不重复的元素)
127.0.0.1:6379> smembers s1
1) "1"
2) "2"
3) "3"
4) "5"
5) "6"
127.0.0.1:6379> smembers s2
1) "1"
2) "4"
127.0.0.1:6379> sunion s1 s2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
sunionstore(dest,keys, *args)获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
127.0.0.1:6379> sunionstore s5 s1 s2
(integer) 6
127.0.0.1:6379> smembers s5
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
sscan(name, cursor=0, match=None, count=None)同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
127.0.0.1:6379> sadd s6 abc bcd fgf ac da 123
(integer) 6
127.0.0.1:6379> sscan s6 0 match '*a*'
1) "0"
2) 1) "abc"
2) "ac"
3) "da"
127.0.0.1:6379> sscan s6 0 match '*a*' count 1
1) "2"
2) 1) "abc"
127.0.0.1:6379> sscan s6 0 match '*a*' count 2
1) "2"
2) 1) "abc"
127.0.0.1:6379> sscan s6 0 match '*a*' count 3
1) "1"
2) 1) "abc"
2) "ac"
3) "da"
sscan_iter(name, match=None, count=None)迭代器
print(r.smembers('s6')) # {b'abc', b'ac', b'bcd', b'da', b'fgf', b'123'}
rets = r.sscan_iter('s6', match='*a*', count=2)
print(list(rets))
运行结果如下:
{b'bcd', b'ac', b'123', b'fgf', b'abc', b'da'}
[b'abc', b'ac', b'da']
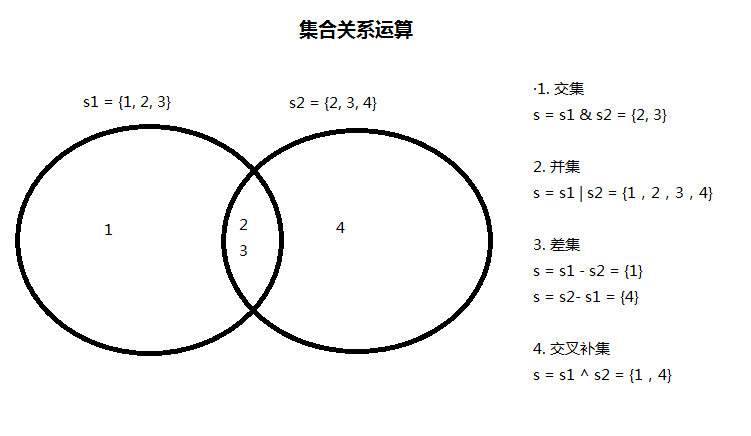
集合关系运算
- 差集:两个集合所有元素合并,去掉重复的,保留左边不重复的,去掉右边不重复的
- 交集:即两个集合重复的都有的元素
- 并集:两个集合所有元素合并,去掉重复的(重复的有两份,去掉一份),保留两个集合中不重复的
- 交叉补集:两个集合所有元素合并,去掉重复的,保留两个集合中不重复的元素
2.6 有序集合
比集合多个了一个分数字段(类似于权重),可以根据这个分数进程排序。
zadd(name, *args, **kwargs)在name对应的有序集合中添加元素
127.0.0.1:6379> zadd z1 100 rose 98 lila
(integer) 2
(0.94s)
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)获取name对应的有序集合元素的数量
127.0.0.1:6379> zcard z1
(integer) 2
zcount(name, min, max)获取name对应的有序集合中分数 在 [min,max] 之间的个数
127.0.0.1:6379> zcount z1 95 100
(integer) 2
zincrby(name, value, amount)自增name对应的有序集合的 name 对应的分数
127.0.0.1:6379> zincrby z1 -3 rose
"95"
127.0.0.1:6379> zscore z1 rose
"95"
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)按照索引范围获取name对应的有序集合的元素
参数:
- name,redis的name
- start,有序集合索引起始位置(非分数)
- end,有序集合索引结束位置(非分数)
- desc,排序规则,默认按照分数从小到大排序
- withscores,是否获取元素的分数,默认只获取元素的值
- score_cast_func,对分数进行数据转换的函数
# 默认从小到大排序
127.0.0.1:6379> zrange z1 0 -1
1) "rose"
2) "lila"
127.0.0.1:6379> zrange z1 0 -1 withscores
1) "d"
2) "95"
3) "e"
4) "96"
zrevrange(name, start, end, withscores=False, score_cast_func=float)从大到小排序
# 从大到小排序
127.0.0.1:6379> zrevrange z1 0 -1
1) "lila"
2) "rose"
zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)按照分数范围获取name对应的有序集合的元素
# 默认从小到大排序
127.0.0.1:6379> zrangebyscore z1 90 100
1) "rose"
2) "lila"
# 从大到小排序
127.0.0.1:6379> zrevrangebyscore z1 100 90
1) "lila"
2) "rose"
zrank(name, value)获取某个值在 name对应的有序集合中的排行(从 0 开始)
127.0.0.1:6379> zrank z1 rose
(integer) 0
# 从大到小排序 zrevrank(name, value)
127.0.0.1:6379> zrevrank z1 rose
(integer) 1
zrem(name, values)删除name对应的有序集合中值是values的成员
127.0.0.1:6379> zrem z1 rose
(integer) 1
# 也可以删除多个
zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)根据排行范围删除
# Linux 终端上是索引,不是分数,Python 程序里才是分数
127.0.0.1:6379> zremrangebyrank z1 0 2
(integer) 2
zremrangebyscore(name, min, max)根据分数范围删除
127.0.0.1:6379> zremrangebyscore z1 85 90
(integer) 2
zscore(name, value)获取name对应有序集合中 value 对应的分数
127.0.0.1:6379> zscore z1 tom
"95"
zinterstore(dest, keys, aggregate=None)获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作,(aggregate的值为: SUM MIN MAX),并将交集添加到 dest 中
# destination 交集放置到的集合,numkeys 指定 key 个数
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX]
127.0.0.1:6379> zadd z1 70 rose 80 lila
(integer) 2
127.0.0.1:6379> zadd z2 60 rose 58 lila
(integer) 2
# 默认求和
127.0.0.1:6379> zinterstore z3 2 z1 z2
(integer) 2
127.0.0.1:6379> zrange z3 0 -1 withscores
1) "rose"
2) "130"
3) "lila"
4) "138"
# 最小值
127.0.0.1:6379> zinterstore z3 2 z1 z2 aggregate MIN
(integer) 2
127.0.0.1:6379> zrange z3 0 -1 withscores
1) "lila"
2) "58"
3) "rose"
4) "60"
zunionstore(dest, keys, aggregate=None)获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作(aggregate的值为: SUM MIN MAX)
127.0.0.1:6379> zunionstore z4 2 z1 z2
(integer) 2
127.0.0.1:6379> zrange z4 0 -1 withscores
1) "rose"
2) "130"
3) "lila"
4) "138"
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)用于迭代有序集合中的元素(包括元素成员和元素分值)
127.0.0.1:6379> zscan z4 0 match 'r*'
1) "0"
2) 1) "rose"
2) "130"
zscan_iter(name, match=None, count=None,score_cast_func=float)迭代器
ret2 = r.zscan_iter('z4', match='r*')
print(ret2)
print(list(ret2))
运行结果如下:
<generator object Redis.zscan_iter at 0x00000292BB3A1DB0>
[(b'rose', 130.0)]
3. 管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
通过管道操作 redis,其目的是未了减少连接操作。
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='192.168.21.128', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'rose')
pipe.set('age', 18)
pipe.execute()
4. 订阅
s1.py
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='192.168.21.128')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()
pub.subscribe(self.chan_sub)
pub.parse_response()
return pub
订阅者:
from s1 import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg = redis_sub.parse_response()
print(msg)
发布者:
from s1 import RedisHelper
obj = RedisHelper()
obj.public('hello')
运行结果如下:
# 订阅者接收到信息
[b'message', b'fm104.5', b'hello']
5. Redis-py 连接 Redis
redis-py 库提供两个类 Redis 和 StrictRedis 来实现 redis 连接,及命令操作,官方推荐使用 StrictRedis。
import redis
# r = redis.Redis(host='192.168.21.128', port=6379)
r = redis.StrictRedis(host='192.168.21.128', port=6379, db=0)
r.set('name', 'rose')
redis 默认 password 为 None,要设置密码需要配置 /etc/redis/redis.conf 中的 requirepass foobared(记得重启服务)。
6. Django 存储 session
之前我们都是将 session 存储在 SQLite 中,我们还可以将 session 存储到 redis 中。
pip install django-redis-sessions==0.5.6
修改settings文件,增加如下项
SESSION_ENGINE = 'redis_sessions.session'
SESSION_REDIS_HOST = 'localhost' # 可以修改为远程 redis,如:192.168.xxx.xxx
SESSION_REDIS_PORT = 6379
SESSION_REDIS_DB = 2
SESSION_REDIS_PASSWORD = ''
SESSION_REDIS_PREFIX = 'session'
测试
urls.py
path('session_set/', views.session_set, name='session_set'),
path('session_get/', views.session_get, name='session_set'),
views.py
from django.shortcuts import render, HttpResponse
def session_set(request):
request.session['name'] = 'itheima'
return HttpResponse('ok')
def session_get(request):
name = request.session['name']
return HttpResponse(name)
访问 http://127.0.0.1:8000/session_set/,打开 redis 客户端,执行:
127.0.0.1:6379> select 2 # 选择数据库 2
127.0.0.1:6379> keys *
1) "session:44db715ia7026rfd38rp6vtppn5h1r4n"
127.0.0.1:6379> get session
(nil)
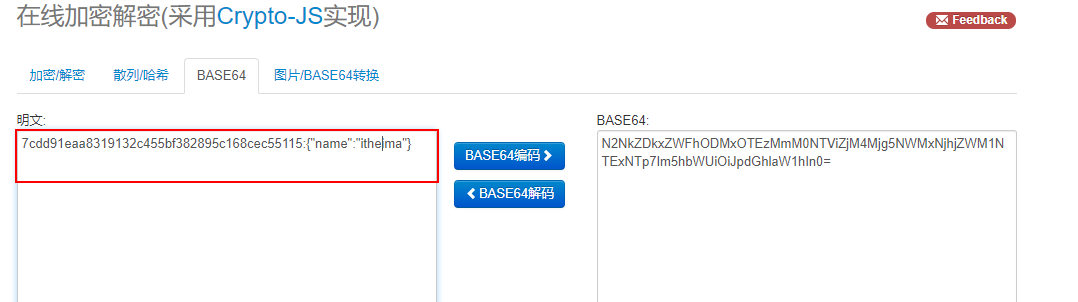
127.0.0.1:6379> get session:44db715ia7026rfd38rp6vtppn5h1r4n
"N2NkZDkxZWFhODMxOTEzMmM0NTViZjM4Mjg5NWMxNjhjZWM1NTExNTp7Im5hbWUiOiJpdGhlaW1hIn0="
http://tool.oschina.net/encrypt?type=3 解码查看:
7. RedisDump
RedisDump 是一个用于 Redis 数据导入/导出的工具,基于 Ruby 实现,所以需要先安装 Ruby
- Ruby 官网:http://www.ruby-lang.org/zh_cn/documentation/installation/#apt
- RedisDump:https://github.com/delano/redis-dump
$ sudo apt-get install ruby-full # 安装 redis Ubuntu 系统
gem install redis-dump # 安装 redis-dump
# 验证安装,如果成功调用,即安装成功
redis-dump
redis-load
踩坑
执行 gem install redis-dump 出现:You don't have write permissions for the /var/lib/gems/2.5.0 directory. 错误。
原因:没有写权限
解决办法:添加相应权限
sudo chmod 777 /var/lib/gems/2.5.0
sudo chmod 777 /usr/local/bin/
7.1 redis-dump
用于导出数据
查看命令选项:
hj@hj:/$ redis-dump -h
Try: /usr/local/bin/redis-dump show-commands
Usage: /usr/local/bin/redis-dump [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-c, --count=S Chunk size (default: 10000)
-f, --filter=S Filter selected keys (passed directly to redis' KEYS command)
-b, --base64 Encode key values as base64 (useful for binary values)
-O, --without_optimizations Disable run time optimizations
-V, --version Display version
-D, --debug
--nosafe
参数:
- u:redis 连接字符串
- d:数据库代号
- s:代表导出之后的休眠时间
- c:代表分块大小,默认 10000
- f:导出时过滤器
- O:禁用运行时优化
- V:版本
- D:开启调试
# 连接
hj@hj:/$ redis-dump -u localhost:6379 # 没有密码
hj@hj:/$ redis-dump -u :foobare@localhost:6379 # 有密码
执行上面命令,会将 0 -15 号总共16个数据库的所有数据打印出来。
每条数据包含 6 个字段:db(数据库代号)、key(键名)、ttl(键过期时间,-1永不过期)、type(键值类型)、value(内容)、size(占用空间)。
数据导出(json 格式):
# 导出到桌面,文件:redis_data.jl
# 全部导出
sudo redis-dump -u localhost:6379 > /home/hj/桌面/redis_data.jl
# 导出指定数据库(-d 参数)
sudo redis-dump -u localhost:6379 -d 1> /home/hj/桌面/redis_data.jl
# 导出特定内容(-f 参数,以 adsl 开头的数据,即 keys 命令的参数
sudo redis-dump -u localhost:6379 -f adsl:*> /home/hj/桌面/redis_data.jl
7.2 redis-load
导入 JSON 数据
hj@hj:/$ redis-load -h
Try: /usr/local/bin/redis-load show-commands
Usage: /usr/local/bin/redis-load [global options] COMMAND [command options]
-u, --uri=S Redis URI (e.g. redis://hostname[:port])
-d, --database=S Redis database (e.g. -d 15)
-a, --password=S Redis password (e.g. -a 'my@pass/word')
-s, --sleep=S Sleep for S seconds after dumping (for debugging)
-b, --base64 Decode key values from base64 (used with redis-dump -b)
-n, --no_check_utf8
-V, --version Display version
-D, --debug
--nosafe
参数:
- u:redis 连接字符串
- d:数据库代号
- s:导出之后休眠时间
- n:表示不检测 UTF-8 编码
- V:版本
- D:开启调试
# 导入 json 数据,两者效果相同
< redis_data.json redis-load -u :foobared@localhost:6379
cat redis_data.json | redis.load -u :foobared@localhost:6379

 浙公网安备 33010602011771号
浙公网安备 33010602011771号